Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
We started this project with a simple assumption. Solving a maze is an easy task. If you enter a maze and place your hand on one wall of the maze and traverse the maze without ever removing your hand you’ll reach the exit. What happens though if the maze is… dynamic? How would you solve a maze that shifts and changes? The problem is itself intractable. There is no guaranteed way to solve such a maze, but fundamentally we believe that a brute force algorithm is a poor solution to the problem and with the possibility of cycles arising in such a maze; sometimes not a solution at all. We believe that in a dynamic maze it is possible to come up with a solution that given an infinite amount of time, can solve the maze by using knowledge about the structure of the maze as a whole.
This problem essentially is a simplification of a much more complicated problem in robotics: given a starting point and a known endpoint with an unknown location in an unknown environment, navigate from point A to point B with the added complication that the environment itself is not consistent. Think something comparable to a delivery robot being dropped off at an active construction site. There is no time to stop construction to allow the robot to scan and build a map of the site. There are going to be constantly moving vehicles and materials around the site. A worker tells the robot to go to the manager’s office and gives the robot some description to identify it. The robot must get from where it is to the office despite the scenario it is placed in. This is essentially the problem we are solving.
Problem: Develop an algorithm to autonomously navigate and solve a dynamically changing maze.
Explore the maze and build a representation of it as a graph data structure with intersections as nodes and distances between them as edges
Create a navigation system based on this graph representation to travel effectively around the maze, updating the graph as changes are detected in real-time. Essentially developing our own SLAM algorithm. (SLAM being an algorithm than automates navigation based on a known map)
A Helpful Resource for Overall Maze Methodology: https://www.pololu.com/file/0J195/line-maze-algorithm.pdf
Some Help With Tuning Your PID: https://www.crossco.com/resources/technical/how-to-tune-pid-loops/
Lidar Methodology: https://github.com/ssscassio/ros-wall-follower-2-wheeled-robot/blob/master/report/Wall-following-algorithm-for-reactive%20autonomous-mobile-robot-with-laser-scanner-sensor.pdf
Use: All that is needed to use the code is to clone the github repository and put your robot in a maze!
From a birds eye view, the solution we came up with to solve a dynamic maze mirrors a very interesting problem in graph algorithms. With the assumption that the key to our solution lies in building an understanding of the structure of the maze as a whole, we build a map on the fly as we traverse the maze. We represent the maze as a graph data structure, labeling each intersection in the maze we reach as a node and each edge as the distance between these intersections in the maze. We create these nodes and edges as we encounter them in our exploration and delete nodes and edges as we come across changes in the maze. This problem can then be seen in actuality as a graph algorithms problem. Essentially we are running a graph search for a node with an unknown entry point into an unknown graph that itself is unreliable or rather, “live” and subject to modification as it is read. There are then 2 stages to solving this problem. The first is learning the graph for what it is as we explore, or rather create a full picture of the graph. Once we have explored everything and have not found the exit we know searching for the exit is now the problem of searching for change. The crux of solving this problem is characterizing the changes themselves. It is by understanding how changes take place that we devise our graph search from here to find these changes. For example, a graph whose changes occur randomly with equal probability of change at each node would have an efficient search solution of identifying the shortest non cyclical path that covers the most amount of nodes. The change behavior we used for our problem was that changes happen at certain nodes repeatedly. To solve the maze, we then use the previous solution of searching the most nodes as quickly as possible for changes if we fully explore the maze without identifying anything, then once a changing node is found we label it as such so we can check it again later, repeating these checks until new routes in the maze open up.
As a note, some simplifications that we use for time’s sake: Width of corridors in the maze are fixed to .5m Turns with always be at right angles
We designed an intelligent maze-solving robot navigation system that employs a depth-first search (DFS) algorithm for effective graph traversal. Our solution is structured into two primary components: laserutils and pid_explore, which work together seamlessly to facilitate the robot's navigation and exploration within the maze.
The laserutils module is a collection of essential utility functions for processing laser scan data and assisting in navigation. It calculates direction averages, simplifies 90-degree vision frameworks, detects intersections, and implements a PID controller to maintain a straight path. Moreover, it incorporates functions for converting yaw values, managing node formatting, and handling graph data structures, ensuring a streamlined approach to processing and decision-making.
The pid_explore module serves as the core of the robot's navigation system. It subscribes to laser scan and odometry data and employs the laserutils functions for efficient data processing and informed decision-making. The robot operates in three well-defined states: "explore," "intersection," and "position," each contributing to a smooth and strategic navigation experience.
In the "explore" state, the robot uses the PID controller to navigate straight, unless it encounters an intersection, prompting a transition to the "intersection" state. Here, the robot intelligently labels the intersection, assesses the path's continuation, and determines its next move. If the robot is required to turn, it shifts to the "position" state, where it identifies the turn direction (left or right) and completes the maneuver before resuming its straight path.
Our navigation system employs a Graph class to store and manage the maze's structure, leveraging the power of the DFS algorithm to find the optimal path through the maze. The result is a sophisticated and efficient maze-solving robot that strategically navigates its environment, avoiding any semblance of brute force in its problem-solving approach.
We built this project to address the challenges faced by robots in navigating unpredictable and dynamic environments, such as active construction sites or disaster zones. Traditional maze-solving algorithms, based on brute force and heuristics, are inadequate in such situations due to the constantly changing nature of the environment.
Our goal was to develop an intelligent navigation system that could adapt to these changes in real-time and continue to find optimal paths despite the uncertainties. By creating a program that can autonomously drive a robot through a changing maze, we aimed to advance robotic navigation capabilities and make it more efficient and useful in a wide range of applications.
With our innovative approach of "on the fly" map creation and navigation, we sought to enable robots to traverse dynamic spaces with minimal prior knowledge, making them more versatile and valuable in industries that require real-time adaptability. By simultaneously building and updating the map as the robot navigates, we ensured that the robot could rely on its current understanding of the environment to make informed decisions.
Ultimately, we built this project to push the boundaries of robotic navigation, opening up new possibilities for robots to operate in complex, ever-changing environments, and offering solutions to a variety of real-world challenges.
The project began our first week with a theoretical hashing out of how to approach the problem and what simplifications to make. We started by learning how to build simulations in Gazebo and implementing our Lidar methods. We then were able to create simple demos of an initial explore algorithm we created with the “explore”, “intersection”, “position” approach. Gazebo issues were encountered early on and were largely persistent throughout the course of the project with walls losing their physics upon world resets. At this point we built larger models in Gazebo to test with and implemented a PID algorithm to smooth the robot’s traversal. This PID would go through several versions as the project went on especially as we tuned navigation to be more precise as we adjusted our hall width from 1 meter down to .5. We then formulated and integrated our graph data structure and implemented a DFS algorithm to automatically find paths from node to node to navigate. We then added node labeling and cycle detection to our graph to recognize previously visited nodes. One of our group member’s github became permanently disconnected from our dev environment in the last stage of the process but all challenges are meant to be overcome. We finished by accounting for dynamic change in our algorithm and designed a demo.
Despite having trouble in our Gazebo simulations we were surprised to see that our algorithm worked well when we moved our tests over to the physical robots. PID especially, which had proven to be trouble in our testing in fact worked better in the real world than in simulations. There were a few corners cut in robustness (ie: with the simplifications agreed upon such as only right angle turns), but overall the final product is very adaptable within these constraints and accounts for a number of edge cases. Some of the potential improvements we would have liked to make is to expand past these simplifications of only having right-angled intersections and limited hall width. The prior would greatly change the way we would have to detect and encode intersections for the graph. A next algorithmic step could be having two robots traverse the maze from different points at the same time and sharing information between each other. This would be the equivalent of running two concurrent pointers in the graph algorithm. Overall, though an initially simple project on the surface, we believe that the significance of this problem as a graph algorithms problem not only makes it an important subject in robotics (maze traversal) but also an unexplored problem in the larger world of computer science; searching an unreliable/live modifying graph.
Efficiently search our graph for the exit to the maze its dynamic property making the graph unreliable
Entity Used for Consulting: https://chat.openai.com
laserUtils.py
Process Lidar Data
pid_explore.py
Navigating Maze
Naimul Hasan (naimulhasan@brandeis.edu | LinkedIn) Jimmy Kong (jameskong@brandeis.edu | LinkedIn) Brandon J. Lacy (blacy@brandeis.edu | LinkedIn)
May 5, 2023
“You can’t be an expert in everything. Nobody’s brain is big enough.” A quote that’s been stated by Pito at least twice this semester and once last semester in his software entrepreneurship course, but one that hadn’t truly sunk in until the time in which I, Brandon, sat down to write this report with my teammates, Naimul and Jimmy.
I’ve greatly enjoyed the time spent on group projects within my professional experiences, but always erred on the side of caution with group work in college as there’s a much higher chance an individual won’t pull their weight. It’s that fear of lackluster performance from the other team members that has always driven me to want to work independently. I’d always ask myself, “What is there to lose when you work alone?
You’ll grow your technical expertise horizontally and vertically in route to bolster your resume to land that job you’ve always wanted, nevermind the removal of all of those headaches that come from the incorporation of others. There is nothing to lose, right?”
Wrong.
You lose out on the possibility that the individuals you could’ve partnered with are good people, with strong technical skills that would’ve made your life a whole lot easier throughout the semester through the separation of duties. You lose out on a lot of laughs and the opportunity to make new friends.
Most importantly, however, you lose out on the chance of being partnered with individuals who are experts in areas which are completely foreign to you.There is nobody to counter your weaknesses. You can’t be an expert in everything, but you can most certainly take the gamble to partner with individuals to collectively form one big brain full of expertise to accomplish a project of the magnitude in which we’ve accomplished this semester.
I know my brain certainly wasn’t big enough to accomplish this project on my own. I’m grateful these two men reached out to me with interest in this project. Collectively, we’ve set the foundation for future iterations of the development of campus rover and we think that’s pretty special considering the long term impact beyond the scope of this course. So, I guess Pito was right after all; one brain certainly isn’t big enough to carry a project, but multiple brains that each contribute different areas of expertise. Now that’s a recipe for success.
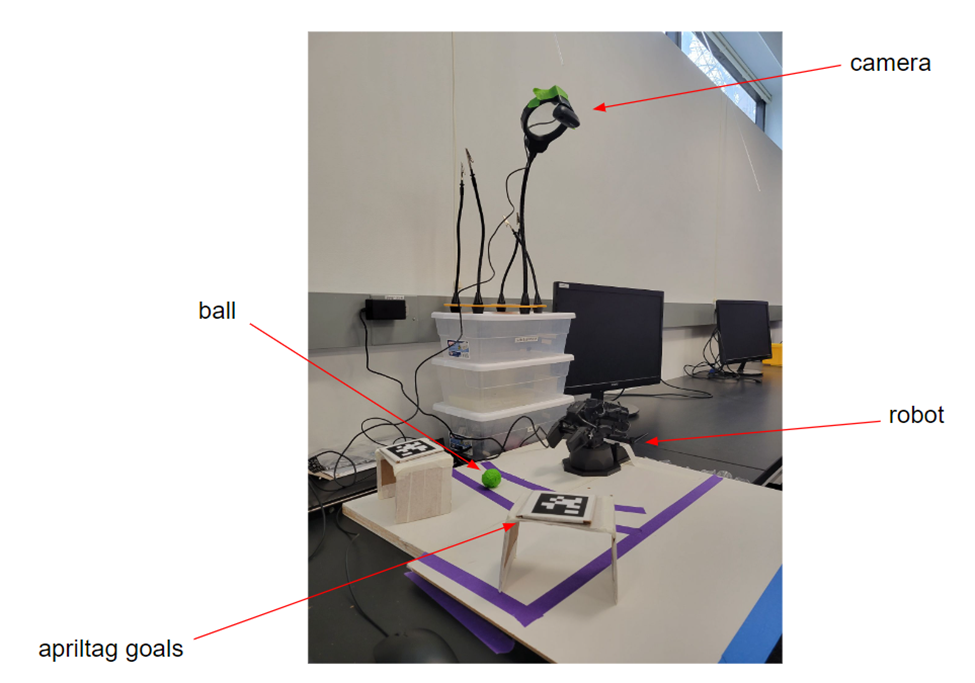
The command and control dashboard, otherwise known as the campus rover dashboard, is a critical component to the development of the campus rover project at Brandeis University as it’s the medium in which remote control will take place between the operator and the robot. It is the culmination of three components: a web client, robot, and GPS. Each component is a separate entity within the system which leverages the inter-process communications model of ROS to effectively transmit data in messages through various nodes. There are various directions in which the campus rover project can progress, whether it be a tour guide for prospective students or a package delivery service amongst faculty. The intention of our team was to allow the command and control dashboard to serve as the foundation for future development regardless of the direction enacted upon in the future.
The front-end and back-end of our web client is built with React.js. The app.js file is used to manage routes and some React-Bootstrap for the creation of certain components, such as buttons. The code structure is as follows: app.js contains the header, body, and footer components. The header component hosts the web client’s top-most part of the dashboard which includes the name of the application with links to the different pages. The footer component hosts the web-client’s bottom-most part of the dashboard which includes the name of each team member. The body component is the meat of the application which contains the routes that direct the users to the various pages. These routes are as follows: about, help, home, and settings. Each of these pages utilize components that are created and housed within the rosbridge folder. You can think of them as parts of the page such as the joystick or the video feed. The ros_congig file serves as the location for default values for the settings configurations. We use local storage to save these settings values and prioritize them over the default values if they exist.
ROSBridge is a package for the Robot Operating System (ROS) that provides a JSON-based interface for interacting with ROS through WebSocket protocol (usually through TCP). It allows external applications to communicate with ROS over the web without using the native ROS communication protocol, making it easier to create web-based interfaces for ROS-based robots. ROSLIBJS is a JavaScript library that enables web applications to communicate with ROSBridge, providing a simple API for interacting with ROS. It allows developers to write web applications that can send and receive messages, subscribe to topics, and call ROS services over websockets. ROSBridge acts as a bridge between the web application and the ROS system. It listens for incoming WebSocket connections and translates JSON messages to ROS messages, and the other way around. ROSLIBJS, on the other hand, provides an API for web applications to interact with ROSBridge, making it easy to send and receive ROS messages, subscribe to topics, and call services. In a typical application utilizing ROSBridge and ROSLIBJS, it would have the following flow:
Web client uses ROSLIBJS to establish a WebSocket connection to the ROSBridge server, through specifying a specific IP address and port number.
The web client sends JSON messages to ROSBridge, which converts them to ROS messages and forwards them to the appropriate ROS nodes.
If the node has a reply, the ROS nodes send messages back to ROSBridge, which converts them to JSON and sends them over the WebSocket connection to the web client.
ROSLIBJS API processes the incoming JSON messages so it can be displayed/utilized to the web client
GPS, or Global Positioning System, is a widely-used technology that enables precise location tracking and navigation anywhere in the world through trilateration, a process which determines the receiver’s position by measuring the distance between it and several satellites. Though it has revolutionized the way we navigate and track objects, its accuracy can vary depending on a variety of factors that are beyond the scope of this paper. However, there are various companies which have embraced the challenge of a more accurate navigation system that incorporates other data points into the algorithm responsible for the determination of the receiver position. Apple is notorious for the pin-point accuracy available within their devices which incorporate other sources such as nearby Wi-Fi networks and cell towers to improve its accuracy and speed up location fixes. The utilization of a more sophisticated location technology is critical for this project to be able to navigate routes within our university campus. Therefore, we’ve chosen to leverage an iPhone 11 Pro placed on our robot with the iOS application GPS2IP open to leverage the technology available in Apple’s devices to track our robot’s movement.
GPS2IP is an iOS application that transforms an iPhone or iPad into a wireless GPS transmitter over the network. It possesses various features such as high configurability, background operation on the iPhone, and standard NMEA message protocols. There is a free lite version available for testing and system verification as well as a paid version with all available features.
Nodes
/gps
The node’s purpose is to listen to GPS2IP through a socket and publish the data as a gps topic. The GPS2IP iOS application provides the functionality of a portable, highly sophisticated, GPS receiver that provides a very accurate location when the iPhone is placed on the robot. The GPS data is sent as a GLL NMEA message from a given IP address and corresponding port number. The /gps node leverages the socked package in Python to listen to the messages published at that previously emphasized IP address and port number. Through this connection, a stream of GLL messages can be received, parsed, and transformed into the correct format to be interpreted by the web client. The main transformation is for the latitude and longitude from decimal and minutes to decimal degrees format. The node will publish continuously until the connection through the socket is disturbed. The topic has a data type of type String, which is a serialized version of JSON through the utilization of the json package to dump the Python dictionary.
Code
img_res
The node’s purpose is to alter the quality of the image through a change in resolution. It’s done through the utilization of the OpenCV package, CV2, and cv_bridge in Python. The cv_bridge package, which contains the CvBridge() object, allows for seamless conversion from a ROS CompressedImage to a CV2 image and vice versa. There are two different camera topics that can be subscribed to depending upon the hardware configuration, /camera/rgb/image/compressed or /raspicam_node/image/compressed. Additionally, the /image_configs topic is subscribed to to receive the specifications for the resolution from the web client. A new camera topic is published with the altered image under the topic name /camera/rgb/image_res/compressed or /raspicam_node/image_res/compressed depending upon the hardware configuration. The web client subscribes to this topic for the camera feed.
Code
/rostopiclist
The node’s purpose is to retrieve the output generated by the terminal command “rostopic list” to receive a list of currently published topics. It performs this functionality through the use of the subprocess package in Python, which will create a new terminal to execute the command. The output is then cleaned to be published over the topic “/rostopic_list”. The topic has a data type of type String. It is subscribed too by the web client and parse the data based upon the comma delimiter. The content is used to create a scrollable menu that displays all of the available rostopics.
Code
Architecture
The command-control repository can be effectively broken down into six branches, with one deprecated branch, to create a total of five active branches:
main: The branch contains the stable version of the project. It is locked, which means no one can directly push to this branch without another person reviewing and testing the changes.
ros-api: The branch was initially committed to develop an API through FastAPI, but was later deprecated because the functionality could be implemented with ROSBridge and ROSLIBJS.
ros-robot: The branch focuses on the development and integration of the Robot Operating System (ROS) with a physical or simulated robot. It includes the launch files responsible for the run of the gps, dynamic image compression, and ROSBridge.
test-old-videofeed: The branch was created to test and debug the previous implementation of the dashboard, which was built five years ago. We imported the video from the old dashboard to our dashboard but later deprecated this implementation as it used additional redundant dependencies which can be implemented with ROSBridge and ROSLIBJS.
test-old-web-client: The branch is to test and understand the previous version of the web client dashboard. It helped us realize areas for improvement, such as a way to set the robot’s IP address within the web application. It also set the tone for our simplified dashboard format.
web-client: The branch is for ongoing development of the new web client. It includes the latest features, improvements, and bug fixes for the web client, which may eventually be merged into the main branch after thorough testing and review.
Contribution Policy
In this section it will guide you through the process of contributing to a GitHub repository following the guidelines outlined in the contributing.md file. This file specifies that the main branch is locked and cannot be directly pushed to, ensuring that changes are reviewed before being merged.
Update the Main Branch
Ensure you are on the main branch and pull down the new changes.
Resolve any conflicts which may arise at this time.
Create a New Branch
Create a new branch for the feature or issue and switch to it.
Verify the current branch is the correct branch before you begin work.
Build Feature
Develop the feature or fix the issue on the new branch.
Check for Conflicts within the Main Branch
Ensure there are no conflicts with the main branch prior to the creation of the pull request. Update the main branch and merge the changes into your feature branch.
Create a Pull Request (PR)
Push the changes to the remote repository and create a pull request on GitHub. Provide a clear and concise description of the purpose of the feature as well as how to test it. Ensure you mention any related issue numbers.
Request a Review
Ask another team member to review your pull request and run the code locally to ensure there are no errors or conflicts.
Merge the Branch
Once the review is complete and the changes are approved, the feature branch can be merged into the main branch through the pull request.
Installation and Run
Clone the GitHub repository which contains the web client code.
Install the necessary dependencies by running ```npm install``` in the terminal.
Start the web client by running ```npm start``` in the terminal.
Open a web browser and type in http://localhost:3000.
Navigate to the settings page on the web client to set them according to your intentions.
Web Client Settings
The IP address of the ROSBridge server. It is the server that connects the web application to the ROS environment.
Port: The port number for the ROSBridge server.
Video Resolution Width: The width of the video resolution for the ROS camera feed.
Video Resolution Height: The height of the video resolution for the ROS camera feed.
Video Frame Width: The width of the video frame for the ROS camera feed.
Video Frame Height: The height of the video frame for the ROS camera feed.
Show Battery Status: A toggle to display the battery status in the web application.
Manual Input Teleoperation: A toggle to enable or disable the manual teleoperation control input to replace the joystick.
Run with ROS Robot
SSH into the robot.
Open the GPS2IP iOS application. In the application settings, under “NMEA Messages to Send”, solely toggle “GLL”. Once set, toggle the “Enable GPS2IP” on the homepage of the application. Additionally, turn off the iOS auto-lock to prevent the application connection from being interrupted. Place the device on the robot.
Launch the necessary ROS launch file to run the vital nodes which include gps, img_res, and rostopiclist. You may use the sim.launch file for a simulation in Gazebo and real.launch for real world.
Run any other nodes that you desire.
Ensure the web client has the correct ROSBridge Server IP Address and Port set within the settings page. You can check this with the “current configurations” button.
If you want the camera to show up, make sure that the correct campera topic is set within the img_res node module. It can vary dependent upon the hardware. The two options are listed within the file with one commented out and the other active. Select one and comment out the other.
Enjoy the web client!
I, Brandon, had initially intended to work on this project independently but was later reached out to by Naimul and Jimmy to form the team as presently constructed. The project was initially framed as a simple remote teleoperation application in which a user could control the robot with an arrow pad. However, it has evolved into a more sophisticated product with the expertise added from my fellow teammates. The project is now boasted as a dashboard that leverages a joystick for a more intuitive control mechanism with a live camera feed and GPS localization which far exceeded the initial outline as a result of the additional requirements associated with a group of three individuals in a team. Pito proposed various ideas associated with campus rover and it was on our own accord that we chose to combine the dashboard with the GPS localization to create a strong command center for a user to control a robot of choice.
The team was constructed based upon a single common interest, participation within a final project that challenged our software engineering skills within a new domain that would have a long-term impact beyond this semester. It was coincidental that our individual areas of expertise balanced out our weaknesses. The team was balanced and all members were extremely active participants throughout weekly stand ups, discussions, and lab work.
Separation of Duties
Naimul Hasan
Throughout the semester, my responsibilities evolved according to the team's requirements. Initially, after Jimmy provided a visual representation of the previous dashboard, I designed an intuitive and user-friendly Figma layout. I then examined the code and relevant research, which led me to employ ROSLIBJS and RosBridge for the project. I dedicated a week to establishing a workflow standard for the team, including locking down the main branch and authoring a CONTRIBUTING.md document to ensure everyone understood and followed the desired workflow. After gaining an understanding of websocket communication between ROSLIBJS and ROSBridge, I focused on developing the Home page, which now features a video feed, map, and teleop joystick component. To address the issue of multiple websocket connections for each component, I transitioned to using a React Class Component with a global ROS variable. This enabled the components to subscribe and publish messages seamlessly. Additionally, I modified one of the ROSLIBJS dependencies to prevent app crashes and created a default settings configuration for simulation mode, which Jimmy later integrated with localStorage. The initial configuration consumed a significant portion of time, followed by the development of the map component. After exploring various options, such as react-leaflet and Google Maps, I chose Mapbox due to its large community and free API for GPS coordinates. Simultaneously, James and I resolved a dashboard crash issue stemming from localStorage data being empty and causing conversion errors. Collaborating with Brandon, I worked on integrating GPS data into the dashboard. We encountered a problem where the frontend couldn't correctly read the message sent as a string. After a week, we devised a solution in the Python code, converting the GPS data from Decimal Degrees and Minutes (DDM) to Decimal Degrees (DD). This adjustment enabled us to track movements on the map accurately. Additionally, I was responsible for deploying the app, initially attempting deployment to Netlify and Heroku. After evaluating these options, I ultimately settled on Azure, which provided the most suitable platform for our project requirements.
It is worth noting that regardless of whether the app is deployed locally, within the Kubernetes cluster on campus, or on Azure, the primary requirement for successful communication between the laptop/client and the robot is that they are both connected to the same network, since dashboard relies on websocket communication to exchange data and control messages with the robot, which is facilitated by the ROSLIBJS and ROSBridge components. Websocket connections can be established over the same local network, allowing for seamless interaction between the robot and the dashboard.
Jimmy Kong
During the beginning of the semester, my work started out as researching the old web client to see if we could salvage features. I was able to get the old web client working which helped us research and analyze the ways in which rosbridge worked and how we would have our web client connect to it as well. After we got a good foundational understanding from the web client, I started working on a settings page which would provide the user with a more convenient and customizable experience. The settings page went through multiple iterations before it became what it is today, as it started out very simple. The following weeks I would work on adding additional components such as the dropdown menu that shows the list of ros topics, the dropdown menu that shows the current settings configuration, the manual input teleoperation form that allows the user to manually input numbers instead of using the joystick, the robot battery status indicator that shows the battery status of the robot, clear button to clear the input boxes, reset to default button to clear locally stored values, placeholder component that displays a video error message, and last but not least dark mode for theming the website and for jokes since we basically wrapped up the project with a few days to spare. For the dropdown menu that shows the list of ros topics, I also had to create a python node that would send the “rostopic list” command and then use that output to then publish as a string separated by commas as a row topic. I would then subscribe to that topic and parse it via commas on the web client side for the rostopiclist button. After adding all these components, I also had to add the corresponding buttons (if applicable like dark mode or battery status) to the settings page to give the user the option to disable these features if they did not wish to use them. Inserting forms and buttons into the settings page made us have to think of a way to save the settings configurations somehow to survive new browser sessions, refreshes, and the switching of pages. To solve this issue, I utilized localStorage which worked great. I wrote logic for deciding when to use localStorage and when to use default values stored in our ros_configs file. After finishing the implementation of local storage, I also decided to add some form validation along with some quality of life error indicator and alert messages to show the user that they are putting in either correct or incorrect input. Aside from focusing on the settings page, I also handled the overall theming and color scheme of the website, and made various tweaks in CSS to make the website look more presentable and less of a prototype product. I also modified the about page to look a bit better and created a new help page to include instructions for running the web client. In summary, I was responsible for creating multiple components for the web client and creating the appropriate setting configuration options within the settings page, working on the aesthetics of the website, and creating the help page. Lastly, I also edited the demo video.
Brandon J. Lacy
The contribution to this project on my behalf can be broken down into two different phases: team management and technical implementation. I was responsible for the project idea itself and the formation of the team members. I delegated the duties of the project amongst the team members and led the discussions within our weekly discussions outside of the classroom. I also set the deadlines for our team to stay on track throughout the semester. The technical contribution revolves around the GPS implementation in which I selected the GPS receiver, an iPhone with the GPS2IP iOS application. I was responsible for the Python code to receive the data from the GPS receiver over the internet. Lastly, I was responsible for the node that changes the resolution of the image that is displayed on the web client.Lastly, I wrote 75% of the report and the entire poster.
Major Hurdles
Initially, the dashboard was hosted on Naimul's laptop for testing purposes, which allowed the team to evaluate its functionality and performance in a controlled environment. When we tried to deploy the dashboard on Netlify, we encountered several issues that hindered the deployment process and the app's performance.
One of the primary issues with Netlify was its inability to run a specific version of Node.js, as we want to avoid version mismatch, required by the dashboard. This limitation made it difficult to build the app using Netlify's default build process, forcing the us to manually build the app instead. However, even after successfully building the dashboard manually, the we faced additional problems with the deployment on Netlify. The app would not load the map component and other pages as expected, which significantly impacted the app's overall functionality and user experience.
As we were trying to find a new platform to host the dashboard so it can run 24/7 and pull down any changes from the main branch. Azure allowed us to download specific version of dependencies for the dashboard, while leaving overhead in resource availability if there is a lot of traffic. As mentioned above, regardless of whether the app is deployed locally, within the Kubernetes cluster on campus, or on Azure, the primary requirement for successful communication between the laptop/client and the robot is that they are both connected to the same network, since dashboard relies on websocket communication to exchange data and control messages with the robot, which is managed by the ROSLIBJS and ROSBridge components. Websocket connections can be established over the same local network, allowing for seamless interaction between the robot and the dashboard.
Major Milestones
Public Web Client hosting
Hosting the web client publically so that anyone can access the website with a link was a major milestone that we reached since just hosting through local host was not practical since its just for development usage and would not be very useful. More is explained within the major hurdle discussed above.
GPS
The implementation of the GPS was a major milestone in our project as it was the most difficult to design. When the project was initialized, there was no intention to incorporate GPS into the dashboard. However, the requirements for the project were increased when the team expanded to three people. The GPS portion of the project was dreaded, quite frankly, so when the Python code was completed for a ROS node that listened to the GPS data being published from the GPS2IP iOS application it was a huge celebration. The kicker was when the topic was subscribed to on the front-end and the visualization on the map was perfectly accurate and moved seamlessly with our movement across campus.
Dark Mode
Dark mode, a seemingly small feature, turned out to be a monumental milestone in our project. Its implementation was far from smooth sailing, and it presented us with unexpected challenges along the way. Little did we know that this seemingly simple concept would revolutionize the entire user experience and become the most crucial component of our project. Initially, we underestimated the complexity of integrating dark mode into our dashboard. We had to navigate through a labyrinth of CSS styles, meticulously tweaking each element to ensure a seamless transition between light and dark themes. Countless hours were spent fine-tuning color schemes, adjusting contrasts, and experimenting with different shades to achieve the perfect balance between aesthetics and readability. The moment dark mode finally came to life, everything changed. It was as if a veil had been lifted, revealing a whole new dimension to our dashboard. The sleek, modern interface exuded an air of sophistication, captivating users and immersing them in a visually stunning environment. It breathed life into every element, enhancing the overall user experience. It quickly became apparent that dark mode was not just another feature; it was the heart and soul of our project. The dashboard transformed into an oasis of productivity and creativity, with users effortlessly gliding through its streamlined interface. Tasks that were once daunting became enjoyable, and the project as a whole gained a newfound momentum. In fact, we can boldly assert that without dark mode, our dashboard would be practically unusable. The blinding glare of the bright background would render the text illegible, and the stark contrast would induce eye strain within minutes. Users would be left squinting and frantically searching for a pair of sunglasses, rendering our carefully crafted functionalities utterly useless. Dark mode's significance cannot be overstated. It has redefined the essence of our project, elevating it to new heights. As we reflect on the struggles, the countless lines of code, and the sleepless nights spent perfecting this feature, we cannot help but celebrate the impact it has had. Dark mode, the unsung hero of our project, has left an indelible mark on our journey, forever changing the way we perceive and interact with our dashboard.
We sought a deeper understanding of the inter-process communications model of ROS to be able to allow our web application to take advantage of this model and we’ve successfully developed this knowledge. Additionally, it allowed us to integrate our software development knowledge with ROS to create a complex system which will draw attention to our respective resumes. We are proud of the product created in this course and see it as a major improvement from the previous implementation of the dashboard. The only aspect in which we are not content is the lag present on the camera feed and joystick. However, there are areas for improvement in which we recommend to be addressed by the next team to tackle this project. The lag issue previously described is one of them as it decreases usability of the product. It would also be useful to create a map of the campus with way points in which the GPS can be utilized to create a path from one place to another. There are a variety of improvements to be made to this application to continue to shape campus rover into an implemented product. It’s up to the next generation of students to decide where to take it next.
The idea of the autopilot robot was simple – it’s a mobile robot augmented with computer vision, but it’s a fun project to work on for people wishing to learn and combine both robotics and machine learning techniques in one project. Evenmore, one can see our project as miniature of many real world robots or products: robot vacuum (using camera), delivery robot and of course, real autopilot cars; so this is also an educative project that can familiarize one with the techniques used, or at least gives a taste of the problems to be solved, for these robots/products.
Able to follow a route
Able to detect traffic signs
Able to behave accordingly upon traffic signs
What was created
Technical descriptions, illustrations
There are five types and two groups of traffic signs that our robot can detect and react to. Here are descriptions of each of them and the rules associated with them upon the robot’s detection.
Traffic light (See Fig1)
Red light: stops movement and restarts in two seconds.
Orange light: slows down
Green light: speeds up
Turn signs (See Fig2)
Left turn: turn left and merge into the lane
Right turn: turn right and merge into the lane
All turns are 90 degrees. The robot must go straight and stay in the lane if not signaled to turn.
2. Discussion of interesting algorithms, modules, techniques
The meat of this project is computer vision. We soon realized that different strategy can be used the two groups of traffic signs as they have different types of differentiable attributes (color for traffic lights and shape for turning signs).Therefore, we used contour detection for traffic lights, and we set up a size and circularity threshold to filter noise out noise. Turning signs classification turned out to be much harder than we initially expected in the sense that the prediction results seem to be sometimes unstable, stochastic, and confusing (could be because of whatever nuance factors that differ in the training data we found online and the testing data (what the robot sees in lab).
We tried SVM, Sift, and CNN, and we even found a web API for traffic signs models that we integrated into our project – none of them quite work well.
Therefore we decided to pivot to another more straightforward approach: we replaced our original realistic traffic signs (Fig2a) with simple arrows (Fig2b), and then what we are able to do is that:
Detect the blue contour and crop the image from robot’s camera to a smaller size
Extract the edges and vertices of the arrow, find the tip and centroid of it
Classify the arrow’s direction based on the relative position of the tip to the centroid
Two more things worth mentioning on lane following:
Our robot follows a route encompassed by two lines (one green and one red) instead of following one single line. Normally the robot uses contour detection to see the two lines and then computes the midpoint of them. But the problem comes when the robot turns – in this case, the robot can only see one colored line. The technique we use is to only follow that line and add an offset so that the robot turns back the the middle of the route (the direction of the offset is based on the color of that line)
How we achieve turning when line following is constantly looking for a midpoint of a route. What we did is that we published three topics that are named “/detect/lane/right_midpoint”, “/detect/lane/midpoint”, “/detect/lane/left_midpoint”. In this case there are multiple routes (upon an intersection), the robot will choose to turn based on one of midpoint position, based on the presence turning sign. By default, the robot will move according to the “/detect/lane/midpoint” topic.
Table 1. Nodes and Messages description
Story of the project
How it unfolded, how the team worked together
At the very beginning of our project, we set these three milestones for our work:
And we have been pretty much following this plan, but as one can tell, the workload for each phase is not evenly distributed.
Milestone 1 is something we’ve already done in assignment, but here we use two lines to define a route instead of just one single line, and the complexity is explained above. Traffic light classification was pretty straightforward in the hindsight. We simply used color masking and contour detection. To avoid confusing the robot between red green lines that define the route, and the red green traffic signs, we set up a circularity and area threshold. We spent the most time on milestone 3. We experimented with various methods and kept failing until we decided to simply our traffic signs – more details are explained in section 8. Our team worked together smoothly. We communicated effectively and frequently. As there are three of us, we divided the work into lane detection and following, traffic light classification, and sign classification and each of us works on a part to maximize productivity. After each functionality is initially built, we worked closely to integrate them and debug together.
problems that were solved, pivots that had to be taken
The first problem or headache we encountered is that we use a lot of colors for object detection in this project, so we had to spend a great amount of time tuning HSV values of our color-of-interest, as slight changes in background lighting/color mess up with it.
The more challenging part is that, as alluded to above, turning signs classification is more difficult than we initially expected. We tried various model architectures, including CNN, SVM, SIFT, and linear layers. No matter what model we choose, the difficulty comes from the inherent instability of machine learning models. Just to illustrate it: we found a trained model online that was trained on 10000 traffic signs images, for 300 epochs, and reached a very low loss. It is able to classify various traffic signs – stop sign, rotary, speed limit, you name it. But sometimes, it just failed on left turn and right turn classification (when the image is clear and background is removed), and we didn’t figure out a great solution on remediating this. So instead we piloted away from using machine learning models and replaced curved traffic signs (Fig 2a) with horizontal arrows (Fig 2b). The detail of the algorithm is discussed in section 4.
Your own assessment
We think that this has been a fun and fruitful experience working on this project. From this semester’s work, we’ve all had a better appreciation of the various quirky problems in robotics – we had to basically re-pick all the parameters when we migrated from gazebo world the the real lab, and also we literally had to re-fine-tune the hsv values everytime we switched to a new robot because of the minute difference in background lighting and each robot’s camera. So if one thing we learned from this class, it’s real Robots Don't Drive Straight. But more fortunately, we’ve learned a lot more than this single lesson, and we’re able to use our problem solving and engineering skills to find work-arounds for all those quirky problems we encountered. Therefore, in summary we learned something from every failure and frustration, and after having been through all of these we’re very proud of what we achieved this semester.
Benjamin Blinder benjaminblinder@brandeis.edu
Ken Kirio kenkirio@brandeis.edu
Vibhu Singh vibhusingh@brandeis.edu
The project coordinates a stationary arm robot and a mobile transportation robot to load and unload cargo autonomously. We imagine a similar algorithm being used for loading trucks at ports or in factory assembly lines.
There are three phases: mapping, localization, and delivery.
First, the robot drives around and makes a map. Once the map is made, a person will manually drive the robot to a delivery destination and press a button to indicate its location to the robot. Then the person will manually have to drive the robot back to the loading point and mark that location as well. With this setup, the robot can start working as the delivery robot and transporting cubes from the loading zone to the arm.
In the delivery phase, a person loads a piece of cargo - we used a 3D printed cube - onto the robot and then presses a button to tell the robot that it has a delivery to make. Once there, computer vision is used to detect the cargo and calculate its position relative to the arm. Once the arm receives the coordinates, it determines what command would be necessary to reach that position and whether that command is physically possible. If the coordinates aren’t valid, the transportation robot attempts to reposition itself so that it is close enough for the arm. If the coordinates are valid, the arm will then grab the cube off the loading plate on the robot and place it in a specified go. Finally, the transportation robot will go back to the initial home zone, allowing the process to repeat.
Mapping
Create a map
Localize on a premade map
A flowchart of message passing that must occur between the three main components of this project.
We needed the robot to be able to move autonomously and orient itself to the arm, so we decided to use SLAM to create a map and the AMCL and move_base packages to navigate. Using SLAM, we use the LiDAR sensor on the robot to create a map of the room, making sure we scan clear and consistent lines around the arm and the delivery zone. We then save the map and use AMCL to generate a cost map. This also creates a point cloud of locations where the robot could be according to the current LiDAR scan. Then, we manually moved the robot through the map in order to localize the robot to the map and ensure accurate navigation. We then capture the position and orientation data from the robot for a home and delivery location, which is then saved for future navigation. Finally, we can tell the robot to autonomously navigate between the two specified locations using the move_base package which will automatically find the fastest safe route between locations, as well as avoid any obstacles in the way.
Cargo is detected via color filtering. We filter with a convolutional kernel to reduce noise, then pass the image through bitwise operators to apply the color mask. The centroid is converted from pixels to physical units by measuring the physical dimensions captured by the image.
Since commands to the arm are sent in polar coordinates, the cartesian coordinates obtained from the image are then converted into polar. These coordinates must then be transformed into the units utilized by the arm, which have no physical basis. We took measurements with the cargo in various positions and found that a linear equation could model this transformation, and utilized this equation to determine the y-coordinate. However, the x-coordinate could not be modeled by a linear equation, as the arm's limited number of possible positions along this axis made it impossible to determine a strong relationship between the coordinates. In addition, whether the cargo was parallel or at an angle to the arm affected the location of the ideal point to grab on the cargo. Instead we calculated the x-position by assinging the position and orientation of the cargo to states, which were associated with a particular x-coordinate.
Arm robot
The arm robot needs to be elevated so that it can pick up the cube. Ensure that the setup is stable even when the arm changes positions, using tape as necessary. Determine the z-command required to send the arm from the "home" position (see ) to the height of the cargo when it is loaded on the transportation robot. This will be one parameter of the launch file.
Camera
The camera should be set in a fixed position above the loading zone, where the lens is parallel to the ground. The lab has a tripod for such purposes. Record the resolution of the image (default 640x480) and the physical distance that the camera captures at the height of the cargo when placed on the transportation robot. These will also be parameters for the launch file.
Run roslaunch cargoclaw transport_command.launch. Separately, run roslaunch cargoclaw arm_command.launch with the following parameters:
arm_z: z-command from the arm's position to pick up the cargo from the transportation robot (Setup #1)
width_pixels/height_pixels: Image resolution (Setup #2)
width_phys/height_phys: Physical dimensions captured in the image at the height of the cargo (Setup #2)
Mode 1: Mapping Use teleop to drive the robot between the loading and unloading zones. Watch rviz to ensure adequate data is being collected.
Mode 2: Localizing Use teleop to drive the robot between the loading and unloading zones. Watch rviz to ensure localization is accurate. Press the "Set Home" button when the robot is at the location where cargo will be loaded. Press the "Set Goal" button when the robot is at the location of the arm.
Mode 3: Running When the cargo is loaded, press "Go Goal". This will send the robot to the loading zone where the loading/unloading will be done autonomously. The robot will then return to the home position for you to add more cargo. Press "Go Goal" and repeat the cycle. The "Go Home" button can be used if the navigation is not working, but should not be necessary.
Nodes
Messages
We began by trying to send commands to the robotic arm through ROS. While the arm natively runs proprietary software, Veronika Belkina (hyperlink?) created a package that allows for ROS commands to control the arm which we decided to utilize. The arm is controlled via USB so first we had to set up a new computer with Ubuntu and install ROS. Our first attempt was unsuccessful due to an unresolved driver error, but our second attempt worked. This step took a surprising amount of time, but we learned a lot about operating systems while troubleshooting in this stage.
Simultaneously, we researched the arm capabilities and found that the arm can pick up a maximum weight of 30g. This required that we create our own 3D printed cubes to ensure that the cargo would be light enough. All cubes were printed in the same bright yellow color so that we could use color filtering to detect the cube.
Next, we tested our code and the cubes by coding the arm to pick up a piece of cargo from a predetermined location. This step was difficult because commands for the x/z-coordinates are relative, while commands for the y-coordinate are absolute. After this test worked, we made the node more flexible, able to pick up the cargo from any location.
With the arm working, we then began working on the image processing to detect the cargo and calculate its location. First we had to set up and calibrate the USB camera using the usb_cam package. Then we began working on cargo detection. Our first attempt used color filtering, but ran into issues due to the difference in data between the USB camera and the robots' cameras. We then tried applying a fiducial to the top of the transportation robot and using the aruco_detect package. However, the camera was unable to reliably detect the fiducial, leading us to return to the color detection method. With some additional image transformation and noise reduction processing, the color detection was able to reliably identify the cargo and report its centroid. Then, since the height of the transportation robot is fixed we were able to calculate the physical location of the cargo based on the ratio of pixels to physical distance at that distance from the camera. Using this information, we created another node to determine whether the cube is within the arm's range to pick up. We found converting the physical coordinates to the commands utilized by the arm to be extremely difficult, ultimately deciding to take many data points and run a regression to find a correlation. With this method we were relatively successful with the y-coordinate, which controlled the arm's rotation.
Simultaneously, we coded the transportation robot's autonomous navigation. We realized our initial plan to combine LIDAR and fiducial data to improve localization would not work, as move_base required a cost map to calculate a trajectory while fiducial_slam saved the coordinates of each detected fiducial but did not produce a cost map. We decided to move forward by using slam_gmapping, which utilized lidar data and did produce a cost map. This allowed us to use move_base to reach the approximate location of the arm, and fine-tune the robot's position using fiducial detection as necessary. However, upon testing, we realized move_base navigation was already very accurate, and trading control between the move_base and a fiducial-following algorithm resulted in unexpected behavior, so we decided to just use move_base alone.
Finally, we attempted to combine each of these components. Although move_base allowed for good navigation, we found even slight differences in the orientation of the robot in the delivery zone resulted in differences in the coordinates necessary to grab the cargo. We decided to make the image processing component more robust by pivoted to using polar rather than cartesian coordinates when calculating the commands to send to the arm, as the arm's x- and y-coordinates correspond to its radius and angle. We then used different approaches for transforming the x- and y-coordinates into commands. The arm had very limited range of motion along its x-axis, making it practical to measure the cargo's location at each position and pick the x-command which most closely corresponded to the cargo's location. However, the robot had a much greater range along its y-axis, leading us to take measurements and perform a cubic regression to get an equation of the command for a given y-coordinate. In addition, we added further tuning after this step, as the cargo's orientation required that the arm move increasingly along its y-axis to pick up a piece of cargo that is angled compared to the arm's gripper.
Working as a team was very beneficial for this project. Although we all planned the structure of the project and overcame obstacles as a team, each person was able to specialize in a different area of the project. We had one person work on the arm, another on image processing, and another on the transportation robot.
Team Members: Michael Jiang (michaeljiang@brandeis.edu) & Matthew Merovitz (mmerovitz@brandeis.edu)
The project aimed to create a robot that could mimic the game of bowling by grabbing and rolling a ball towards a set of pins. The robot was built using a Platform bot with a pincer attachment. The ball is a lacrosse ball and the “pins” are either empty coffee cups or empty soda cans.
At first, we imagined that in order to achieve this task, we would need to create an alley out of blocks, map the space, and use RGB for ball detection. None of this ended up being how we ultimately decided to implement the project. Instead, we opted to use fiducial detection along with line following to implement ball pickup and bowling motion. The fiducial helps a lot with consistency and the line following allows the robot to be on track.
The primary objective of the BowlingBot project was to develop a robot that could perform the task of bowling, including locating the ball, grabbing it, traveling to the bowling alley, and knocking down the pins with the ball. The project aimed to use a claw attachment on the Platform bot to grab and roll the ball towards the pins. The robot was designed to use fiducial markers for ball detection and orientation, and line detection for pin alignment.
The BowlingBot project utilized several algorithms to achieve its objectives. These included:
Fiducial Detection: The robot was designed to use fiducial markers to detect the location and orientation of the ball. The fiducial markers used were ArUco markers, which are widely used in robotics for marker-based detection and localization. In addition, we used odometry to ensure precision, allowing us to consistently pick up the ball.
Line Detection: The robot utilized line detection techniques to align itself with the pins. This involved using a camera mounted on the robot to detect the yellow line on the bowling alley and align itself accordingly. This also uses OpenCV.
Pincer Attachment: The BowlingBot utilized a pincer attachment to pick up the ball and roll it towards the pins.
The code is centered around a logic node that controls the logic of the entire bowling game. It relies on classes in fiducialbowl.py, pincer.py, bowlingmotion.py.
Fiducialbowl.py: This class has two modes. Travel mode is for traveling to the ball in order to pick it up and then traveling back to the bowling alley. Bowling mode is for ensuring centering of the robot along the line with the assistance of the yellow line.
Pincer.py: Controls the opening and closing of the pincer attachment on the platform bot.
Bowlingmotion.py: This node turns until the yellow line is seen, centers the robot along the line, and then performs the quick motion of moving forwards and releasing the ball.
During our time developing the BowlingBot, we encountered several obstacles and challenges that we were forced to overcome and adjust for. Initially, the crowded lab hours slowed down our camera and sensors, peaking at about a minute delay between the camera feed and what was happening in real time. We decided collectively to instead come during office hours when it was less crowded in order to avoid the severe network traffic, which allowed us to test the camera properly.
Another roadblock was finding an appropriate ball, which held up our testing of the bowling motion. We knew we needed a ball that was heavy enough to knock over pins, but small enough to fit inside the pincer. We initially bought a lacrosse ball to test with, but it was too grippy and ended up catching on the ground and rolling under the robot, forcing us to pivot to using a field hockey ball, which was the same size and weight but crucially was free from the grippiness of the lacrosse ball.
Another challenge we had to adapt to was the actual bowling motion. We initially proposed that the robot should implement concepts from the line follower so that it could adjust its course while rolling down the alley. However, we discovered that the robot’s bowling motion was too quick for it to reliably adjust itself in such a short time. To resolve this, we pivoted away from adjusting in-motion and instead implemented aligning itself as best as possible before it moves forward at all.
The BowlingBot project was inspired by the team's love for robotics and bowling. The team was intrigued by the idea of creating a robot that could mimic the game of bowling and we spent lots of time researching and developing the project.
The project was challenging and required us to utilize several complex algorithms and techniques to achieve our objectives. We faced several obstacles, including issues with ball detection and alignment, and had to continuously iterate and refine our design to overcome these challenges.
Despite the challenges, the team was able to successfully develop a functional BowlingBot that could perform the task of bowling. We are excited to showcase our project to our peers and hold a demonstration where participants can compete against the robot.
Overall, the BowlingBot project was a success, and the team learned valuable lessons about robotics, problem-solving, and combining several class concepts into a more complex final product.
For our team's COSI119a Autonomous Robotics Term Project, we wanted to tackle a challenge that was not too easy or not hard. All of our members have only recently learned ROS, so to create a fully demo-able project in 8 weeks sounded impossible. We started off having a few ideas: walking robot that follows an owner, robot that plays tag, and a pet robot that accompanies one. There were a lot of blockers for those ideas from limitation of what we know, tech equipments, time constraints, and mentor's concern that it will not be able to. We had to address issues like:
Names: Isaac Goldings (isaacgoldings@brandeis.edu), Jeremy Huey (jhuey@brandeis.edu), David Pollack (davidpollack@brandeis.edu)
Instructor: Pito Salas (rpsalas@brandeis.edu)
Date: 05/03/2023
#!/usr/bin/env python
'''
A module with a GPS node.
GPS2IP: http://www.capsicumdreams.com/gps2ip/
'''
import json
import re
import rospy
import socket
from std_msgs.msg import String
class GPS:
'''A node which listens to GPS2IP Lite through a socket and publishes a GPS topic.'''
def __init__(self):
'''Initialize the publisher and instance variables.'''
# Instance Variables
self.HOST = rospy.get_param('~HOST', '172.20.38.175')
self.PORT = rospy.get_param('~PORT', 11123)
# Publisher
self.publisher = rospy.Publisher('/gps', String, queue_size=1)
def ddm_to_dd(self, degrees_minutes):
degrees, minutes = divmod(degrees_minutes, 100)
decimal_degrees = degrees + minutes / 60
return decimal_degrees
def get_coords(self):
'''A method to receive the GPS coordinates from GPS2IP Lite.'''
# Instantiate a client object
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.connect((self.HOST, self.PORT))
# The data is received in the RMC data format
gps_data = s.recv(1024)
# Transform data into dictionary
gps_keys = ['message_id', 'latitude', 'ns_indicator', 'longitude', 'ew_indicator']
gps_values = re.split(',|\*', gps_data.decode())[:5]
gps_dict = dict(zip(gps_keys, gps_values))
# Cleanse the coordinate data
for key in ['latitude', 'longitude']:
# Identify the presence of a negative number indicator
neg_num = False
# The GPS2IP application transmits a negative coordinate with a zero prepended
if gps_dict[key][0] == '0':
neg_num = True
# Transform the longitude and latitude into decimal degrees
gps_dict[key] = self.ddm_to_dd(float(gps_dict[key]))
# Apply the negative if the clause was triggered
if neg_num:
gps_dict[key] = -1 * gps_dict[key]
# Publish the decoded GPS data
self.publisher.publish(json.dumps(gps_dict))
if __name__ == '__main__':
# Initialize a ROS node named GPS
rospy.init_node("gps")
# Initialize a GPS instance with the HOST and PORT
gps_node = GPS()
# Continuously publish coordinated until shut down
while not rospy.is_shutdown():
gps_node.get_coords()#!/usr/bin/env python
'''
A module for a node that alters the quality of the image.
'''
import cv2
import numpy as np
import re
import rospy
from cv_bridge import CvBridge
from sensor_msgs.msg import CompressedImage
from std_msgs.msg import String
class Compressor:
''''''
def __init__(self):
'''Initialize necessary publishers and subscribers.'''
# Instance Variables
# Initialize an object that converts OpenCV Images and ROS Image Messages
self.cv_bridge = CvBridge()
# Image Resolution
self.img_res = {
'height': 1080,
'width': 1920
}
# Publisher - https://answers.ros.org/question/66325/publishing-compressed-images/
# self.publisher = rospy.Publisher('/camera/rgb/image_res/compressed', CompressedImage, queue_size=1)
self.publisher = rospy.Publisher('/raspicam_node/image_res/compressed', CompressedImage, queue_size=1)
# Subscribers
# self.subscriber_cam = rospy.Subscriber('/camera/rgb/image_raw/compressed', CompressedImage, self.callback_cam, queue_size=1)
self.subscriber_cam = rospy.Subscriber('/raspicam_node/image/compressed', CompressedImage, self.callback_cam, queue_size=1)
self.subscriber_set = rospy.Subscriber('/image_configs', String, self.callback_set, queue_size=1)
def callback_cam(self, msg):
'''A callback that resizes the image in line with the specified resolution.'''
# Convert CompressedImage to OpenCV
img = self.cv_bridge.compressed_imgmsg_to_cv2(msg)
# Apply New Resolution
img = cv2.resize(img, (self.img_res['height'], self.img_res['width']))
# Convert OpenCV to CompressedImage
msg_new = self.cv_bridge.cv2_to_compressed_imgmsg(img)
# Publish
self.publisher.publish(msg_new)
def callback_set(self, msg):
'''A callback to retrieve the specified resolution from the web client.'''
img_set = re.split(',', msg.data)
self.img_res['height'] = int(img_set[0])
self.img_res['width'] = int(img_set[1])
if __name__ == "__main__":
rospy.init_node("img_comp")
comp = Compressor()
rospy.spin()#!/usr/bin/env python
import rospy
from std_msgs.msg import String
import subprocess
def get_ros_topics():
"""
Returns a list of active ROS topics using the `rostopic list` command.
"""
command = "rostopic list"
process = subprocess.Popen(command.split(), stdout=subprocess.PIPE)
output, error = process.communicate()
topics = output.decode().split("\n")[:-1] # remove empty last element
return topics
def rostopic_list_publisher():
"""
ROS node that publishes the list of active ROS topics as a string message.
"""
rospy.init_node('rostopic_list_publisher', anonymous=True)
pub = rospy.Publisher('/rostopic_list', String, queue_size=10)
rate = rospy.Rate(1) # 1 Hz
print("[INFO] Robot.py node has been started!")
while not rospy.is_shutdown():
1 topics = get_ros_topics()
message = ",".join(topics)
pub.publish(message)
rate.sleep()
if __name__ == '__main__':
try:
rostopic_list_publisher()
except rospy.ROSInterruptException:
passPerform autonomous navigation between two fixed points
Image processing
Recognize the cargo
Calculate the physical location of the cargo
Robotic arm
Coordinate commands on a robot that does not run ROS natively
arm_cam
Accepts image of the delivery zone from the camera, detects the cargo with color filtering, and calculates and publishes its physical location
box_pickup
Accepts the coordinates published from arm_cam and uses a linear regression to determine the y transform and a set of ranges to determine the x transform
cargo_bot
Directly controls the motion of the Alien Bot using cmd_vel and move_base
cargo_gui
User interface which allows control of the robot as well as setting the mapping and navigation points
alien_state
True if the transportation robot has finished navigating to the delivery zone. Published by `cargo_bot` and subscribed to by `arm_cam`.
cargo_point
The physical position of the cargo. Published by `arm_cam` and subscribed to by `box_pickup`.
UI
A string of information relaying the state, position, and time since the last input for the robot which is published to `cargo_gui` for display
keys
A string that directs robot movement. Published from `cargo_gui` to `cargo_bot`.
arm_status
A string relaying whether the location of the cargo can be picked up by the arm, and if so, when the arm has finished moving the cube. This informs the transportation robot's movement in the delivery zone. Published by `box_pickup` and subscribed to by `cargo_bot`.






Run “roslaunch autopilot autopilot.launch”, which starts the four nodes used in our project.
Clear description and tables of source files, nodes, messages, actions
YES
Midpoint of a lane
/detect/lane/right_midpoint
MidpointMsg
YES
Midpoint of a left lane (when there’s a branch or cross)
/detect/lane/left_midpoint
MidpointMsg
YES
Midpoint of a right lane (when there’s a branch or cross)
/detect/sign
SignMsg
[string direction
float32 width
float32 height]
YES
Detection of the
/detect/light
LightMsg
[string color
float32 size]
YES
Detection of a traffic light
Cmd_vel
Twist
NO
Publish movement
/raspicam_node/image/compressed
CompressedImage
NO
Receive camera data
/detect/lane/midpoint
MidpointMsg
[int32 x
int32 y
int32 mul]
In the end, we decided to work on a robot that guards an object and stop an intruder from invading a specified region. We pivoted from having one robot to having multiple robots so that they are boxing out the object that we are protecting. We tested a lot of design decisions where we wanted to see which method would give us the desired result with the most simple, least error prone, and high perfomring result.
There were a lot of learnings throughout this project, and while even during the last days we were working to deploy code and continue to test as there is so much that we want to add.
Video demo: https://drive.google.com/drive/folders/1FiVtw_fQFKpZq-bJSLRGotYXPQ-ROGjI?usp=sharing
As we will be approaching this project with an agile scrum methodology, we decided to take the time in developing our user stories, so that at the end of the week during our sprint review we know if we are keeping us on track with our project. After taking a review of the assignment due dates for other assignments of the class, we thought that having our own group based deadlines on Friday allows us to make these assignments achievable on time. Below is a brief outline of our weekly goals.
Here is a ⏰ timeline ⏳ , we thought were were going to be able to follow:
March 3: Finish the Movie Script That Explains Story of Waht we want to do and Proposal Submission
March 10: Figure out if tf can be done in gazebo
March 17: Run multiple real robots
March 24: Detect the object
March 31: Aligning to be protecting it - circle or square like formation
April 7: Detecting if something is coming at it
April 14: Making the robot move to protect at the direction that the person is coming at it from
April 21: Testing
April 28: Testing
May 3: Stop writing code and work on creating a poster
May 10 Continuing to prepare for the presentation
Here is a timeline of what we actually did:
March 3: Finished all Drafting and Proposal - Submitted to get Feedback and Confirmation That it is Good To Go (Karen, LiuLu, Rongzi)
March 10: Figure out if tf can be done in gazebo (Rongzi), Creating Github Repo (Karen), Drawing Diagrams (Liulu), Explore Gazebo Worlds - Get Assests and Understand Structure (Karen)
March 17: Run multiple real robots on Gazebo (Karen), Created multi robot gazebo launch files (Karen), Wrote Code on Patroling Line (Liulu), Create box world (Rongzi), Make Behavior Diagram (Karen)
March 24: Continue to write code on patroling the line for multirobot (Liulu), Explored fiducials to integrate (Karen), Made better Gazebo world (Rongzi)
March 31: Aligning to be protecting it - circle or square like formation
April 7: Detecting if something is coming at it
April 14: Making the robot move to protect at the direction that the person is coming at it from
April 21: Testing
April 28: Testing
May 3: Stop writing code and work on creating a poster
May 10 Continuing to prepare for the presentation
Here is another breakdown of the timeline that we actually followed:
To address blockers, we had to start asking ourselves questions and addressing issues like:
What are the major risky parts of your idea so you can test those out first?
What robot(s) will you want to use?
What props (blocks, walls, lights) will it need?
What extra capabilities, sensors, will your robot need? How you have verified that this is possibler?
And many other questions.
Here was the original plan of what we wanted to display:
Though things do not often go to plan as we did not realize that step 2 to step 3 was going to be so much harder as there was all these edge cases and blockers that we discovered (concurrency, network latency, camera specs). We ended up really only focusing on the patrolling and block stages.
There are many states to our project. There is even states withhin states that need to be broken down. Whenever we were off to coding, we had to make sure that we were going back to this table to check off all the marks about control of logic. We were more interested in getting all the states working, and so we did not use any of the packages of state management. Another reason why we did not proceed with using those state pacakges was because we needed to have multiple files as one python file represented one node so we were not able to be running multiple robot through one file.
Here are the states that we were planning to have.
Finding State: Trigger: Lidar detection/Fiducial Detection/Opencv: Recognizing the target object, consider sticking a fiducial to the target object, and that will help the robot find the target object. The state is entered when Lidar finds nothing but the target object with a fiducial.
Patrolling State: Trigger: Lidar detection: When there is nothing detected in the right and left side of the robot, the robot will keep patrolling and receive callbacks from the subscriber.
Signal State: Trigger: Lidar detection: Finding intruders, which means the lidar detect something around and will recognize it as the intruder New topic: If_intruder: Contain an array that formed by four boolean values corresponds to each robot’s publisher of this topic or the position of another robot. The robot will publish to a specific index of this array with the boolean value of the result of their lidar detection. If there is nothing, the robot will send False, and if it can get into the Signal State, it will send it’s position and wait for the other robot’s reaction.
Form Line State: Trigger: The message from topic if_intruder: When a robot receives a position message, it will start to go in that direction by recognizing the index of the position message in the array, and they’ll go to that corresponding colored line. Behavior Tree: A behavior will be created that can help the robot realign in a colored line.
Blocking State: Trigger: tf transformation:All the robots have the information that there is an intruder. All the robot will go to the direction where the intruder is and realign and try to block the intruder
Notify State: Trigger: Lidar Detection: If the lidar keeps detecting the intruder and the intruder doesn’t want to leave for a long time, the robot will keep blocking the intruder without leaving. If the intruder leaves at some time, the robot will get back to the blocking state and use lidar to detect and make sure there is no intruder here and turn back to the finding state
In the end, these were the only states that we actually tackled:
Get correct color for line following in the lab Line follower may work well and easy to be done in gazebo because the color is preset and you don't need to consider real life effect. However, if you ever try this in the lab, you'll find that many factors will influence the result of your color.
Real Life Influencer:
Light: the color of the tage can reflect in different angles and rate at different time of a day depend on the weather condition at that day.
Shadow: The shadow on the tape can cause error of color recognization
type of the tape: The paper tage is very unstable for line following, the color of such tape will not be recognized correctly. The duct tape can solve most problem since the color that be recognized by the camera will not be influenced much by the light and weather that day. Also it is tougher and easy to clean compare to other tape.
color in other object: In the real life, there are not only the lines you put on the floor but also other objects. Sometimes robots will love the color on the floor since it is kind of a bright white color and is easy to be included in the range. The size of range of color is a trade off. If the range is too small, then the color recognization will not be that stable, but if it is too big, robot will recognize other color too. if you are running multiple robots, it might be a good idea to use electric tape to cover the red wire in the battery and robot to avoid recognizing robot as red line.
OpenCV and HSV color: Opencv use hsv to recognize color, but it use different scale than normal. Here is a comparison of scale: normal use H: 0-360, S: 0-100, V: 0-100 Opencv use H: 0-179, S: 0-255, V: 0-255
So if we use color pick we find online, we may need to rescale it to opencv's scale.
Here is a chart that talks about how we run the real robots live with those commands. On the right most column that is where we have all of the colors for each line that the robot home base should be:
If you are interested in launching on the real turtlebot3, you are going to have to ssh into it and then once you have that ssh then you will be able to all bringup on it. There is more detail about this in other FAQs that can be searched up. When you are running multirobots, be aware that it can be a quite bit slow because of concurrency issues.
These 3 files are needed to run multiple robots on Gazebo. In the object.launch that is what you will be running roslaunch. Within the robots you need to spawn multiple one_robot and give the position and naming of it.
Within the object.launch of line 5, it spawns an empty world. Then when you have launched it you want to throw in the guard_world which is the one with the multiple different colors and an object to project in the middle. Then you want to include the file of robots.launch because that is going to be spawning the robots.
For each robot, tell it to spawn. We need to say that it takes in a robot name and the init_pose. And then we would specify what node that it uses.
Within the robots.launch, we are going to have it spawn with specified position and name.
Basic Idea:
Guard object has a Twist() which will control the velocity of the robot. It also has a subscriber that subscribe to scan topic to receive LaserScan message and process the message in scan_cb() which is the callback function of the scan topic. The ranges field of the LaserScan message gives us an array with 360 elements each indicating the distance from the robot to obstacle at that specific angle. The callback function takes the ranges field of the LaserScan message, split into seven regions unevenly as shown below:
The minimum data of each region is stored in a dictionary. Then change_state function is called inside the scan_cb, which will check the region dictionary and update the intruder state as needed.
Work with real robot:
Dealing with signal noise
The laser scan on real robot is not always stable. Noisy data is highly likely to occur which can influence our intruder detection a lot. To avoid the influence of scan noise, we processed the raw ranges data to get a new ranges list which each element is the average of itself and 4 nearby elements in original ranges data. This data smoothing step can help us get a more reliable sensor data.
Sensor on real robot
The sensor of each robot is build differently. In gazebo, if nothing is scanned at that angle, inf is shown for the corresponding element in the ranges. However, some real-life robot have different LaserScan data. Nothing detected within the scan range will give a 0 in ranges data. To make our code work correctly on both Gazebo and real robot, please follow our comment in the code. There are only two lines of code that need to be changed.
Also, the laserScan data for Rafael has different number of elements. So the region division based on index is a little different for Rafael. We have different Python file for each robot, so this part is taken care of in line_F4.py which is only for Rafael.
A new message is created for our robots to communicate about intruder detection. The message contains four boolean values each associated with one of our guardbot. When a guardbot detects the intruder, a new message will be created with that associated boolean value set to True, and the new message will be published to a topic called see_intruder. Each robot also has a subscriber that subscribes to this topic and a callback function that will check the passed-in message and get the information about which robot is seeing the intruder.
The CMakeLists.txt and package.xml are also modified to recognize this newly created message.
We had to watch a lot of videos to figure out how to do this. We made an msg file which stored the type of data that we will hold which are boolean values on if the robot sees an intruder. We had to edit the cmake file and then had to edit the xml because we need to say that there is this new created message that the robots may communicate with and then have these structure look through the folder to see how it is created.
We need our own messades and tonics for the rohots to communicate. Here are the new messages:
see intruder: the message contains four std msgs/Boolean, each associated with a specific robot. When an intruder is detected by one robot. its' associated Boolean will be set to True. Only one robot can be true.
stop order: the message contains a list of std_msgs/String which would record the name of the robots in the stop order, and an std msas/Int8 which would record the current index of the list for the next stop or move.
Here is a chart talking about what we are interested in:
Here are the links that we used quite a lot: https://wiki.ros.org/ROS/Tutorials/CreatingMsgAndSrv https://www.theconstructsim.com/solve-error-importerror-no-module-named-xxxx-msg-2/
This project does not end here, there is a lot more that we can add. For an example here are a couple of other features that cam be added:
Having more sides so that there is faster converage
Making it run faster and still be as accurate with its patrolling
Finding a better system so that it does not need the order ahead of time if possible
Try to make it so that the robots all patrolling around instead of it being on a single like
Adding extra technologies where robots are connecting to like an Alexa can tell them to stop
Add a way to have it be stopped by human input and have it overrided
We feel like as a team we suceeded a lot in this project. We had great communication and determination that makes us such good teammates. We did not know each other before doing this project and at the beginning of the week we were a bit hesitant. We
👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻👩💻
The home above is divided into four security zones.
We can think of them as a sequence, ordered by their importance: [A, B, C, D].
If we have n live robots, we want the first n zones in the list to be patrolled by at least one robot.
n== 2 → patrolled(A, B);
n == 3 → patrolled(A, B, C)
1 <= n <= 4
The goal is for this condition to be an invariant for our program, despite robot failures.
Let robotz refer to the robot patrolling zone Z.
Illustration:
n == 4 → patrolled(A, B, C, D)
robotA dies
We need to:
map the home
SLAM (Simultaneous Localization and Mapping) with the gmapping package
have multiple robots patrol the security zone in parallel
AMCL (Adaptive Monte Carlo Localization) and the move_base package
One thread per robot with a SimpleActionClient sending move_base goals
have the system be resilient to robot failures, and adjust for the invariant appropriately
Rely on Raft’s Leader Election Algorithm (‘LEA’) to elect a leader robot.
The remaining robots will be followers.
More on system resiliency:
The leader always patrols zone A, which has the highest priority.
On election, the leader assigns the remaining zones to followers to maintain the invariant.
Two points of entry: real_main.launch and sim_main.launch.
real_main.launch:
used for real-world surveillance of our home environment
runs the map_server with the home.yaml and home.png map files obtained by SLAM gmapping.
All robots will share this map_server
launches robots via the real_robots.launch file (to be shown in next slide)
launches rviz with the real_nav.rviz configuration
sim_main.launch:
used for simulated surveillance of gazebo turtlebot3_stage_4.world
works similarly to real_main.launch except it uses a map of stage_4 and sim_robots.launch to run gazebo models of the robots via tailored urdf files.
Based on Diego Ongaro et al. 2014, “In Search of an Understandable Consensus Algorithm”
The full Raft algorithm uses a replicated state machine approach to maintain a set of nodes in the same state. Roughly:
Every node (process) starts in the same state, and keeps a log of the commands it is going to execute.
The algorithm elects a leader node, who ensures that the logs are properly replicated so that they are identical to each other.
Raft’s LEA and log replication algorithm are fairly discrete. We will only use the LEA.
Background:
Each of the robots is represented as an mp (member of parliament) node.
mp_roba, mp_rafael, etc.
Each node is in one of three states: follower, candidate, or leader.
If a node is a leader, it starts a homage_request_thread that periodically publishes messages to the other nodes to maintain its status and prevent new elections.
Every mp node has a term number, and the term numbers of mp nodes are exchanged every time they communicate via ROS topics.
If an mp node’s term number is less than a received term number, it updates its term number to the received term number.
LEA:
On startup, every mp node is in the follower state, and has:
a term number; and
The election timeout feature is part of what enables leader resiliency in my code.
When a leader node is killed, one of the follower nodes time out and become the new leader.
roscore keeps a list of currently active nodes. So:
followers, before transitioning to candidate state, update their list of live mp nodes by consulting roscore.
leaders do the same via a follower_death_handler thread, which runs concurrently with main thread and the homage_request thread, and maintains the invariant.
The mp nodes are all running on the remote VNC computer, which also runs the roscore.
So killing the mp node is just a simulation of robot failure, not true robot failure.
We’re just killing a process on the vnc computer, not the robot itself
We can remedy this by binding the mp node’s life to any other nodes that are crucial to our robot fulfilling its task.
E.g., for our project the /roba/amcl and /roba/move_base nodes are critical.
So we can consult roscore periodically to see if any of these nodes die at any given point. And if they do, we can kill mp_roba.
Running each mp node on its corresponding robot is a bad idea!
Only if a robot gets totally destroyed, or the mp process fails, will the algorithm work.
Performance will take a hit:
Our system has a single point of failure; the VNC computer running roscore.
So we have to keep the VNC safe from whatever hostile environment the robots are exposed to.
Maybe this can be remedied in ROS2, which apparently does not rely on a single roscore.
Our patrol algorithm is very brittle and non-adversarial
Depends on AMCL and move_base, which do not tolerate even slight changes to the environment, and which do not deal well with moving obstacles.
There are no consequences to disturbing the patrol of the robots, or the robots themselves (e.g. no alarm or ‘arrests’)
The LEA is fairly modular, and the algorithm can be adapted to tasks other than patrolling.
It would work best for tasks which are clearly ordered by priority, and which are hazardous, or likely to cause robot failures.
Completely fanciful scenarios:
Drone strikes: Maybe certain military targets are ordered by priority, and drones can be assigned to them in a way that targets with a higher priority receive stubborn attention.
Planetary exploration: Perhaps some areas of a dangerous planet have a higher priority that need to be explored than others. Our system could be adapted so that the highest priority areas get patrolled first.
James Lee (leejs8128@brandeis.edu)
A special thanks to Adam Ring, the TA for the course, who helped with the project at crucial junctures.
Github repo: https://github.com/campusrover/COSI119-final-objectSorter
This Object Sorter robot uses qrcode/fiducial detection and color detection to find cans and then pick them up with a claw and drop them off at designated sorted positions. In this implementation, the robot is mobile and holds a claw for grabbing objects. The robot executes a loop of finding an item by color, grabbing it, searching for a dropoff fiducial for the correct color, moving to it, dropping it off, and then returning to its pickup fiducial/area.
The project runs via the ros environment on linux, requires some publically available ros packages (mostly in python), and runs on a custom "Platform" robot with enough motor strength to hold a servo claw and camera. Ros is a distributed environment running multiple processes called nodes concurrently. To communicate between them, messages are published and subscribed to. The robot itself has a stack of processes that publish information about the robot's state, including its camera image, and subscribes to messages that tell it to move and open and close the claw.
Our project is divided up into a main control node that also includes motion publishing, and two nodes involved with processing subscribed image messages and translating them into forward and angular error. These are then used as inputs to drive the robot in a certain direction. The claw is opened and closed when the color image of the soda can is a certain amount of pixel widths within the camera's image.
The project runs in a while loop, with different states using control from the two different image platforms at different states until it is finished with a finished parameter, in the current case, when all 6 cans are sorted after decrementing.
Our plan for this project is to build a robot that will identify and sort colored objects in an arena.
These objects will be a uniform shape and size, possible small cardboard boxes, empty soda cans, or another option to be determined. The robot will be set up in a square arena, with designated locations for each color.
Upon starting, The robot will identify an object, drive towards it, pick it up using the claw attachment, and then navigate to the drop off location for that color and release it. It will repeat this until all the objects have been moved into one of the designated locations.
Color detection robots and robotic arms are a large and known factor of industrial workflows. We wanted to incorporate the image detection packages and show its use in a miniature/home application.
The project has been realized almost exactly to the specifications. We found that a bounding arena was not neccesary if we assumed that the travelling area was safe to the robot and the project. This implementation melds two detection camera vision algorithms and motion control via error feedback loop.
The current version uses three cans of two different colors, sorts the 6 cans, and finishes. We found some limitations with the project, such as network traffic limiting the refresh information of the visual indicators.
The first vision algorithm is to detect fiducials, which look like qr codes. The fiducials are printed to a known dimension so that the transformation of the image to what is recognized can be used to determine distance and pose-differential. The aruco_detect package subscribes to the robot's camera image. It then processes this image and returns an array of transforms/distances to each fiducial. The package can recognize the distinctness between fiducials and searches for the correct one neede in each state. The transform is then used to determine the amount of error between then robot and it. Then the robot will drive ion that direction, while the error is constantly updated with new processed images. (See Section: Problems that were Solved for issues that arose.)
The second vision algorithm is to detect color within the bounds of the camera image. The camera returns a color image, and the image is filtered via HSV values to seek a certain color (red or green). A new image is created with non-filtered pixels (all labelled one color) and the rest is masked black. A contour is drawn around the largest located area. Once the width of that contour is a large enough size in the image, the claw shuts. The processing thus can detect different objects, and the robot will go towards the object that is the clsoest due to its pixel count. (See Section: Problems that were Solved for issues that arose.)
The above picture shows (starting with the upper most left picture and going clockwise):
A centroid (light blue dot) that is in the middle of the colored can of which is used as a target for the robot to move towards. The centroid is calcuated using the second vision algorithm by calculating the middle of the contour that is drawn around the largest located area.
The contour that is drawn around the largest located error.
The image that is created with one color isolated and all other colored pixels masked in black.
Our project is to get a platform robot with a claw mount to sort soda cans into two different areas based on color. The test area is set up with two fiducials on one side and one fiducial on the other, approximately 2 meters apart. The two fiducials are designated as the red and green drop-off points, and the one is the pickup point. Six cans are arranged in front of the pickup point with the only requirements being enough spacing so the robot can reverse out without knocking them over, and a direct path to a can of the color the robot is targeting (e.x. so it doesn’t have to drive through a red can to get to a green one). The robot starts in the middle of the area facing the pickup point.
The robot’s behavior is defined by three states, “find item,” “deliver item,” and “return to start.” For “find item” the robot uses computer vision to identify the closest can of the target color, and drive towards it until it is in the claw. Then it closes the claw and switches state to “deliver item.” For this state, the robot will rotate in place until it finds the fiducial corresponding to the color of can it is holding, then drive towards that fiducial until it is 0.4 meters away. At that distance, the robot will release the can, and switch to “return to start.” For this last state, the robot will rotate until it finds the pickup fiducial, then drive towards it until it is 1 meter away, then switch back to “find item.” The robot will loop through these three states until it has picked up and delivered all the cans, which is tracked using a decrementing variable.
This project consists of three main nodes, each with their own file, main_control.py, contour_image_rec.py, and fiducial_recognition.py.
contour_image_rec.py uses the raspicam feed to calculate the biggest object of the target color within the field of view, and publishes the angle necessary to turn to drive to that object. It does this by removing all pixels that aren’t the target color, then drawing a contour around the remaining shapes. It then selects the largest contour, and draws a rectangle around it. After that it calculates the middle of the rectangle and sends uses the difference between that and the center of the camera to calculate the twist message to publish.
Fiducial_recognition.py just processes the fiducials and publishes the transforms.
main_control.py subscribes to both of the other nodes, and also contains the behavior control for the robot. This node is in charge of determining which state to be in, publishing twist values to cmd_vel based on the input from the other nodes, and shutting the robot down when the cans are all sorted.
Prod_v5.launch is our launch file, it starts the main_control node, the image recognition node, the fiducial recognition node, and the aruco_detect node that our fiducial recognition node relies on.
We wanted to do a project that had relatable potential and worked on core issues with robotics. Settling on this topic, we found that having to integrate two different camera algorithms provided a higher level of interest. In deciding to sort cans, we liked that these were recognizable objects. It was hoped that we could detect based on the plain color of the cans, Coke, Canada Dry Raspberry, Sprite, AW Root Beer. For simplicity, we did tape the tops of the green cans to give more consistency, but it was noted that the Sprite cans would work well still with some minor tweaking.
For motion control, using the direct error from the two detected objects provided reasonable levels of feedback. We put the components into a state controller main node, and then wrapped all the camera outputs, nodes into a single launch node. The launch node also automatically starts aruco_detect.
We worked collaboratively on different parts of the project together. We slowly got piece by piece working, then combined them together into a working roslaunch file. We focused on creating a working production launch file and continued to work on an in-progress one for new material. By breaking down the porject into separate parts, we were able to work separately asynchronously, while meeting up to collaborate on the design of the project. It was a great time working with the other members.
Collecting aruco_detect, rqt_image_view, main_control, fiducial_recognition, contour_image_rec into one file. Controlling version for production.
Considering alternate control flows: behavior trees, finite state machines (not used).
Getting fiducial recognition to work, move and alternate between different fiducials.
Detecting and masking by HSV range, contouring the largest clump, bounding that with a rectangle, sending a centroid.
Grabbing cans with the claw (sending/recieving servo commands), using the width of the rectangle to time closing of the claw.
Developing a loop control between states.
Troubleshooting physical problems, such as the cans blocking the fiducial image.
Fidicial-based issues: Recognition only worked to a certain distance, after that, the image resolution is too low for certainty. To resolve this, we allowed the bounds of the project to remain within 3 meters.
Network traffic (more other robots/people) on the network would introduce significant lag to sending images across the network from the robot to the controlling software (on vnc on a separate computer). This would cause things such as overturning based on an old image, or slow loading of the fiducial recognition software. This can be worked around by: a. increasing the bandwidth related to the project, b. buffering images, c. reducing the size or performing some calculations on the robot's Raspberry Pi chip (this is limited by the capacity of that small chip), d. changing and reducing speed parameters when network traffic is high manually (allowing less differential between slow images and current trajectory).
Positions where the entirely of the fiducial is too close and gets cropped. Fiducial recognition requires the entire image to be on screen. This information can be processed however and saved, either as a location (which can be assessed via mapping) or as previous information of error. To combat this issue, we raised the positions of the fiducials so that they could be seen above the carried soda can and had the drop off point at 0.4m away from the fiducial.
Color-based issues: Different lighting conditions (during night vs day coming in from the window) affect color detection. Therefore it is best to get some colors that are very distinct and non-reflective (becomes white). Thus red and green. Another issue that would arise is if the robot approaches the cans from the side and the can remains on the side, then the width might not increase enough to close the claw. Some conditional code can be used to clode the claw with smaller width if the contour is in some part of the screen.
Other/Physical issues: The platform robot is a big chonker! It also has meaty claws. The robot being large causes it to take up more room and move farther. In the process it sometimes will knock over other features. To combat this, we added a reversing -0.05m to the turning motion when the robot begins to switch to seeking a dropoff fiducial. The meaty claws is one of the causes of requiring a larger robot with stronger motors.
In sum, we had an enjoyable time working with our Platform Robot, and it was great to see it complete its task with only the press of a single button. The autonimity of the project was a great experience.
For our final project, we wanted to create a dynamic and intuitive project that involved more than one robot. To challenge ourselves, we wanted to incorporate autonomous robots. As the technology for self-driving cars continues to advance, we are curious about the process involved in creating these vehicles and wanted to explore the autonomous robot development process. To explore this further, we have come up with the concept of a race between two autonomous robots. The goal for this project was to program robots into racing in the track indefinitely all while following certain rules and avoiding obstacles throughout the track.
Our main objective is for the robots to autonomously move itself in the race track with 2 lanes (4 lines) avoiding any collision. The plan was to do so by following the center of a lane made by 2 lines, slowing down, and switching into a different lane. We were able to use the contour system to detect multiple objects within a mask and draw centroids on them. For our purposes we wanted it to detect the two lines that make up the lane. With the centroids we could calculate the midpoint between the lines and follow that. We got a prototype running, however it struggled to turn corners. For the sake of time we pivoted to only following one line per robot. The current Robot Race is an algorithm that allows two autonomous robots to race each other, collision free, on a track with two lines, speed bumps, and obstacles along the way.
We designed our code to have the robot recognize a line by its color and follow it. While it is doing that it is also looking for yellow speed bumps along the track. When it detects yellow on the tract the robot will slow down until it passes over the speed bump. Furthermore, when the robot detects an obstacle in front of it, it will switch lanes to move faster avoiding the obstacle.
The main package that drives our project is the opencv stack. This contains a collection of tools that allow us to use computer vision to analyze images from the camera on the robot. We used the CV bridge package to process the images. As the name suggests CV bridge allows us to convert the ROS messages into OpenCV messages. The camera onboard the robot publishes the images as ROS messages into different types of CV2 images. For our use case, we converted the images from the camera into color masks. To create the color masks we used the HSV color code to set upper and lower bounds for the range of colors we want the mask to isolate. For example, for red the lower bound was: HSV [0,100,100] and the upper bound was: HSV [10,255,255]. The mask will then block out any color values that are not in that range.
Figure 1
To figure out the color code we had to calibrate the camera for both robots using the cvexample.py file with the RQT app to adjust the HSV mask range live. After that we convert the color mask to a grayscale image and it's ready for use.
We created masks for the green and red lines that the robot will follow and the yellow speed bumps scattered along the track. We set each robot to follow a specific line and also be scanning for yellow at the same time. This was achieved by drawing centroids on the line (red or green) for the robot to follow.
We also use lidar in our project. Each robot is scanning the environment for obstacles. The robots have the ability to switch lanes by swapping the red and green masks out when it detects an obstacle on the track with lidar. We subscribed to the laser scan topic to receive ros messages from the equipped Lidar sensor. After some testing and experimenting we decided If It detects an object within 1.5 meters of the front of the robot it will switch lanes. We had to make sure that the distance threshold was far enough for the robot to switch lanes before crashing but not too far to detect the chairs and tables in the room.
Clone our repository: “git clone https://github.com/campusrover/robot_race.git”
ssh into two robots for each robot run:
Go into vnc and run roslaunch robot_race follow_demo.launch
This should get the robots to move on their respective lines.
Launch File Follow_demo.launch - The main launch file for our project
Nodes Follow.py - main programming node
At the very beginning, we were dancing with the idea of working on two robots and having them follow the traffic rules as they start racing on the track for our final project. However, as we started learning more about image processing and worked on the line following PA, we wanted to challenge ourselves to work with two autonomous robots. With the autonomous robots in mind, we then decided to discard the traffic lights and just create a simple track with speed bumps and walls on the lanes.
We faced many problems throughout this project and pivoted numerous times. Although the project sounds simple, it was very difficult to get the basic algorithm started. One of our biggest challenges was finding a way for the robot to stay in between two lanes. We tried to use the HoughLines algorithm to detect the lines of our lanes, however, we found it extremely difficult to intricate our code as HoughLines detected odd lines outside of our track. When HoughLines didn’t work, we pivoted to using a contours-based approach. Contours allow you to recognize multiple objects in a mask and draw centroids on them. We used this to draw centroids on the two lines and calculated the midpoint in between two lines for the robot to follow. While we were successful in creating a centroid in between the lines for the robot to follow on the gazebo, when we tried to run the program on the actual robot, the robot did not stay in between the two lanes when it needed to turn a corner(Figure 2). At last, we pivoted and decided to replace the lanes with two different tapes, red and green, for the robots to follow.
Figure 2
Furthermore, we wanted to create an actual speed bump using cardboards but we soon realized that would be a problem since we wanted to use the small turtle bots for our project and they were unable to slow down and go up the speed bump. Furthermore, the lidars are placed at the top of the robot and there is little to no space at the bottom of the robot to place a lidar. A solution we came up with was to use yellow tape to signal speed bumps.
Once we were able to get the robots to follow the two lines, we had difficulty getting the robot to slow down when it detected the speed bump. We had separated the main file and the speed bump detector file. The speed bump detector file created a yellow mask and published a boolean message indicating if yellow was detected in the image. After discussing it with the TA and some friends from class we found out that we could not pass the boolean messages from the speedbump node to the main file without changing the xml file. We originally planned to do the same for object detection but did not want to run into the same problem. Our solution was to combine everything into one file and the speed bump and object detector nodes became methods.
Overall, we consider this project to be a success. We were able to create and run two autonomous robots simultaneously and have them race each other on the track all while slowing down and avoiding obstacles. Although we faced a lot of challenges along the way, we prevailed and were able to finish our project on time. The knowledge and experience gained from this project are invaluable, not only in the field of self-driving cars but also in many other areas of robotics and artificial intelligence. We also learned the importance of teamwork, communication, and problem-solving in the development process. These skills are highly transferable and will undoubtedly benefit us in our future endeavors.
Team: Peter Zhao (zhaoy17@brandeis.edu) and Veronika Belkina (vbelkina@brandeis.edu)
Date: May 2022
Github repo: https://github.com/campusrover/litter-picker
The litter picker was born from a wish to help the environment, one piece of trash at a time. We decided on creating a robot that would wander around a specified area and look for trash using a depth camera and computer vision. Once it had located a piece of trash, it would move towards it and then push it towards a designated collection site.
Be able to localize and move to different waypoints within a given area
Capable of recognizing object to determine whether the object is trash
Predict the trash's location using depth camera
In the summary of Nodes, Modules, and External Packages we show the corresponding tables with the names and descriptions of each file. Afterwards, we go into a more detailed description of some of the more important files within the program.
We created a variety of nodes, modules, and used some external packages while trying to determine the best architecture for the litter picker. The following tables (Table 1, 2, 3) show descriptions of the various files that are separated into their respective categories. Table 4 shows the parameters we changed so that the robot moves more slowly and smoothly while navigating using move_base.
Table 1: Description of the ROS Nodes
Table 2: Description of our python modules used by the above nodes
Table 3: External packages
Table 4: Parameters changed within the navigation stack file: dwa_local_planner_params_waffle.yaml
To simplify what information is being published and subscribed to, we created a custom message called Trash which includes three variables. A boolean called has_trash which indicated whether or not there is trash present. A float called err_to_center which returns a number that indicates how far from the center to the bounding_box center is. And a boolean called close_enough which will be true if we believe that the trash is at a reasonable distance to be collected, otherwise it will be false. These are used in the Rotation and Trash_localizer classes to publish the appropriate cmd_vel commands. It is under the message topic litter_picker/vision.
The vision node has several methods and callback functions to process the messages from the various topics it subscribes to and then publish that information as a Trash custom message.
Image 1: Display of the darknet_ros putting a bounded box around the identified object
darknet_ros is the computer vision package that looks for the types of trash specified in the trash_class.py. We want to be able to find things like bottles, cups, forks, and spoons that are lying around. This package integrates darknet with ros for easier use. We then subscribe to the darknet_ros/bounding_boxes topic that it publishes to and use that to to determine where the trash is.
Image 2: A diagram to show the setup of the Task interface and its children classes
The Task interface contains its constructor and two other methods, start() and next(). When a Task instance is initiated, it will take in a state in the form of the LitterPickerState class which contains a list of waypoints and the current waypoint index. The start() method is where the task is performed and the next() method is where the next Task is set. We created three Task children classes called Navigation, Rotation, and TrashLocalizer which implemented the Task interface.
The Navigation class communicates with the navigation stack. In start(), it chooses the current waypoint and sends it to move_base using the move base action server. If the navigation stack returns that it has successfully finished, the has_succeed variable of the Navigation class will be set to true. If the navigation stack returns that it has failed, has_succeed will be set to false. Then when the next() method is called and if has_succeed is true, it will update the waypoint index to the next one and return a Rotation class instance with the updated state. If has_succeed is false, it will return an instance of the Navigation class and attempt to go to the same waypoint again.
The Rotation class publishes a cmd_vel command for a certain amount of time so that the robot will rotate slowly. During this rotation, the camera and darknet_ros are constantly looking for trash. The Rotation class subscribes to the Trash custom message. In the start() method, it looks at the has_trash variable to check if there is any trash present while it is rotating. If there is, then it will stop. In the next() method, it sets has_trash is true, then it will set the next task instance to be the TrashLocalizer task. Otherwise, it will set it to a Navigation task.
The TrashLocalizer class also subscribes to the Trash custom message. In the start() method, it publishes cmd_vel commands to move towards the trash and collect it in the plow. It uses the boolean close_enough to determine how far it has to go before before stopping. Then it sees if it sees that there is still a bounding box, it will use the trap_trash() method to move forward for a specified amount of time.
The master node has a class called LitterPicker which coordinates the Tasks as the robot executes them. There is a constructor, an execute() method, and a main method within it. It also includes the LitterPickerState class which contains a list of all the waypoints and an index for the current waypoint. The constructor takes in a Task and a LitterPickerState and two variables are initialized based on those two: current_task and state.
In the execute() method, there are two lines, as you can see below. The first line starts the execution of the current_task and the second line calls the next function of the current_task so that it can decide which Task should be executed next.
The main function initializes the node, creates an instance of the LitterPickerState using the waypoints file, creates an instance of the LitterPicker class using that state and a NavigationTask class. Then in the while not rospy.is_shutdown loop, it runs the execute() function.
If you wish to change the map file to better suit your location, then you can edit the map file (in <arg name = "map_file"...>) inside the litter_picker.launch, as well as change the initial position of the robot.
You can also edit the new_map_waypoints.txt file in the waypoints folder to match the coordinates that you would like for the robot to patrol around that should be in the following format:
When you ssh onto the robot, you will need to run bringup.
You will also need to run rosrun usb_cam usb_cam_node onboard the robot as well to initialize the depth camera's rgb stream.
Then enter roslaunch litter-picker litter_picker.launch. The program should launch with a few windows: rviz and YOLO camera view.
There were many challenges that we faced with this project, but let’s start from the beginning. At the start, we had tried to divide the work more so that we can create functionality more efficiently. Peter worked on finding a computer vision package that could create and creating the corresponding logic within the rotation node as well as creating the master node and implementing action lib when we had been using it. Veronika worked on creating the map and integrating the navigation stack into the program, installing the depth camera, and using it to localize the trash. Once we created most of the logic and were trying to get things to work, we became masters of pair programming and debugging together and for the rest of the project, we mainly worked together and constantly bounced ideas off each other to try and solve problems.
In the beginning, we had started with a simple state system using the topic publisher and subscriber way of passing information between nodes, however, that quickly became very complicated and we thought we needed a better way to keep track of the current state. We chose to use the actionlib server method which would send goals to nodes and then wait for results. Depending on the results, the master node would send a goal to another node. We also created a map of the area that we wanted to use for our project. Then we incorporated the AMCL navigation system into our state system. We decided that moving from waypoint to waypoint would be the best way to obtain the benefits of AMCL such as path planning and obstacle avoidance. This was a system that we kept throughout the many changes that we underwent throughout the project.
However, when we tested it with the ROS navigation stack, things did not work as expected. The navigation would go out of control as if something was interfering with it. After some testing, we concluded that the most likely cause of this was the actionlib servers, however we were not completely sure why this was happening. Perhaps the waiting for results by the servers was causing some blocking effect to the navigation stack.
We ended up completely changing the architecture of our program. Instead of making each task as a separate node, we made them into python classes where the master node can initiate different actions. The reason for this change is that we felt that the tasks does not have to be running in parallel, so a more linear flow would be more appropriate and resource-efficient. This change greatly simplified our logic and also worked much better with the navigation stack. We also edited some parameters which has been previously described within the navigation stack that allowed for the robot to move more smoothly and slowly.
Initially, we had wanted to train our computer vision model using the TACO dataset. However, there was not enough data and it took too long to train so we ended up choosing the pretrained yolo model that has some object classes such as bottle, cup, fork, and spoon that could be identified as trash. The YOLO algorithm and integrated with ros through the darknet_ros package as mentioned above. We had to make some changes to the darknet_ros files so that it could take in CompressedImage messages.
Close to the beginning of the project, we had set up the . The story of the depth camera is long and arduous. We had begun the trash_localizer node by attempting to calculate a waypoint that the navigation stack could move to by determining the distance to the identified object and then calculating the angle. From there, we used some basic trigonometry to calculate the amount that needed to be traveled in the x and y directions. However, we found that the angle determined from the depth camera did not correspond with reality and therefore the waypoint calculated was not reliable. The next method we tried was to use the rotation node and stop the rotation when the bounding box was in the center and then use a pid controller to move towards the trash using the distance returned from the depth camera. There were several problems with that such as the bounding box being lost, but in general, this method seemed to work. Since we did most of this testing in Gazebo due to the LiDAR on Alien being broken, we didn't realize that we actually had an even larger problem at hand...
When we started to test the depth camera on the actual robot in a more in depth manner, we realized that it was not returning reliable data with the method that we had chosen. We started to explore other options related to the depth stream but found that we did not have enough time to fully research those functionalities and integrate it in our program. This is when we decided pivot once again and not use the depth part of the depth camera. Instead we used the position of the bounded box in the image to determine whether the object was close enough and then move forward.
There was a robotic arm in the original plan, however, due to the physical limitations of both the arm, the robot, and time constraints, we ended up deciding to use a snow plow system instead. We had several ideas of having a movable one, but they were too small for the objects that we wanted to collect so we created a stationary one out of cardboard and attached it to the front of the robot. It works quite well with holding the trash within its embrace.
Image 3: Alien with the Astra depth camera on top and the plow setup below posing for a photo
This project was much more challenging than we had anticipated. Training our own data and localizing an object based on an image and bounded box turned out to be very difficult. Despite the many problems we encountered along the way, we never gave up and persisted to present something that we could be proud of. We learned many lessons and skills along the way both from the project and from each other. One lesson we learned deeply is that a simulator is very different from the real world. Though for a portion of the time, we could only test simulator due to a missing LiDAR on our robot, it still showed the importance of real world testing to us. We also learned the importance of reasoning through the project structure and logic before actually writing it. Through the many frustrations of debugging, we experienced exciting moments of when something worked properly for the first time and then continued to work properly the second and third times.
In conclusion, we were good teammates who consistently showed up to meetings, communicated with each other, spent many hours working side by side, and did our best to complete the work that we had assigned for ourselves. We are proud of what we have learned and accomplished even if it does not exactly match our original idea for this project.
This project began as an effort to improve the localization capabilities of campus rover as an improvement to lidar based localization. Motivating its conception were the following issues: Upon startup, in order to localize the robot, the user must input a relatively accurate initial pose estimate. After moving around, if the initial estimate is good, the estimate should converge to the correct pose.
When this happens, this form of localization is excellent, however sometimes it does not converge, or begins to diverge, especially if unexpected forces act upon the robot, such as getting caught on obstacles, or being picked up. Furthermore, in the absence of identifiable geometry of terrain features, localization may converge to the wrong pose, as discussed in . While the article may discuss aerial vehicles, the issue is clearly common to SLAM.
One solution incolves fiducials, which are square grids of large black and white pixels, with a bounding box of black pixels that can be easily identified in images. The pattern of pixels on the fiducial encodes data, and from the geometry of the bounding box of pixels within an image we can calculate its pose with respect to the camera. So, by fixing unique fiducials at different places within the robot's operating environment, fixed locations can be used to feed the robot accurate pose estimates without the user needing to do so manually.
Fiducial SLAM is not a clearly defined algorithm. Not much is written on it specifically, but it is a sub-problem of SLAM, on which a plethora of papers have been written. In the authors discuss how Fiducial SLAM can be seen as a variation of Landmark SLAM. This broader algorithm extracts recognizable features from the environment and saves them as landmarks, which is difficult with changes in lighting, viewing landmarks from different angles, and choosing and maintaining the set of landmarks.
If successful, using landmarks should be allow the robot to quickly identify its pose in an environment. Fiducial SLAM provides a clear improvement in a controlled setting: fiducials can be recognized from a wide range of angles, and given that they are black and white, are hopefully more robust to lighting differences, with their main downside being that they must be manually placed around the area. Therefore, the goal of this project was to use fiducial markers to generate a map of known landmarks, then use them for localization around the lab area. It was unknown how accurate these estimates would be. If they were better than lidar data could achieve, fiducials would be used as the only pose estimation source, if not, they could be used simply as a correction mechanism.
This project uses the ROS package , which includes the packages aruco_detect and fiducial_slam. Additionally, something must publish the map_frame, for which I use the package turtlebot3/turtlebot3_navigation, which allows amcl to publish to map_frame, and also provide the utility of visualizing the localization and provide navigation goals.
I used the raspberry pi camera on the robots, recording 1280x960 footage at 10 fps. Setting the framerate too fast made the image transport slow, but running it slow may have introduced extra blur into the images. Ideally the camera is fixed to look directly upwards, but many of the lab's robots have adjustable camera angles. The transform I wrote assumes the robot in use has a fixed angle camera, which was at the time on Donatello.
To set up the environment for fiducial mapping, fiducials should be placed on the ceiling of the space. There is no special requirement to the numbering of the fiducials, but I used the dictionary of 5x5 fiducials, DICT_5X5_1000, which can be configured in the launch file. They do not need to be at regular intervals, but there should not be large areas without any fiducials in them. The robot should be always have multiple fiducials in view, unless it is pressed up against a wall, in which case this is obviously not practical. This is because having multiple fiducials in view at once provides a very direct way to observe the relative position of the fiducials, which fiducial_slam makes use of. Special attention should be made to make sure the fiducials are flat. If, for example, one is attached on top of a bump in the ceiling, it will change the geometry of the fiducial, and decrease the precision with which its pose, especially rotation, can be estimated by aruco_detect.
Before using the code, an accurate map generated from lidar data or direct measurements should be constructed. In our case we could use a floor plan of the lab, or use a map generated through SLAM. It does not matter, as long as it can be used to localize in with lidar. Once the map is saved, we can begin constructing a fiducial map. First, amcl should be running, to publish to map_frame. This allows us to transform between the robot and the map. We must also know the transform between the robot and the camera, which can be done with a static transform I wrote, rpicam_tf.py. aruco_detect provides the location of fiducials in the camera's frame. Then we run fiducial_slam, which can now determine fiducial's locations relative to the map_frame. We must pay special attention to the accuracy of amcl's localization while constructing the fiducial map. Although the purpose of this project is to prevent the need to worry about localization diverging, at this stage we need to make sure the localization is accurate, at least while the first few fiducials are located. The entire area should be explored, perhaps with teleop as I did.
The fiducial_slam package was clearly the most important part of this project, but after using it, I realize it was also the biggest problem with the project, so I am dedicating this section to discussing the drawbacks to using it and how to correct those, should anyone want to try to use fiducial SLAM in the future.
The package is very poorly documented. Its contains very little information on how it works, and how to run it, even if one follows the link provided. The information on how to run the packages at a very basic level is incomplete, since it does not specify that something must publish to map_frame for the packages to function.
The error messages provided are not very helpful. For example, when fiducial_slam and aruco_detect are run without amcl publishing to move base, they will both appear to work fine and show no errors, even though the rviz visualization will not show a camera feed. There is another error I received which I still have not solved. Upon launching the fiducial_slam package, it began crashing, and in the error message there was only a path to what I assume to be the source of the error, which was the camera_data argument, as well as a C++ error which related to creating an already existent file, with no information about which file that is. However, when I checked the camera_data argument, and even changed the file so I did not provide that parameter, the same error specifying a different path showed up. Note that upon initially trying to use the package, I did not specify the camera_data argument and this error did not appear, which suggests that parameter was not actually the problem. Issues like these are incredibly difficult to actually diagnose, making the use of the package much more challenging than it should be.
Code documentation is poor, and even now I am unsure which variety of SLAM the code uses. Compare to the previously mentioned on TagSLAM, which clearly indicates the algorithm uses a GTSAM nonlinear optimizer for graph-based slam. TagSLAM is a potential alternative to fiducial_slam, although as I have not tested its code, I can only analyze its documentation. I think TagSLAM would be much easier to use than fiducial_slam, or perhaps some other package I have not looked at. It may also be possible for a large team (at least three people) to implement the algorithm themselves.
The original learning goal of this project was for me to better understand how fiducial detection works, and how SLAM works. Instead, my time was mostly spent discovering how the fiducial_slam package works. My first major issue was when trying to follow the tutorial posted on the ROS wiki page. I wasn't given any error messages in the terminal window running fiducial_slam, but noticed that rviz was not receiving camera data, which I assumed indicated that the issue was with the camera.
After much toil and confusion, it turned out that for some reason, the data was not passed along unless something published to move_base. I did not originally try to run the packages with amcl running because I wrongly assumed that the package would work partially if not all parameters were provided, or at least it would give error messages if they were necessary. After solving that problem, I encountered an issue with the camera transforms, which I quickly figured out was that there was no transform between base_link and the camera. I solved this with a static transform publisher, which I later corrected when fiducial_slam allowed me to visualize where the robot thought observed fiducials were. Once I was mapping out fiducial locations, I believed that I could start applying the algorithm to solve other problems. However, overnight, my code stopped working in a way I'm still confused about. I do not remember making any modifications to the code, and am not sure if any TAs updates the campus rover code in that time in a way that could make my code break. After trying to run on multiple robots, the error code I kept getting was the fiducial_slam crashed, and that there was some file the code attempted to create, but already existed. Even after specifying new map files (which didn't yet exist) and tweaking parameters, I could not diagnose where the error was coming from, and my code didn't work after that.
In hindsight, I see that my problem was choosing the fiducial_slam package. I chose it because it worked with ArTag markers, which the lab was already using, and I assumed that would make it simpler to integrate it with any existing code, and I could receive help from TAs in recognizing fiducials with aruco_detect. Unfortunately that did not make up for the fact that the fiducial_slam package wasn't very useful. So one thing I learned from the project was to pick packages carefully, paying special attention to documentation. Perhaps a package works well, but a user might never know if they can't figure out what the errors that keep popping up are.
**Fig 1. Traffic light examples****Fig 2a. Initial turn sign examples****Fig 2b. Revised turn sign examples****Milestone-1:** Be able to detect and recognize the signs in digital formats (i.e. jpg or png) downloaded online. No ROS work needs to be done at this stage.
**Milestone-2:** Complete all the fundamental functionalities, and be able to achieve what’s described in a simulation environment.
**Milestone-3:** Be able to carry out the tasks on a real robot in a clean environment that’s free of noises from other objects. We will use blocks to build the routes so that laser data can be used to make turns. We will print out images of traffic signs on A4 white paper and stick them onto the blocks. $(bru mode real)
$(bru name <robot name> -m <myvpnip>)
multibringuprobotB dies
n == 2 → patrolled(A, B)
robotA dies
n == 1 → patrolled(A)
The leader is responsible for maintaining the invariant among followers.
On leader failure:
global interrupts issued to all patrol threads (all robots stop).
the LEA elects a new leader
On follower failure:
local interrupts issued by leader to relevant patrol threads (some robots stop).
Example:
n==4 → patrol(A, B, C, D)
robotB dies
leader interrupts robotD
leader assigns robotD to zone B
n==3 → patrol(A, B, C)
a duration of time called the election timeout.
When a follower node receives no homage request messages from a leader for the duration of its election timeout, it:
increments its term number;
becomes a candidate;
votes for itself; and
publishes vote request messages to all the other mp nodes in parallel.
When a node receives a request vote message it will vote for the candidate iff:
the term number of the candidate is at least as great as its own; and
the node hasn’t already voted for another candidate.
Once a candidate mp node receives a majority of votes it will:
become a leader;
send homage request messages to other nodes to declare its status and prevent new elections.
The election timeout duration of each mp node is a random quantity within 2 to 3 seconds.
This prevents split votes, as it’s likely that some follower will timeout first, acquire the necessary votes, and become the leader.
Still, in the event of a split vote, candidates will:
reset their election timeout durations to a random quantity within the mentioned interval;
wait for their election timeout durations to expire before starting a new election.
bandwidth must be consumed for messages between mp nodes
robot’s computational load will increase











Provides some helper functions for the rest of the modules.
topics.py
A single place to store all the subscribed topics name as constants
trash_class
Contain the yolo classes that are considered trash
master.py
Coordinates the various tasks based on the current task's state
vision.py
Processes and publishes computer vision related messages. It subscribes to the bounding box topic, the depth camera, and rgb camera and publishes a Trash custom message that will be used by the Task classes to determine what to do.
task.py
Contains the interface which will be implemented by the other classes.
navigation.py
Contains the navigation class, which uses the waypoints state to navigate using the AMCL navigation package and updates the waypoints.
rotation.py
Includes the rotation class that publishes cmd_vel for the robot to rotate and look for trash.
trash_localizer.py
Has the trash localizer class, which publishes cmd_vel to the robot depending on information received from the vision node.
state.py
Holds the current state of the robot that is being passed around between the classes.
darknet_ros
Uses computer vision to produce bounding boxes around the trash.
navigation stack
Navigation stack for navigation and obstacle avoidance.
usb_cam
astra rgb camera driver
max_vel_theta
0.5
min_vel_theta
0.2
yaw_goal_tolerance
0.5
utils.py
OpenCV
ROS Kinetic (Python 2.7 is required)
A Camera connected to your device
Copy this package into your workspace and run catkin_make.
Simply Run roslaunch gesture_teleop teleop.launch. A window showing real time video from your laptop webcam will be activated. Place your hand into the region of interest (the green box) and your robot will take actions based on the number of fingers you show.
This package contains two nodes.
detect.py: Recognize the number of fingers from webcam and publish a topic of type String stating the number of fingers. I won't get into details of the hand-gesture recognition algorithm. Basically, it extracts the hand in the region of insteret by background substraction and compute features to recognize the number of fingers.
teleop.py: Subscribe to detect.py and take actions based on the number of fingers seen.
Using Kinect on mutant instead of local webcam.
Furthermore, use depth camera to extract hand to get better quality images
Incorporate Skeleton tracking into this package to better localize hands (I am using region of insterests to localize hands, which is a bit dumb).
bool has_trash
float32 err_to_center
bool close_enoughdef execute(self):
self.current_task.start()
self.current_task = self.current_task.next()<include file="$(find litter_picker)/launch/navigation.launch">
<arg name="initial_pose_x" default="-1.1083"/>
<arg name="initial_pose_y" default="-1.6427"/>
<arg name="initial_pose_a" default="-0.6"/>
<arg name="map_file" default="$(find litter_picker)/maps/new_map.yaml"/>
</include>-4.211, 1.945, 0
-4.385, 4.937, 0
-4.38, 4.937, 0
-7.215, 1.342, 0Three fingers: Turn left
Four fingers: Turn right
Other: Stop
while not rospy.is_shutdown():
twist = Twist()
if fingers == '2':
twist.linear.x = 0.6
rospy.loginfo("driving forward")
elif fingers == '3':
twist.angular.z = 1
rospy.loginfo("turning left")
elif fingers =='4':
twist.angular.z = 1
rospy.loginfo("turning right")
else:
rospy.loginfo("stoped")
cmd_vel_pub.publish(twist)
rate.sleep()



In Kinect.md, the previous generations dicussed the prospects and limitations of using a Kinect camera. We attempted to use the new Kinect camera v2, which was released in 2014.
Thus, we used the libfreenect2 package to download all the appropiate files to get the raw image output on our Windows. The following link includes instructions on how to install it all properly onto a Linux OS.
https://github.com/OpenKinect/libfreenect2
We ran into a lot of issues whilst trying to install the drivers, and it took about two weeks to even get the libfreenect2 drivers to work. The driver is able to support RGB image transfer, IR and depth image transfer, and registration of RGB and depth images. Here were some essential steps in debugging, and recommendations if you have the ideal hardware set up:
Even though it says optional, I say download OpenCL, under the "Other" option to correspond to Ubuntu 18.04+
If your PC has a Nvidia GPU, even better, I think that's the main reason I got libfreenect to work on my laptop as I had a GPU that was powerful enough to support depth processing (which was one of the main issues)
Be sure to install CUDA for your Nvidia GPU
Please look through this for common errors:
https://github.com/OpenKinect/libfreenect2/wiki/Troubleshooting
Although we got libfreenect2 to work and got the classifier model to locally work, we were unable to connect the two together. What this meant is that although we could use already saved PNGs that we found via a Kaggle database (that our pre-trained model used) and have the ML model process those gestures, we could not get the live, raw input of depth images from the kinect camera. We kept running into errors, especially an import error that could not read the freenect module. I think it is a solvable bug if there was time to explore it, so I also believe it should continued to be looked at.
However, also fair warning that it is difficult to mount on the campus rover, so I would just be aware of all the drawbacks with the kinect before choosing that as the primary hardware.
https://www.kaggle.com/gti-upm/leapgestrecog/data
https://github.com/filipefborba/HandRecognition/blob/master/project3/project3.ipynb
What this model predicts: Predicted Thumb Down Predicted Palm (H), Predicted L, Predicted Fist (H), Predicted Fist (V), Predicted Thumbs up, Predicted Index, Predicted OK, Predicted Palm (V), Predicted C
https://github.com/campusrover/gesture_recognition
Install OpenNI2 if possible
Make sure you build in the right location
A folder containing all the project reports
The following pages are each a project report by a student in Autonomous Robotics at Brandeis University. Here's how to add your content:
Git clone this repository to your computer: CampusRover Labnotebook
In the directory structure, find the folder called reports. In it find the .md file for your project. If you can't find it, then create it.
Write your project report using markdown. You can include images as well as links. There are many tutorials on Markdown but you most likely already know it.
Git add, commit and push your changes
If you did it right then they will appear in the
What is a better use of a robot than to do your homework for you? With the surging use of ChatGPT among struggling, immoral college students, we decided to make cheating on homework assignments even easier. Typinator is a robot that uses computer vision and control of a robotic arm to recognize a keyboard, input a prompt to ChatGPT, and type out the response.
Demonstrate the robotic arm by having it type its own code. The arm will hold an object to press keys with. The robot will hopefully write code quickly enough so that people can watch it write in real time. The robot could also type input to chatgpt, and have a separate program read the output to the robot. It will then cmd+tab into a document and type the answer. Both of these demonstrations will show the arm “doing homework,” which I think is a silly butchallenging way to demonstrate the robot’s capabilities.
The goal of this project is to demonstrate the capability of the robotic arm in conjunction with computer vision.
While the end result of the project is not actually useful in a real world setting, the techniques used to produce the end result have a wide variety of applications. Some of the challenges we overcame in computer vision include detecting contours on images with a lot of undesired lines and glare, reducing noise in contoured images, and transforming image coordinates to real world coordinates.
Some of the challenges we overcame in using a robotic arm include moving to very specific positions and translating cartesian coordinates to polar coordinates since the arm moves by rotating. We also worked extensively with ROS.
Text Publishing
Publish large chunks of text with ROS
Clean text into individual characters that can be typed
The project works by having a central coordinating node connect arm motion, image recognition, keyboard input, and text input. All of these functionalities are achieved through ROS actions except for the connection to the keyboard input, which is done through a simple function call (coordinator --> keys_to_type_action_client). Our goal with designing the project in this way was to keep it as modular as possible. For example, the chatgpt_connection node could be replaced by another node that publishes some other text output to the generated_text ROS topic. A different arm_control node could be a server for the arm_control action if a different robotic arm requiring different code was used. Any of the nodes connected with actions or topics could be substituted, and we often used this to our advantage for debugging.
Arm motion diagram
As shown above, the arm moves with rotation and extension to hover above different keys. To achieve this movement from a flat image with (x,y) coordinates, we converted the coordinates of each key into polar coordinates. From (x,y) coordinates in meters, the desired angle of the arm is determined by $θ=atan(x/y)$. The desired extension from the base of the arm is found by $dist=y/cos(θ)$. We calculate this relative to the current extension of the arm so $Δdist=dist-currentDistance$.
It was found that the arm does not accurately move in this way. As the angle increases, the arm does not adjust its extension by a large enough distance. This can be corrected for, but an exact correction was not found. One correction that works to an acceptable degree of accuracy for angles less than 45 degrees is: $((delta)/math.cos(delta)) - delta$, with $delta$ being some value between 0.07 and 0.09 (the optimized value was not determined and it seems as if the right value changes based on how far the arm is currently extended and to which side the arm is turned). This correction is then added to $dist$.
Keyboard contouring example 1 Keyboard contouring example 2, with a more difficult keyboard to detect
Keyboard recognition was achieved with OpenCv transformations and image contouring. The keys of many different keyboards are able to be recognized and boxes are drawn around them. We were able to achieve key recognition with relatively little noise.
The first transformation applied to an image is optional glare reduction with cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8)). Then, the image is converted to greyscale with cv2.cvtColor(img, cv2.COLOR_BGR2GRAY). A threshold is then applied to the image. Different thresholds work for different images, so a variety of thresholds must be tried. One example that often works is cv2.THRESH_OTSU | cv2.THRESH_BINARY_INV. This applies an Otsu threshold followed by a binary inverse threshold. Finally, dilation and blur are applied to the image with customizable kernel sizes.
After the transformations are applied, OpenCV contouring is used with contours, hierarchy = cv2.findContours(img, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE). External contours (those with child contours and no parent contours) are ignored to reduce noise.
Before running the project, connect the arm and a usb webcam to a computer with ROS and the software for the Interbotix arm installed (this project will not work in the vnc).
Launch the arm: roslaunch interbotix_xsarm_control xsarm_control.launch robot_model:=px100 use_sim:=false
Follow these instructions if the keyboard you are using has not already been calibrated.
Position the usb camera in the center of the keyboard, facing directly down. The whole keyboard should be in frame. Ideally the keyboard will have minimal glare and it will be on a matte, uniform surface. The width of the image must be known, in meters. Alternatively, an image of the keyboard can be uploaded, cropped exactly to known dimensions (i.e. the dimensions of the keyboard).
Run roslaunch typinator image_setup.launch to calibrate the image filters for optimized key detection. A variety of preset filters will be applied to the image. Apply different combinations of the following parameters and determin which filter preset/parameter combination is the best. An optimal filter will show keys with large boxes around them, not have a lot of noise, and most importantly detect all of the keys. If there is a lot of noise, calibration will take a long time.
Once the tranformation preset, reduce_glare, blur, and kernel have been selected, the arm can be calibrated and run. Run roslaunch typinator typinator.launch with the appropriate parameters:
The arm will press each key it detects and save its position! It will then type the output from ChatGPT! You can open a file you want it to type into, even while calibrating.
Running from a preset
If a specific keyboard has already been calibrated, position the arm appropriately and run roslaunch typinator typinator.launch calibrate:=False keyboard_preset:="filename.json" Also set image_file if you want boxes to display current keys, and chatgpt if you want a custom input to chatgpt.
indiv_keys(): This is the callback function of Key service. It processes the text that it’s passed as its goal, and separates it by key/letter so that only one will be typed at a time. It also takes into account capital letters and inserts ‘caps_lock’ before and after the letter is added to the result list, since a keyboard only types in lower case. Furthermore, it takes into account new lines and passes ‘Key.enter’ in place of logging ‘\n’.
This class subscribes to the 'generated_text' topic, which consists of the text generated by ChatGPT that the arm is meant to type. cb_to_action_server(): This is the function that sends/sets the goal for the action server, and waits for the action to completely finish before sending the result. It makes the ChatGPT message the goal of the action, and waits for the text/letter separation to complete before sending the list of individual letters of the the text as the result. get_next_key(): This function returns the first key in the deque, which is the letter that needs to be typed by the arm next.
This class is used to convert key pixel positions to arm target x,y coordinates from an image of a keyboard. img_cb() and img_cb_saved(): These functions use cv2 image processing to find the individual keys on a keyboard from an image. It sets some of the class variables, such as height and width, which is then later used to calculate the conversion rates used to turn the key pixel positions into meter positions. The img_cb() function is used when it's subscribing to, and processing images from, a camera topic. Then, the img_cb_saved() function is used when an already saved image of a keyboard is being used instead of one received from the camera. Both functions essentially have/use the same code. find_key_points(): This function converts key pixel locations in the image to the physical x,y meter positions that can then be used to move the real arm so that it can hit the keys as accurately as possible on the actual keyboard. print_points(): This function prints each calculated point that has been stored in the class. The points are where we need the robot arm to move to in order to press a key. practice_points(): This function returns the entire list of points saved in the class, with the x and y meter values of the keys' positions on the physical keyboard. key_pos_action and action_response(): This is the KeyPos action and its callback function. The purpose of the action is to send the physical positions of the each key. It send real x, y, and z coordinates along with image x, image y, image height, and image width coordinates.
This node connects to ChatGPT through an API key to generate a message/string for the arm to type onto the keyboard. It then publishes the text to the 'generated_text' topic to be used by other nodes.
This file contains the sever for the 'arm_control' action, and it connects to the robotic arm. The MoveArm class acts as the link between the coordinates that the server receives and the motion of the arm.
calculate_distance() converts cartesian coordinates to polar coordinates.
set_xy_position(x, y) moves the arm to the specified cartensian x,y coordinates over the keyboard
press_point(z) moves the arm down to and back up from the specified depth coordinate
This file connects the other ROS nodes together. It runs the "coordinator" node. In "calibrate" mode, the main() uses the Coordinator class to get the image of the keyboard and find the positions of individual keys. Since these keys are not laballed, it then has the arm press each found contour. After each press, it gets the last pressed key with coordinator.get_key_press(). This uses the KeyPress action to get the stored last key press. If a new key was pressed, it is mapped to the location that the arm went to. After the arm has gone to every found position, it saves the key to position mappings in a .json file.
In "type" mode, the main() function loads one of the stored key mappings into a python dictionary. It gets the next letter to type one at a time using the get_next_key() method of a KeysActionClient. It uses the dictionary to find the location of the key, and then it send the arm to that location.
This file contains the FindKeys class. This class is used to find the positions of keyboard keys.
transform_image(img, threshold, blur, dilate) applies a transformation to an image of a keyboard with the specified threshold, blur kernel, and dilation kernel.
contour_image(img) applies image contouring and noise reduction to find the keys. It returns the contours as instances of the Key class.
This file contains the Key class that stores the data of each individual key found from the FindKeys class. center() returns the center of a key.
This file listens for keyboard input with pynput. The KeyListener class keeps track of the most recent key release and acts as the server for the KeyPress action. When called, it returns the most recent key that was pressed.
We started the project with high hopes for the capabilities of the arm and image recognition software. We planned to have the arm hold a pen and press keys on the keyboard. We hoped that the keys would be recognized through letter detection with machine learning.
Initially, we mainly set up the Interbotix arm software in our vnc’s, tested the movement of the arm, and began working on keyboard recognition. Our preliminary tests with detecting the keys on the keyboard were promising. Letter detection for the letter keys was promising, however, it was not working for the special keys or keys with more than one symbol on them.
We decided that to get the main functionality of the project working, we would divide the work between ourselves.
Kirsten worked on connecting to ChatGPT, publishing the response from ChatGPT as characters on the keyboard, and transforming pixel coordinates in an image into real world coordinates in meters. We discovered that ROS nodes that perform actions will block for too long to receive improperly timed callbacks, so in order to avoid issues with this, Kirsten worked on converting letter publishing ROS topics into ROS actions. By designing our code this way, we were able to have a central ROS node that called ROS actions and got responses sequentially.
Elliot worked on moving the robotic arm so that it could move to specific cartesian coordinates and then press down. He also worked on refining the keyboard recognition and designing the central node to bring the project together. After many attempts at reducing noise with statistical methods when finding the outlines of keys on a keyboard (with OpenCV contouring), he discovered that the contour hierarchy was a much more effective way of reducing noise. With contour hierarchy and number of customizable image transformations applied to the images, he was able to consistently find the keys on keyboards.
After reexamining letter detection with machine learning, we decided that it was not consistent enough to work for the desired outcome of our project. We realized we could “calibrate” the arm on the keyboard by pressing each key that was found through OpenCV contouring and listening for keystrokes. In theory, this could provide 100% accuracy.
We encountered many difficulties when putting our pieces of the project together and running it on the real arm. As can be expected, a few small quirks with ROS and a few small bugs caused us a lot of difficulty. For example, when we first ran the project as a whole, it started but nothing happened. We eventually found that our text publishing node had a global variable declared in the wrong place and was returning None instead of the letters it received from ChatGPT.
One major issue we encountered is that the arm motor turns itself off any time it thinks it is in one position but is actually in a different position. This usually only happened after around 10 key presses, so to fix it we have the arm return to its sleep position every 6 keystrokes. Another major issue is that the arm holds down on the keys for too long. We solved this problem by turning off key repeats in the accessibility settings of the computer controlling the arm. We found that the arm has some limitations with its accuracy which affects its typing accuracy, since the keys are such small targets. It also does not seem to accurately go to specific positions. It always goes to the same positions at a given angle, but its extension and retraction varies based on its current position. It was challenging, but we were able to find a function of the angle of the arm that offsets this error fairly accurately for angles less than 45 degrees, which is what we needed. If we were starting from scratch, we would place a fiducial on the arm and track its motion to try to get better accuracy.
We were mostly successful in achieving our original project goals. We are able to recognize a keyboard, train the arm on that keyborad, and type an output from ChatGPT. We were not successful in using letter recognition to press found keys in real time, however, with our method of calibrating the arm on a specific keyboard, the arm was able press any key on almost any keyboard. If we manually input arm positions for each key on a specific keyboard we would likely get better typing accuracy, but this would not be in line with our initial goal. Our use of image contouring to find keys and transformations to convert pixels to real coordinates makes the project applicable to any keybaord without manual input.
Send and receive data from ChatGPT
Computer Vision
Recognize keys on a keyboard
Detect letters on a keyboard (this was not used in the final project due to inconsistency)
Transform image coordinates to real world coordinates
Arm Control
Move the arm to specific positions with high accuracy
1
Apply a dilation kernel to the image. 1 has no effect (1 pixel kernel)
0
MUST SET THIS VALUE DURING CALIBRATION: Set to the the real world width of the image in meters
img_height
img_width*aspect ratio
Set this to the real world height of the image if necessary
arm_offset
0
Set this to the distance from the bottom edge of the image to the middle of the base of the arm
image_file
False
Input the path to the image file you would like to use if not using the camera
reduce_glare
False
Set to True to apply glare-reduction to the image
blur
1
Apply blur to the image before finding contours. 1 results in no blur.
kernel
1
Apply a dilation kernel to the image. 1 has no effect (1 pixel kernel)
thresh_preset
1
Apply this threshold preset to the image.
move_then_press(x,y,z) calls set_xy_position(x,y) followed by pres_point(z)
move_arm(msg) is an action callback function that calls for an instance of the MoveArm class to move the arm to the specified coordinates. It returns "True" when done.
key_pub.py
key_pos_action
key_pos.py
Keys
string full_text --- string[] keys --- bool status
image_file
False
Input the path to the image file you would like to use if not using the camera
reduce_glare
False
Set to True to apply glare-reduction to the image
blur
1
Apply blur to the image before finding contours. 1 results in no blur.
calibrate
True
Set to false if loading the keyboard from a preset
keyboard_preset
"temp_preset.json"
In calibration mode, save the keyboard to this file. Load this keyboard file if calibrate=False.
chatgpt
"Generate random text, but not lorem ipsum"
Text input to chatgpt
coordinator
coordinator.py
arm_control
arm_control.py
keys_to_type_action_client
keys_to_type_client.py
keys_to_type_action_server
keys_to_type_server.py
chatgpt_connection
chat_gpt.py
arm_control
ArmControl
float32 x float32 y float32 z --- string success --- string status
key_pos_action
KeyPos
string mode --- float32[] positions int32[] img_positions --- bool status
key_press
KeyPress
string mode bool print --- string key --- bool status
/generated_text
String
kernel
img_width
key_pub
keys_to_type_action
Spring 2022 Brendon Lu, Joshua Liu
As old as the field of robotics itself, robot competitions serve as a means of testing and assessing the hardware, software, in-between relationships, and efficiencies of robots. Our group was inspired by previous robot-racing related projects that navigated a robot through a track in an optimal time, as well as the challenge of coordinating multiple robots. Subsequently, our project aims to simulate a NASCAR-style race in order to determine and test the competitive racing capabilities of TurtleBots. Our project’s original objectives were to limit-test the movement capabilities of TurtleBots, implement a system that would allow for the collaboration of multiple robots, and present it in an entertaining and interactive manner. We managed to accomplish most of our goals, having encountered several problems along the way, which are described below. As of the writing of this report, the current iteration of our project resembles a NASCAR time-trial qualifier, in which a TurtleBot moves at varying speed levels depending on user input through a gui controller, which publishes speed data to our ‘driver’ node. For our driver node, we’ve adapted the prrexamples OpenCV algorithm in order to ‘drive’ a TurtleBot along a track, explained below, which works in conjunction with a basic PID controller in order to safely navigate the track.
. .
Below is the general setup of each robot’s “node tree.” These are all running on one roscore; the names of these nodes are different per robot. Green nodes are the ones belonging to the project, whereas blue nodes represent nodes initialized by the Turtlebot. The interconnecting lines are topics depicting publisher/subscriber relationships between different nodes. The “driver” in the robot is the Line Follower node. This is what considers the many variables in the world (the track, pit wall (controller), car status, and more) and turns that into on-track movement. To support this functionality, there are some nodes and functions which help the driver.
This is a function inside the line follower node which we felt was better to inline. Its workings are explained in exhausting detail in the next section. The main bit is that it produces an image with a dot on it. If the dot is on the left, the driver knows the center of the track is on the left.
This node is another subscriber to the camera. It notifies a car whenever it has crossed the finish line. This is accomplished, again, with the masking function of OpenCV. It is very simple but obviously necessary. This also required us to put a bit of tape with a distinct color (green in our case) to use as a finish line.
For a robot to pass another on track, it has to drive around it. The first and final design we are going to use for this involves LiDAR. A robot knows when one is close enough to pass when it sees the scanner of another robot close enough in front of it. It then knows it can go back when it sees the passed robot far enough behind it, and also sees that the track to its side is clear.
The GUI serves as the driver’s controller, allowing the driver to accelerate or decelerate the car, while also showing information about current speed and current heat levels. In combination with the GUI, we also provide the driver with a window showing the Turtlebot’s view from the raspicam, in order to simulate an actual driving experience.
Track construction was made specifically with the game design in mind. The track is made of two circles of tape: blue and tan in an oval-sh configuration. In the qualifying race, the cars drive on the tan line. In the actual race, the cars primarily drive on the blue line, which is faster. Cars will switch to the outer tan track to pass a slower one in the blue line, however. The intent behind some of the track’s odd angles is to create certain areas of the track where passing can be easier or harder. This rewards strategy, timing, and knowledge of the game’s passing mechanics. In qualifying, the tan track has turns that, under the right conditions, can cause the robot to lose track of the line. This is used as a feature in the game, as the players must balance engine power output with staying on track. If a careless player sends the car into the corner too quickly, it will skid off of the track, leaving the car without a qualifying time.
The core of our robot navigation relies on prrexamples’ OpenCV line follower algorithm, which analyzes a compressed image file to detect specific HSV color values, then computes a centroid representing the midpoint of the detected color values. The algorithm first subscribes to the robot’s raspberry pi camera, accepting compressed images over raw images in order to save processing power, then passes the image through the openCV’s bridge function, converting the ROS image to a CV2 image manipulatable by other package functions. In order to further save on process power, we resize the image using cv2.resize(), which changes the resolution of the image, reducing the number of pixels needing to be passed through the masking function. Regarding the resize() function, we recommend using cv2.INTER_AREA in order to shrink the image, and cv2.LINEAR_AREA or cv2.CUBIC_AREA in order to enlarge the image. Note that while using the cv2.CUBIC_AREA interpolation method will result in a higher quality image, it is also computationally more complex. For our project’s purposes, we used the cv2.INTER_AREA interpolation method. The algorithm then accepts a lower and upper bound of HSV color values to filter out of the CV2 image, called ‘masking’. The image then has all of its pixels removed except for the ones which fall within the specified range of color values. Then, a dot is drawn on the “centroid” of the remaining mass of pixels, and the robot attempts to steer towards it. To make the centroid more accurate and useful, the top portion of the image is stripped away before the centroid is drawn. This also means that if the color of surroundings happen to fall within the specified range of color values, the robot won’t take it into account when calculating the centroid (which is desirable).
Modular programming was a critical part of our program to determine which parts of our driver program were computationally intensive. The original line follower node processed the images inside the camera callback function. This arrangement causes the computer to be processed tens of times per second, which is obviously bad. The compression also would process the full size image. We tried remedying this by shrinking the already compressed image down to just 5% of its original size before doing the masking work. Unfortunately, both of these did not appear to have an effect on the problem.
We were able to construct a tkinter gui that interacts with other nodes. We accomplished this by initializing the gui as its own node, then using rostopics to pass user input data between the gui and other nodes.
Executing our project is twofold; first, run roslaunch nascar nascar.launch. Make sure the parameters of the launch file correspond to the name of the TurtleBot. Subsequently, open a separate terminal window and cd into the project folder, then run python tkinter_gui.py.
Our original project was an entirely different concept, and was meant to primarily focus on creating a system that allowed for multi-robot (2-4+) collaboration. We originally intended to create a “synchronized robot dancing” software, which was imagined as a set of 2, 3 or 4 robots performing a series of movements and patterns of varying complexity. Due to the project lacking an end goal and purpose, we decided to shift our focus onto our idea of a NASCAR-style racing game involving two robots. Rather than focusing on designing a system and finding a way to apply it, we instead began with a clear end goal/visualization in mind and worked our way towards it.
While working on our subsequent NASCAR-style multi-robot racing game, two major problems stuck out: one, finding suitable color ranges for the masking algorithm; two, computational complexity when using multiple robots. Regarding the first, we found that our mask color ranges needed to be changed depending heavily on lighting conditions, which changed based on time of day, camera exposure, and other hard-to-control factors. We resolved this by moving our track to a controlled environment, then calibrated our color range by driving the TurtleBot around the track. Whenever the TurtleBot stopped, we passed whatever image the raspicam currently saw through an image editor to determine HSV ranges, then multiplied the values to correspond with openCV’s HSV values (whereas GIMP HSV values range from H: 0-360, S: 0-100, and V: 0-100, openCV’s range from H: 0-180, S: 0-255, and V: 0-255). The cause of our second problem remains unknown, but after some experimentation we’ve narrowed down the cause to relating to computational power and complexity. When running our driver on multiple robots, we noticed conflicting cmd_vels being published resulting from slowdowns in our image processing function, realizing that adding additional robots would exponentially increase the computational load of our algorithm. We attempted to resolve this by running the collection of nodes associated with each robot on different computers, with both sets of nodes associated with the same roscore.
Overall, our group felt that we accomplished some of the goals we originally set for ourselves. Among the original objectives, which were to limit-test the movement capabilities of TurtleBots, implement a system that would allow for the collaboration of multiple robots, and present it in an entertaining and interactive manner, we felt we successfully achieved the first and last goal; in essence, our project was originally conceived as a means of entertainment. However, we were also satisfied with how we approached the second goal, as throughout the process we attempted many ways to construct a working multi-robot collaboration system; in the context of our project, we feel that our overtake algorithm is a suitable contribution to roboticists who would consider racing multiple robots.
Team: Chris Choi (mchoi@brandeis.edu), Lucian Fairbrother (lfairbrother@brandeis.edu), Eyal Cohen(eyalcohen@brandeis.edu)
Date: 3rd May 2022
Github repo: https://github.com/campusrover/RoboTag `
We wanted to create a dynamic project involving multiple robots. Since this project would be presented to people with a wide range of robotics knowledge, we wanted to create an intuitive project. We decided to recreate the game of tag using robots as most spectators know the rules, and so that each robot affects the other’s behavior.
The robots have one of two roles, cop and robber. The robbers flee from cops while avoiding obstacles, as the cops are in hot pursuit of them. When a cop is within a certain distance, and the cop catches the robber, their roles switch, and the new robber gets a 10-second head start to run away. If a spectating human feels left out of the fun, they can press a button to take control of their robot and chase the robber as the cop, or chase the cop as the robber.
Currently implemented two robots that can alternate between cop and robber, and user-controlled cop and robber.
COP ALGORITHYM- The cop algorithym was difficult to implement. The question of how to orient a cop towards moving coordinates was difficult for us to wrap our heads around. We first had to understand the pose variables. The pose orientation variable ranges from -3.14 to 3.14 and represents the angles a robot could be in, in radians. We eventually figured out a good compass algorithym, we used an if statement that calculated whether turning left or right was closer to the goal angle and then executed it. We had it go forward if the actual angle was within .2 radians of the goal angle
UDP-SOCKETS- We used UDP-sockets to send info accross our roscores. Because we had two roscores and we needed the robots to communicate their locations to each other we had them send their locations constantly over UDP sockets. We made a sender and receiver for each robot. The sender would subscribe to the AMCL_pose and then send out the message over the socket. The receiver would receive the message decode it, put it into a float64 list and publish it to the robot.
STATE SWITCH- State switching in our game is hugely important, if the robots aren't localized properly and one thinks a tag has happened while the other doesn't they will get caught as the same state. To deal with this we used AMCL to increase the localization and decrease any error. We also set up the tag such that the robber would stop for ten seconds after it became the cop and not be able to tag the new robber during that period. There were a few reasons we did this. Firstly because we wanted the new robber to have a chance to get away before it would get tagged again. Otherwise the two robots could get into an infinite loop of state switching. We also set the distance for the robber tag to be further than the cop to recognize a tag. The robber recognizes a tag at .35 and the cop recognizes it at .3 the reason for this is because the robber stops after recognizing the tag and the cop will keep going until it recognizes the tag. This makes it very unlikely for only one robot to recognize a tag which would result in them getting stuck in the same state.
Every robot needs its own computer to run.
On each computer clone the repository
Go into allinone.py and change one initialized state to robber, such that you have a cop and robber
go into tf_sender.py and change the ip address to the ip address of the other computer
Robo.launch- The main launch file for our project
NODES
Allinone.py - main program node
tf_sender.py - the socket sender node
receiver.py - the socket receiver node
OTHER FILES
Map.yaml
Map.pgm
AMCL
After the ideation period of Robotag, we faced a lot of difficulties and had to make many pivots throughout the project. We spent lots of time on not only development but also designing new methods to overcome obstacles. We had multiple sleepless nights in the lab, and hours-long Zoom meetings to discuss how we design our project. In these talks, we made decisions to move from one stage to another, start over from scratch for modularity, and strategize navigational methods such as move_base, TF, or our ultimate homebrewed algorithms.
First stage: Broadcast/Listener Pair Using TF. We tried to let robots directly communicate with each other by using TF's broadcast/listener method. We initially turned to TF as it is a simple way to implement following between robots. However, this solution was overly-predictable and uninteresting. Solely relying on TF would limit our ability to avoid obstacles in crowded environments.
Second stage: Increase modularity We decided to start over with a new control system with an emphasis on modularity. The new control system called ‘Control Tower’ is a node run on the computer that keeps a record of all robot’s roles and locations, then, orders where each robot has to go. Also, each robot ran the same code, that operates according to given stages. With this system, we would be able to switch roles freely and keep codes simple.
Third stage: move_base Although the Control Tower could properly listen to each robot, publishing commands to each robot was a grueling experience. For optimized maneuvering around a map with obstacles, we decided to use move_base. We successfully implemented this feature on one robot. Given coordinates, a robot could easily utilize move_base to reach that location. We were planning for this to be a cop’s method of tracking down the robber. We SLAMed a map of the second floor of our lab because it was mostly enclosed and has defining features allowing easier localizing. Using this map and AMCL, we could use move_base and move the robot wherever we wanted to. However, when it came time to run move_base on several robots, each robot’s AMCL cost map and move_base algorithm confused the opposing bot. Although in theory, this solution was the most favorable–due to its obstacle avoidance and accurate navigation–in practice, we were unable to figure out how to get move_base to work with multiple robots and needed to give up on AMCL and move_base sooner than we did.
Fourth stage: Using Odom After move_base and AMCL failed us, we used the most primitive method of localization, Odometry. We started each robot from the same exact position and watched as one robot would go roughly in the direction of the other. After a minute, each robot’s idea of the coordinate plane was completely different and it was clear that we could not move forward with using odometry as our method of localization. Due to the limitation of each robot needing to run the program from the same location, and its glaring inaccuracies, we looked elsewhere for our localization needs.
Fifth stage: Better Localization We missed the accuracy of AMCL. AMCL has fantastic localization capabilities combining both lidar and Odom and allows us to place a robot in any location on the map and know its present location, but we didn’t have time to wrestle with conflicting cost maps again, so we elected to run each robot on a separate computer. This would also allow future users to download our code and join the game with their robots as well! Once we had each robot running on its own computer, we created a strategy for robots to communicate between a UDP Socket, such that each one can receive messages about the others’ coordinates. This was an impromptu topic across multiple roscores!
From then on, our localization of each robot was fantastic and allowed us to focus on improving the cops’ tracking and the robber’s running away algorithm while effectively swapping their states according to their coordinate locations in their respective AMCLs.
go into your vnc and run roslaunch robotag robo.launch
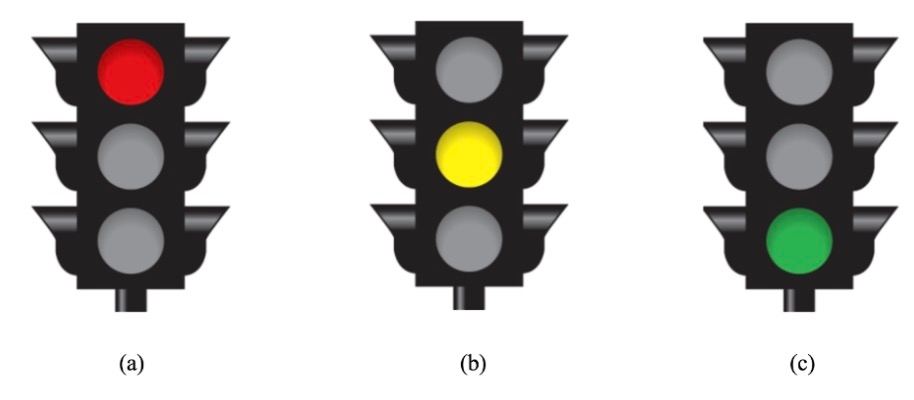
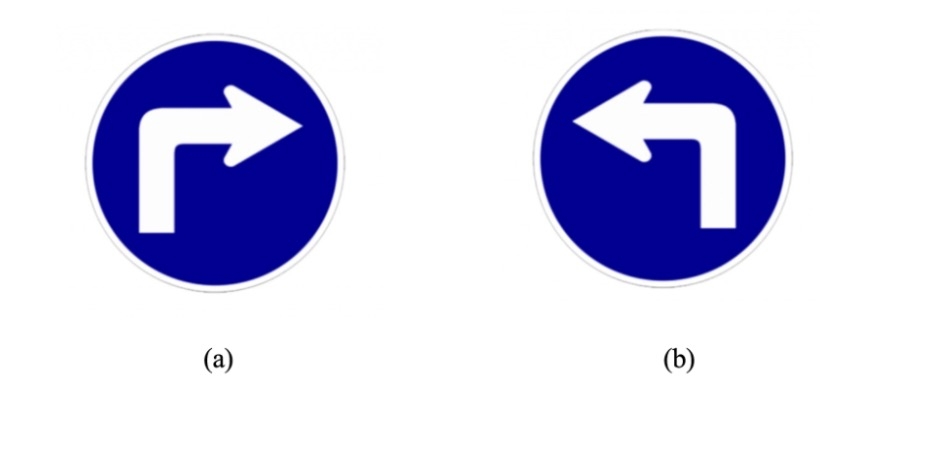
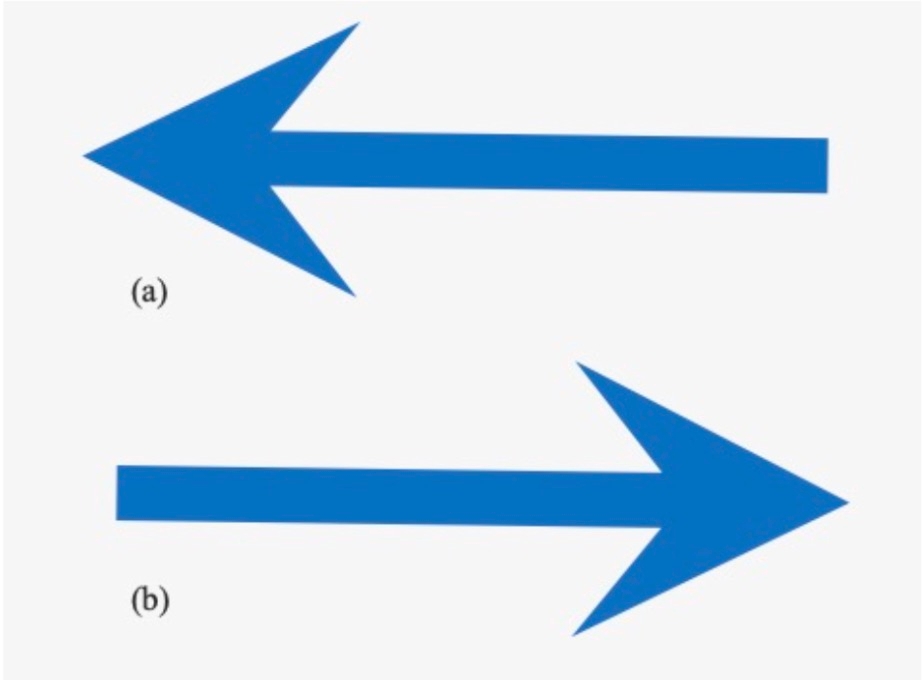

Project report for Waiterbot, an automated catering experience
Introduction\
For this project, we wanted to create an automated catering experience. More and more, customer service jobs are being performed by chatbots and voicebots, so why not bring this level of automation to a more physical setting. We figured the perfect domain for this would be social events. Waiter bot serves as a voice activated full-service catering experience. The goal was to create a general purpose waiter robot, where all the robot needs is a map of a catering location, a menu, and coordinates of where to pick-up food and or drinks.
Original Objectives:\
Capable of speech to text transcription and intent understanding.
Has conversational AI.
Can switch between 3 states – Wander, Take_Order, and Execute – to achieve waiter-like behavior.
Relevant literature:
Core Functionality:
This application was implemented as two primary nodes. One node serves as the user-interface, which is a flask implementation of an Alexa skill. This node is integrated with a ngrok subdomain. This node processes the speech and sends a voice response to Alexa while publishing necessary information for navigation.
We created a custom message type called Order, which consists of three std_msg/String messages. This stores the food for the order, the drink for the order, and the name of the On the backend, a navigation node processes these orders, and looks up the coordinates for where the food and drink items are located. We created a map of the space using SLAM with AMCL. The robot uses this map along with move-base to navigate to its goal and retrieve this item. While Alexa works great for taking orders, one of its flaws is that it cannot be programmed to speak unprompted. When the robot arrives to retrieve the item, the navigation node supplies the alexa-flask node with the item the robot needs.
A worker can ask Alexa what the robot needs, and Alexa tells the worker what is needed. The user then tells Alexa that the robot has the item, and it proceeds to its next stop. Once the robot has collected all of the items, it returns to the location where it originally received the voice request. The navigation node then supplies the alexa-flask node with a message for the order it is delivering. The user can then ask Alexa if that is their order, and Alexa will read back the order to the user. After this, the order is deleted from the node, allowing the robot to take more orders.
Due to the physical size constraints of the robot, it can only carry at most three orders at a time. The benefit of using the flask-ask module, is that the Alexa voice response can take this into account. If the robot has too many orders, it can tell the user to come back later. If the robot is currently in motion, and the user begins to make a user, a String message is sent from the alexa-flask node to the navigation node telling the robot to stop. Once Alexa has finished processing the order, the alexa-node sends another String message to the navigation node telling the robot to continue moving. If the robot has no orders to fulfill, it will roam around, making itself available to users.
In terms of overall behavior, the WaiterBot alternates between wandering around the environment, taking orders and executing the orders. After initialization, it starts wandering around its environment while its order_log remains empty or while it’s not stopped by users. It randomly chooses from a list of coordinates from wander_location_list.py, turns it into a MoveBaseGoal message using the goal_pose() function, and has actionlib’s SimpleActionClient send it using client.send_goal(). And instead of calling client.wait_for_result() to wait till the navigation finishes, we enter a while loop with client.get_result() == None as its condition.
This has 2 benefits – it makes the navigation interruptible by new user order and allows WaiterBot to end its navigation once it’s within a certain tuneable range of its destination. We noticed during our experimentation that while having SimpleActionClient send MoveBaseGoal works really well in gazebo simulation, it always results in WaiterBot hyper-correcting itself continuously when it arrives at its destination. This resulted in long wait times which greatly hampers the efficiency of WaiterBot’s service. Therefore, we set it up so that the robot cancels its MoveBaseGoal using client.cancel_goal() once it is within a certain radius of its goal coordinates.
When a user uses the wake phrase “Alexa, tell WaiterBot (to do something)” in the proximity of the WaiterBot, the robot will interrupt its wandering and record an order. Once the order has been published as an Order message to the /orders topic, the robot will initiate an order_cb function, store the order on an order_log, and start processing the first order. Before it looks up the coordinates of the items, it will store an Odometry message from /odom topic for later use. It then looks at Order message’s data field food and look up its coordinates in loc_string.py. After turning it into a MoveBaseGoal, it uses client to send the goal. Once the Waiterbot arrives at its destination, it will broadcast a message, asking for the specific item it is there to collect. It will not move on to its next destination till it has received a String message from the order_picked_up topic.
After it has collected all items, it uses the Odometry it stored at the beginning of the order and set and send another MoveBaseGoal. Once it returns to its original location, to the user. If order_log is empty, it will being wandering again.
How to Use the Code:
git clone https://github.com/campusrover/waiter_bot.git
cm
Download ngrok and authorize ngrok token pip3 install flask-ask and sudo apt-install ros-noetic-navigation
Have waiterbot skill on an Alexa device
ssh into your robot
roslaunch waiter_bot waiter_bot.launch\
Tables and Descriptions of nodes, files, and external packages:
Story of the Project:\
Our original project intended to have at least two robots, one working as a robot waiter, the other working as a robot kitchen assistant. Initially, we planned to create our NLP system to handle speech and natural language understanding. This quickly became a problem, as we could only find a single dataset that contained food orders and its quality was questionable. At the same time, we attempted to use the Google Speech API to handle out speech-to-text and text-to-speech. We found a ROS package for this integration, but some dependencies were out of data and incompatible. Along with this, the firewalls the lab uses, made integration with this unlikely. We then attempted to use PocketSphinx which is an off-the-shelf automated speech recognition package which can run offline. Initial tests of this showed an incredibly high word-error-rate and sentence-error-rate, so we abandoned this quickly. Previous projects had success integrating Alexa with ROS nodes, so we decided to go in that direction.
Building off of previous work using Flask and ngrok for Alexa integration was fairly simple and straightforward thanks to previous documentation in the lab notebook. Building a custom Alexa skill for our specific purpose was accomplished quickly using the Alexa Developer Console. However, previous methods did not allow a feature that we needed for our project, so we had to find a new approach to working with Alexa.
At first, we tried to change the endpoint for the skill from an ngrok endpoint to a lambda.py provided by Amazon, but this was difficult to integrate with an ROS node. We returned to an approach that the previous projects had used, but this did not allow us to build Alexa responses that involved considering the robots state and asking the user for more information in a way that makes sense. For example, due to the physical size of the robot, it can probably never handle more than three orders. An order consists of a food, a drink, and name to uniquely identify the order. From the Alexa Developer Console, we could prompt the user for this information, then tell the user if the robot already had too many orders to take another one, but this felt like bad user-interface design. We needed a way to let the user know that the robot was too busy before Alexa went through the trouble of getting all this information. Then we found a module called Flask-ASK, which seamlessly integrated flask into the backend of an Alexa Skill. This module is perfect for Alexa ROS integration. On the Alexa Developer Console, all you need to do is define your intents and what phrases activate them. Then within your ROS, you can treat those intents like functions. Within those functions you can define voice responses based on the robot’s current state and also publish messages to other nodes, making the voice integration robust and seamless.
Navigation-wise, we experimented with different ways of utilizing SimpleActionClient class of the actionlib package. As we have mentioned above, we originally used client.wait_for_result() so that WaiterBot can properly finish navigating. wait_for_result(), however, is a black box by itself and prevented us from giving WaiterBot a more nuanced behavior, i.e. capable of interrupting its own navigation. So we looked into the documentation of actionlib and learnt about the get_result() function, which allowed us to tear away the abstraction of wait_for_result() and achieve what we want.
It was surprising (though it should not be) that having a good map also proved to be a challenge. The first problem is creating a usable map using SLAM method of the Gmapping package only, which is not possible with any sizeable area. We searched for software to edit the pgm file directly and settled on GIMP. Having a easy-to-use graphical editor proved to be highly valuable since we are free to tweak any imperfections of a raw SLAM map and modify the image as the basement layout changes.
Another challenge we had concerned the sizes of the maps and how that affect localization and navigation. At one point, we ended up making a map of half the basement since we wanted to incorporate WaiterBot into the demo day itself: WaiterBot would move freely among the guests as people chat and look at other robots and take orders if requested. The large map turned out to be a problem, however, since the majority of the space on the map is featureless. This affects two things: the amcl algorithm and the local map. To localize a robot with a map, AMCL starts with generating a normally distributed initalpose, which is a list of candidate poses. As the robot moves around, AMCL updates the probabilities of these candidate poses based on LaserScan messages and the map, elimating poses whose positions don't align their corresponding predictions. This way, AMCL is able to narrow down the list of poses that WaiterBot might be in and increase the accuracy of its localization. AMCL thus does not work well on a large and empty map since it has few useful features for predicting and deciding which poses are the most likely. We eventually settled down on having a smaller, more controlled map built with blocks.
An issue unique to a waffle model like Mutant is that the four poles interfere with the lidar sensor. We originally tried to subcribe to /scan topic, modify the LaserScan messages, and publish it to a new topic called /scan_mod and have all the nodes which subscribe to /scan such as AMCL to subscribe to /scan_mod instead. This was difficult because of the level of abstraction we had been operating on by roslaunch Turtlebot3_navigation.launch and it was not convenient to track down every node which subscribe to /scan. Instead, we went straight to the source and found a way to modify the LaserScan message itself so that its scan.range_min definition is big enough so that it encompasses the four poles. We learnt that we need to modify the
Self Assessment
Overall, we consider this project a success. Through this project, we were able to integrate conversational AI with a robotic application, learning more about Alexa skill development, mapping, localization, and navigation. While there are a few more things we wish we had time to develop, such as integrating a speaker to allow the robot to talk unprompted, or using a robotic arm to place food and drink items on the robot, this project served as a lesson in properly defining the scope of a project. We learned how to identify moments where we needed to pivot, and rapidly prototyped any new features we would need. In the beginning, we wanted to be evaluated on our performance with regards to integrating an NLP system with a robot, and we more than accomplished that. Our Alexa skill uses complex, multi-turn dialog, and our robotic application shows what may be possible for future automation. This project has been a combination of hardware programming, software engineering, machine-learning, and interaction design, all vital skills to be a proper roboticist.
Veronika Belkina Robotics Independent Study Fall 2022
Objectives
Document the Interbotix X100 arm and create a program that would send commands to the arm through messages and help explore the capabilities and limitations of the arm.
Create a program that would push a ball towards a target and also to guess if a ball is under a goal and push it out.
The original purpose of this project was to create an arm that could play catch with the user. This would have involved catching a ball that was rolling towards it, and also pushing the ball towards a target.
arm-controlarm-control is a basic command line program that allows the user to send commands to the arm through a ROS message. There are two nodes: send_command.py and arm_control.py. The arm must be turned on, connected to the computer, and the ROS launch files launched.
send_command.py allows for a user to input a command (from a limited pool of commands) such as moving the arm to a point, opening or closing the gripper, moving to the sleep position, etc. There are some basic error checks in place such as whether the command is correct or whether the inputs are the correct type. The user can enter one command at a time and see what happens. The node will then publish the proper message out. There are 8 message types for the various commands to simplify parsing through and figuring out what is happening. When the user decides to exit the program, the sleep message will be sent out to put the arm in the sleep position and exit out of the send_command program.
not-play-catchThis is the setup for play-catch. There is a board that is taped off to indicate the boundaries of the camera. The robot is placed in the center of the bottom half and its base-link is treated as the origin (world). There is a ball that is covered in green tape for colour detection, and Apriltags that are placed on top of goals. The camera is situated around 80 cm above the board to get a full view of the board.
Camera and Computer Vision
Camera.py
This node does the main masking and filtering of the images for colour detection. It then publishes a variety of messages out with the various image types after processing. It also allows for dynamic reconfiguration so that it is easier to find the colour that you need.
Ball_distance.py
This node finds the green ball and determines its coordinates on the x-y plane. It publishes those coordinates and publishes an Image message that displays the scene with a box around the ball and the coordinates in centimeters in the corner.
Sending Commands
Pickup.py
The pickup node calculates the position of the ball and picks it up. It first turns to the angle in the direction of the ball and then moves in the x-z direction to pickup the ball. It then turns to the target Apriltag and puts the ball down 15cm away in front of the Apriltag. The calculations for the angles are down in the same way – determining the atan of the y/x coordinates. The steps are all done at trajectory time of 2.0 sec.
Push.py
The push node pushes the ball towards the target. It starts from the sleep position and then turns back to Apriltag target. Since it knows that the ball is already in position, it can push the ball with confidence after closing its gripper. The steps are all done at a trajectory time 0.9 sec to give extra impact to the ball and let it roll.
Guess.py
The guess node is a similar idea to the previous nodes, however, there is some random chance involved. The arm guesses between the two Apriltags, and then tries to push the ball out from under it. If a ball rolls out and is seen by the camera, then the arm will do a celebration dance. If there is no ball, then it will wait for the next turn. For this node, I had to make some adjustments to the way I publish the coordinates of the ball because when the ball wasn’t present, the colour detector was still detecting some colour and saying that there was a ball. So I adjusted the detector to only work when the detected box is greater than 30 pixels, otherwise, the node will publish (0,0,0). Since the ball is (x, y, 0.1) when it is being seen, there shouldn’t be a chance for an error with the ball being at (0,0,0). It would be (0,0,0,1) instead.
Miscellaneous
Main.py
The node that initiates the game with the user and the one that is run in the roslaunch file. From here, the other nodes are run. It also keeps track of the score.
Ball_to_transform.py
This node creates the transform for the ball using the coordinates that are published from ball_distance.py. It uses pose.yaml file to see what the name of the frame is, the parent frame, and the message topic the Pose is being published to.
Guide on how to use the code written
roslaunch arm_control command_center.launch
If you’re working with the actual arm, ensure that it is turned on and plugged into the computer before starting. Otherwise, if you’re working in simulation, then uncomment <arg name=use_sim value=true /> line in the launch file.
Tables
arm_control
not-play-catch
Messages
Other Files/Libraries
The idea for this project started a while ago, during the time when we were selecting what project to do in COSI119. I had wanted to play catch with a robot arm then, however, we ended up deciding on a different project at that time. But the idea still lived on inside me, and when Pito bought the PX100 over the summer, I was really excited to give the project a try.
The beginning was a little unorganized and a little difficult to get familiar with the arm because I had to stay home due to personal reasons for a month. I worked primarily on the computer vision aspects of the project at that time, setting up the Apriltag library and developing the colour detection for the ball and publishing a transform for it.
When I was able to finally return to the lab, it still felt hard to get familiar with the arm’s capabilities and limitations, however, after talking to Pito about it, I ended up developing the arm_control program to send commands and see how the ROS-Python API works more properly. This really helped push the project forward and from there, things felt like they went smoother. I was able to finish developing the pickup and pushing nodes. However, this program also allowed for me to see that the catching part of the project was not really feasible with the way things were. The commands each took several seconds to process, there had to be time between sending messages otherwise they might be missed, and it took two steps to move the arm in the x, y, z directions. It was a bit of a letdown, but not the end of the world.
As an additional part of the project, I was going to do a pick and place node, but it didn’t seem very exciting to be honest. So, I was inspired by the FIFA World Cup to create a game for the robot to play which developed into the guessing game that you see in the video.
This project had a lot of skills that I needed to learn. A big part of it was breaking down the task into smaller more manageable tasks to keep myself motivated and see consistent progress in the project. Since this project was more self-dictated than other projects that I have worked on, it was a challenge to do sometimes, but I’m happy with the results that I have achieved.
As I was writing this report, I had an insight that I felt would have made the program run much faster. It is a little sad that I hadn’t thought of it earlier which is simply to add a queue into the program to act as a buffer that holds commands as they come in. However, I wouldn’t have had to time to implement in a couple of days because it would require to rework the whole structure of the arm_control node. When I thought of the idea, I really didn’t understand how I didn’t think of it earlier, but I suppose that is what happens when you are in the middle of a project and trying to get things to work. Since I had written the arm_control program for testing and discovery and not for efficiency. But then I used it since it was convenient to use, but I didn’t consider that it was not really an optimized program. So next semester, I would like to improve the arm_control program and see if the arm runs the not-play-catch project faster.
Either way, I really enjoyed developing this project and seeing it unfold over time, even if it’s not exactly what I had aspired to do in the beginning. Hopefully, other people will also enjoy creating exciting projects with the arm in the future!
(I didn’t really want to change the name of the project, so I just put a not in front of it…)
In waiter_bot/src bash ngrok_launch.sh
Order.msg
A custom message containing three String messages: food, drink and name
ld08_driver.cppnanoLaserScanscan.range_minwaiter_bot_navigation.py
Master node. Has 3 functions Wander, Take_Order and Execute, which serve as states
waiter_bot_alexa_hook.py
Receives speech commands from the user, and sends them to the navigation node
bm.pgm
An image file of the lab basement created using SLAM of the gmapping package
bm.yaml
Contains map information such as origin, threshold, etc. related to bm.pgm
menu_constants.py
contains the food menu and the drink menu
loc_dictionary.py
Contains a dictionary mapping food and drink items to their coordinates
wander_location_list.py
Contains a list of coordinates for the robot’s wandering behavior
Flask-ASK
A Python module simplfying the process of developing the backend for Alexa skills using a Flask endpoint
Ngrok
Creates a custom web address linked to the computer's local IP address for https transfers
rosrun arm_control send_command.pyroslaunch playcatch play-catch.launch
Creates a transform for the ball.
camera.py
Does all the masking and filtering and colour detection to make the computer vision work properly.
Bool
Sends the arm to the sleep position
/arm_control/gripper
String
Opens or closes the gripper
/arm_control/exit
Bool
Exits the program and sends the arm to the sleep position
/arm_control/time
Float32
Sets the trajectory time for movement execution
/arm_control/celebrate
Bool
Tells the arm to celebrate!
send_command.py
Receives command line input from user and sends it to arm_control as a message
arm_control.py
Receives command line input from user and sends it to arm_control as a message
main.py
Brings everything together into a game
pickup.py
Locates the ball, determines if it can pick it up, and sends a series of commands to the arm to pick and place the ball in the correct angle for the Apriltag.
push.py
Pushes the ball towards the Apriltag using a series of commands.
guess.py
Guesses a box and pushes the ball out to see if it is there or not. If it is, then it does a celebratory dance. If it’s not, then it will wait for the next round sadly.
ball_distance.py
Calculates the location of the ball on the x-y plane from the camera and publishes a message with an image of the ball with a box around it and the coordinates of the ball.
/arm_control/point
Pose
Pose message which tells the arm where to go
/arm_control/pose
Pose
Pose message which sets the initial pose of the arm
/arm_control/home
Bool
Sends the arm to the home position
apriltag library
A library that allows for users to easily make use of Apriltags and get their transforms.
catch_settings.yaml
Apriltags settings to specify the family of tags and other parameters.
catch_tags.yaml
The yaml file for specifying information about the Apriltags.
pose.yaml
The yaml file for specifying information about the ball.
cvconfig.cfg
The dynamic reconfiguration file for colour detection and dynamically changing the colour that is being detected.
ball_to_transform.py
/arm_control/sleep

Team: Nazari Tuyo (nazarituyo@brandeis.edu) and Helen Lin (helenlin@brandeis.edu)
COSI 119a Fall 2022, Brandeis University
Date: May 4, 2022
If humans can’t enter an area because of unforeseen danger, what could be used instead? We created MiniScouter to combat this problem. The goal of our project was to create a robot that can be used to navigate or “scout” out spaces, with directions coming from the Leap Gesture Controller or voice commands supported by Alexa. The turtlebot robot takes in commands through hand gestures or voice, and interprets them. Once interpreted, the robot preforms the action requested.****
We referred to several documentations for the software used in this project:
We designed and created a voice and gesture controlled tele-operated robot. Voice control utilizes Alexa and Lambda integration, while gesture control is supported with the Leap Motion Controller. Communication between Alexa, the controller, and the robot is all supported by AWS Simple Queue Service integration as well as boto3.
The Leap Motion Controller
The Leap Motion Controller is an optical hand tracking module that captures hand movements and motions. It can track hands and fingers with a 3D interactive zone and identify up to 27 different components in a hand. The controller can be used for desktop based applications (as this project does) or in virtual reality (VR) applications.
The controller use an infrared light based stereoscopic camera. It illuminates the space near it and captures the user’s hands and fingers. The controller then uses a tracking algorithm to estimate the position and orientation of the hand and fingers. The range of detection is about 150° by 120° wide and has a preferred depth of between 10cm and 60cm, but can go up to about 80cm maximum, with the accuracy dropping as the distance from the controller increases.
The Leap Motion Controller maps the position and orientation of the hand and fingers onto a virtual skeletal model. The user can access data on all of the fingers and its bones. Some examples of bone data that can be accessed is shown below.
Alongside hand and finger detection, the Leap Motion Controller can additionally track hand gestures. The Leap Software Development Kit (SDK) offers support for four basic gestures:
Circle: a single finger tracing a circle
Swipe: a long, linear movement of a finger
Key tap: a tapping movement by a finger as if tapping a keyboard key
The controller also offers other data that can be used to manipulate elements:
Grab strength: the strength of a grab hand pose in the range [0..1]
An open hand has a grab strength of zero and a closed hand (fist) has a grab strength of one
Pinch strength: the strength of a pinch pose between the thumb and the closet finger tip as a value in the range [0..1]
The Leap Motion Controller offers much functionality and a plethora of guides online on how to use it. It’s recommended that the user keep the implementation of an application simple as having too many gestures doing too many things can quickly complicate an algorithm.
Leap Motion Setup
The Leap Motion Controller can be connected to the computer using a USB-A to Micro USB 3.0 cable. After it’s connected, you’ll need to get the UltraLeap hand tracking software, available . You may need to use older versions of the software since V4 and V5 only offer support and code in C. We found that V2 of the UltraLeap software best fit our needs as it offered Python support and still included a robust hand-tracking algorithm. We installed the necessary software and SDK for V2 from . Once we had all the necessary hardware and software set-up, we used the UltraLeap Developer documentation for Python at to begin creating the algorithm for our project.
To start using the Leap Motion Controller, you’ll need to connect the device to your computer via a USB-A to Micro USB 3.0 cable. You’ll need to install the Leap software from their website at . We found that we had to install older versions of the tracking software as the latest versions (V4 and V5) only supported C and that the Python version had been deprecated. For our needs, V2 worked best as it offered support for creating Python and came with a robust tracking system. After that, you’ll need to install the Leap SDK, with more details on how to set this up below. (See Setup for more details on how to set up Leap for this project specifically)
A widely known IOT home device, Amazon Alexa is Amazon’s cloud-based voice service, offering natural voice experiences for users as well as an advanced and expansive collection of tools and APIs for developer use.
When a phrase is said to Alexa, it’s first processed through the Alexa service, which uses natural language processing to interpret the users “intent” and then the “skill logic” (as noted down below) handles any further steps once the phrase has been interpreted.
We created an Alexa skill for this project as a bridge between the user and the robot for voice commands. The Alexa skill also utilizes AWS Lambda, a serverless, event-driven computing platform, for it’s intent handling. The Lambda function sends messages to the AWS SQS Queue that we used for Alexa-specific motion commands.
For example, if a user makes a request, saying “Alexa, ask mini scout to move forward”, the Alexa service identifies the user intent as “MoveForward”. Once identified, the lambda function is activated, and it uses a “handler” specific to the command to send a dictionary message to the queue.
AWS Simple Queue Service is a managed message queuing service used to send, store and retrieve multiple messages for large and small scale services as well as distributed systems.
The robot, Alexa, and the Leap motion controller all utilize the AWS Simple Queue Service to pass commands to each other. There are two options when creating queues, a standard queue, and a “FIFO” queue - first in first out, i.e. messages will only be returned in the order they were received. We created two FIFO queues, one for Leap, called “LeapMotionQueue”, and one for Alexa, called “AlexaMotionQueue”.
In the Alexa lambda function and the Leap script, a boto3 client is created for SQS, which is used to connect them to the queue.
On VNC, the robot makes the same connection to SQS, and since all of our work is carried out through one AWS account, it’s able to access the data pushed to both queues upon request.
Boto3 is the latest version of the AWS SDK for python. This SDK allows users to integrate AWS functionalities and products into their applications, libraries and scripts. As mentioned above, we used Boto3 to create a SQS ‘client’, or connection, so that our Leap script and our Alexa skill could access the queues.
Initially, we planned on having the Leap Motion Controller plugged directly into the robot, but after some lengthy troubleshooting, it was revealed that the Raspberry Pi the robot uses would not be able to handle the Leap motion software. Instead of giving up on using Leap, we thought of other ways that would allow communication between our controller and the robot.
At the suggestion of a TA (thanks August!) to look into AWS, we looked for an AWS service that might be able to support this type of communication. The Simple Queue Service was up to the task - it allowed our controller to send information, and allowed the robot to interpret it directly. (Deeper dive into this issue in the Problems/Pivots section)
One of the first and most important design choices we had to consider on this project was which gestures we should use to complete certain actions. We had to make sure to use gestures that were different enough so that the Leap Motion Controller would not have difficulty distinguishing between two gestures, as well as finding gestures that could encompass all the actions we wanted to complete. We eventually settled on the following gestures that were all individual enough to be identified separately:
Hand pitch forward (low pitch): move backward
Hand pitch backward (high pitch): move forward
Clockwise circle with fingertip: turn right
Another aspect we had to take into consideration when creating the algorithm was how much to tune the values we used to detect the gestures. For example, with the gesture to move forward and backward, we had to decide on a pitch value that was not so sensitive that other gestures would trigger the robot to move forward/backward but sensitive enough that the algorithm would know to move the robot forward/backwards. We ran the algorithm many times with a variety of different values to determine which would result in the greatest accuracy across all gestures. Even with these considerations, the algorithm sometimes was still not the most accurate, with the robot receiving the wrong command from time to time.
We implemented this algorithm on the local side. Within the code, we created a Leap Motion Listener object to listen to commands from the Leap Motion Controller. The Leap Listener takes in data such as number of hands, hand position in an x, y, z plane, hand direction, grab strength, etc. This data is then used to calculate what gestures are being made. This information then makes a request to the queue, pushing a message that looks like the following when invoked:
On the VNC side, the motion is received from the SQS queue and turned back into a dictionary from a string. The VNC makes use of a dictionary to map motions to a vector containing the linear x velocity and angular z velocity for twist. For example, if the motion is “Move forward,” the vector would be [1,0] to indicate a linear x velocity of 1 and an angular z velocity of 0. A command is published to cmd_vel to move the robot. The current time ensures that all of the messages are received by the queue as messages with the same data cannot be received more than once.
For the Alexa skill, many factors had to be considered. We wanted to implement it in the simplest way possible, so after some troubleshooting with Lambda we decided on using the source-code editor available in the Alexa developer portal.
In terms of implementing the skill, we had to consider the best way handle intents and slots that would not complicate the way messages are sent to the queue. We settled on giving each motion an intent, which were the following:
MoveForward
MoveBackward
RotateLeft
In order for these ‘intents’ to work with our robot, we also had to add what the user might say so that the Alexa service could properly understand the intent the user had. This meant adding in several different “utterances”, as well as variations of those utterances to ensure that the user would be understood. This was very important because each of our intents had similar utterances. MoveForward had “move forward”, MoveBackward has “move backwards”, and if the Alexa natural language processor only has a few utterances to learn from it could easily confuse the results meant for one intent for a different intent.
Once the intent was received, the Lambda function gets to work. Each handler is a class of it’s own. This means that if the intent the Alexa service derives is “RotateRight”, it invokes only the “RotateRightHandler” class. This class makes a request to the queue, pushing a message that looks like the following when invoked.
Once this reaches VNC, the ‘intent_name’ - which would be a string like ‘MoveForward’ - is interpreted by converting the string into a dictionary, just like the Leap messages. We had to add the current time as well, because when queue messages are identical they are grouped together, making it difficult to pop them off the queue when the newest one arrives. If a user requested the robot to turn right twice, the second turn right message would not make it to the queue in the same way as the first one since those message are identical. Adding the time makes each message to the queue unique - ensuring it reaches the robot without issue.
The way that motions would be handled from two different sources in VNC was a huge challenge at one point during this project. Once we decided we’d incorporation voice control into our robots motion, it was clear that switching back and forth between leap commands and voice commands would be an issue. At first, we thought we’d try simultaneous switching between the two, but that quickly proved to be difficult due to the rate in which messages are deleted from each queue. It was hard to ensure that each command would used while reading from both of the queues, as messages could arrive at the same time. So we made the executive decision that voice commands take priority over Leap commands.
This means that when an Alexa motion is pushed onto the queue, if the script that’s running on VNC is currently listening to the Leap queue, it will pause the robot and proceed to listen to commands from the Alexa queue until it receives a stop command from Alexa.
This simplified our algorithm, allowing for the use of conditionals and calls to the SQS class we set up to determine which queue was to be listened to.
On the VNC, there are 3 classes in use that help the main function operate.
MiniScoutAlexaTeleop
MiniScoutLeapTeleop
SQS_Connection
The MiniScoutMain file handles checking each queue for messages and uses conditionals to determine which queue is to be listened to as well as making calls to the two teleop classes for twist motion calculation.
The SQS_Connection class handles queue connection, and has a few methods that assist the main class with it. The method has_queue_message() returns whether the requested queue has a message or not. This method makes a request to the selected queue, asking for the attribute ApproximateNumberOfMessages . This was the only way we could verify how many messages were present in the queue, but it proved to be a challenge as this request only returns the approximate number of messages in the queue. At any time during the request could the number change. This meant that we had to set a couple of time delays in the main script as well as checking the queue more than once to accomodate for this possibility. The method get_sqs_message() makes a request to the queue for a message, but only is called in the main function if has_queue_message() returns True . This helps insure that the request does not error out and end our scripts execution.
The MiniScoutAlexaTeleop class handles incoming messages from the Alexa queue and converts them into twist messages based on the intent received in the dictionary that are then published to cmd_vel once returned.
The MiniScoutLeapTeleop class takes the dictionary that is received from the SQS queue. It makes use of this dictionary to map motions to a vector containing the linear x velocity and angular z velocity for twist, and then returns it.
Clone the Mini Scout repository (Be sure to switch to the correct branch based on your system)
Install the Leap Motion Tracking SDK
When we first started our project, we had the idea of creating a seeing-eye dog robot that would guide the user past obstacles. We decided we wanted to use the Leap Motion Controller in our project and we planned to have the user direct the robot where to go using Leap. We would then have the robot detect obstacles around it and be able to localize itself within a map. Our final project has definitely deviated a lot from our original project. At the beginning, we made our project more vague to just become a “gesture-controlled bot” since we felt that our project was taking a different direction than the seeing-eye dog bot we had planned on. After implementing features for the robot to be commanded to different positions through hand gestures and voice commands, we settled on creating a mini scouter robot that can “scout” ahead and help the user detect obstacles or dangerous objects around it.
Our first main challenge with the Leap Motion Controller was figuring out how to get it connected. We first attempted to connect the controller directly to the robot via USB. However, the computer on the turtlebot3 ended up not being strong enough to handle Leap, so we had to consider other methods. August recommended using AWS IOT and we began looking into AWS applications we could use to connect between the local computer and VNC. We settled on using AWS SQS to send messages from the local computer to the VNC and the robot and we used boto3 to add SQS to our scripts.
Our next challenge was with getting the Leap Motion Controller setup. The software we needed for Leap ended up not being compatible with Monterey (the OS Nazari’s laptop was on) and it didn’t seem to work when attempting to set it up on Windows (Helen’s laptop). For Mac, we found a workaround (listed above under setup) to get V2 of the Leap software working. For Windows, we had to try a couple different versions before we found one that worked (Orion).
There were also challenges in finding the best way to represent the gestures within the algorithm for moving the robot. Our gestures were not clear at times and having the robot constantly detect gestures was difficult. We had to make changes to our code so that the robot would see a gesture and be able to follow that command until it saw another gesture. This way, Leap would only have to pick up on gestures every few seconds or so - rather than every second - making the commands more accurate.
When we started implementing a voice control system into the robot, we had challenges with finding a system that wasn’t too complex but worked well with our needs. We first explored the possibility of using pocketsphinx package but this ended up not being the most accurate. We decided to use Amazon Alexa and AWS lambda to implement voice recognition.
Overall, we are very satisfied with the progress on this project. It was quite tricky at times, but working with AWS and finding a new way for the controller to communicate with the robot was an unexpected “pivot” we took that worked out well in the long run. The entire project was truly a learning experience, and it’s exciting to watch our little Mini Scouter move as it uses the code we created over the last three months.
As the tip of the thumb approaches the tip of a finger, the pinch strength increases to one
Grab strength 1 (hand is a fist): stop all movement
Stop
Windows (Orion, SDK included): https://developer.leapmotion.com/tracking-software-download
Mac OS Installation
Note: The MacOS software does not currently work with macOS Monterey, but there is a hack included below that does allow it to work
Once installed, open the Leap Motion application to ensure correct installation.
A window will pop up with controller settings, and make sure the leap motion icon is present at the top of your screen.
Plug your leap motion controller into your controller via a USB port.
From the icon dropdown menu, select visualizer.
The window below should appear.
Note: If your MacOS software is an older version than Monterey, skip this step. Your visualizer should display the controller’s cameras on it’s own.
Restart your computer, leaving your Leap controller plugged in. Do not quit the Leap Application. (so it will open once computer is restarted)
Once restarted, the computer will try to configure your controller. After that is complete, the cameras and any identifiable hand movement you make over the controller should appear.
Windows Installation
Note: the Leap Motion Controller V2 is not compatible with a certain update of Windows 10 so you’ll have to use the Orion version of the Leap software
With V2, you can go into Program Files and either replace some of the .exe files or manually change some of the .exe files with a Hex editor
However, this method still caused some problems on Windows (Visualizer could see hands but code could not detect any hand data) so it is recommended that Orion is used
Orion is slightly worse than V2 at detecting hand motions (based off of comparing the accuracy of hand detection through the visualizer
Orion is fairly simple to set up; once you install the file, you just run through the installation steps after opening the installation file
Make sure to check off “Install SDK” when running through the installation steps
After the installation is completed, open “UltraLeap Tracking Visualizer” on your computer to open the visualizer and make sure the Leap Motion Controller is connected
The window below should look like this when holding your hands over the Leap Motion Controller:
AWS Setup
Create a AWS Account (if you have one already, skip this step)
Create an SQS Queue in AWS
Search for “Simple Queue Service”
Click “Create Queue”
Give your queue a name, and select ‘FIFO’ as the type.
Change “Content-based deduplication” so that its on. There is no need to change any of the other settings under “Configuration”
Click “Create Queue”. No further settings need to be changed for now.
This is the type of queue you will use for passing messages between your robot, the leap controller, alexa and any additional features you decide to incorporate from the project.
Creating your Access Policy
Click “Edit”
Under “Access Policy”, select advanced, and then select “Policy Generator”
Repeat step 1-5 once more, naming the queue separately for Alexa.
Create an AWS access Key (Start at “Managing access keys (console)”)
Save the details of your AWS access key somewhere safe.
Installing AWS CLI, boto3
Follow the steps at the link below:
Once completed, downgrade your pip version with:
Adding your credentials to the project package
In your code editor, open the cloned gesture bot package
navigate to the “credentials” folder
using your saved AWS Access Key info, edit the fields
Your “OWNER_ID” can be found in the top right hand corner of your aws console
“lmq_name” is the name of your queue + “.fifo”
i.e. leapmotionqueue.fifo
change the name of Add_Credentials.py to Credentials.py
You will need to do this step with each credentials file in each package
IMPORTANT
UNDER NO CONDITION should this file be uploaded to github or anywhere else online, so after making your changes, run nano .git/info/exclude and add Credentials.py
Please make sure that it is excluded by running git status and then making sure it’s listed under Untracked files
Running the script
Before running this script, please make sure you have Python2.7 installed and ready for use
navigate to the ‘scripts' folder and run ‘python2.7 hello_robot_comp.py'
If everything is installed correctly you should see some output from the controller!
to run the teleop script, run ‘LeapGestureToSQS.py’ while your controller is plugged in and set up!
Using the Alexa Skill
This step is a bit more difficult.
Go to the Alexa Developer Console
Click “Create Skill”
Give your skill a name. Select Custom Skill. Select ‘Alexa-Hosted Python’ for the host.
Once that builds, go to the ‘Code’ tab on the skill. Select ‘Import Code’, and import the “VoiceControlAlexaSkill.zip” file from the repository, under the folder “Alexa”
Import all files.
In Credentials.py, fill in your credentials, ensuring you have the correct name for your queue.
“vcq_name” is the name of your queue + “.fifo”
Click ‘Deploy’
Once Finished, navigate to the ‘Build’ tab. Open the intents.txt file from the repository’s ‘Skill’ folder (under the Alexa folder), and it’s time to build our intents.
Under invocation, give your skill a name. This is what you will say to activate it. We recommend mini scout! Be sure to save!
Under intents, click ‘Add Intent’ and create the following 5 intents:
Move
MoveForward
Edit each intent so that they have the same or similar “Utterances” as seen in the intents.txt file. Don’t forget to save!
Your skill should be good to go! Test it in the Test tab with some of the commands, like “ask mini scout to move right”
Using MiniScout in ROS
Clone the branch entitled vnc into your ROS environment
install boto3 using similar steps as the ones above
run catkin_make
give execution permission to the file MiniScoutMain.py
change each Add_Credentials.py file so that your AWS credentials are correct, and change the name of each file to Credentials.py
running hello robot!
run the hello_robot_comp.py script on your computer
run the hello_robot_vnc.py script on your robot
sqs_message = {
"Current Time":current_time.strftime("%H:%M:%S"),
"Motion Input": "Leap",
"Motion": motion
}sqs_message = {
"Motion Input": "Alexa",
"Intent": intent_name,
"Current Time":current_time.strftime("%H:%M:%S")
}MacOS
path on computer/mini_scouter
│
├── Alexa
│ ├── VoiceControlAlexaSkill.zip
│ ├── VoiceControlAlexaSkill
│ ├── interactionModels
│ ├── custom / en-US.json
│ ├── lambda
│ ├── Credentials.py
│ ├── lambda_function.py
│ ├── requirements.txt
│ ├── utils.py
│ └── skill.json
│ └── intents.txt
├── src
│ ├── credentials
│ ├── __init__.py
│ └── Add_Credentials.py
│ ├── MacOSLeap
│ ├── Leap.py
│ ├── LeapPython.so
│ └── libLeap.dylib
├── hello_robot_comp.py
├── LeapGestureToSQS.py
└── .gitignore
Windows
path on computer/mini_scouter
│
├── Alexa
│ ├── VoiceControlAlexaSkill.zip
│ ├── AlexaSkillUnzipped
│ ├── interactionModels
│ ├── custom / en-US.json
│ ├── lambda
│ ├── Credentials.py
│ ├── lambda_function.py
│ ├── requirements.txt
│ ├── utils.py
│ └── skill.json
│ └── intents.txt
├── src
│ ├── credentials
│ ├── __init__.py
│ └── Credentials.py
│ ├── WindowsLeap
│ ├── Leap.py
│ ├── LeapPython.so
│ └── libLeap.dylib
├── LeapGestureToSQS.py
└── .gitignore
vnc
catkin_ws/src/mini_scout_vnc
│
├── src
│ ├── credentials
│ └── Credentials.py
│ ├── hello_robot
│ └── src
│ ├── Credentials.py
│ └── hello_robot_vnc.py
│ ├── sqs
│ └── sqs_connection.py
│ ├── teleop
│ ├── MiniScoutAlexaTeleop.py
│ └── MiniScoutLeapTeleop.py
│ └── MiniScoutMain.py
├── CMakeLists.txt
├── README.md
├── package.xml
└── .gitignoreThis will take you to the AWS Policy Generator. The Access Policy you create will give your Leap software, Alexa Skill and robot access to the queue.
Add your account ID number, which can be found under your username back on the SQS page, and your queue ARN, which can also be found on the SQS page.
Select “Add Statement”, and then “Generate Policy” at the bottom. Copy this and paste it into the Access Policy box in your queue (should be in editing mode).
sudo easy_install pip==20.3.4(this is needed since the LEAP portion of the project can only run on python2.7)
Run the following commands
pip install boto3
pip freeze
check that boto3 is actually there!
python -m pip install --user boto3
RotateLeft
RotateRight

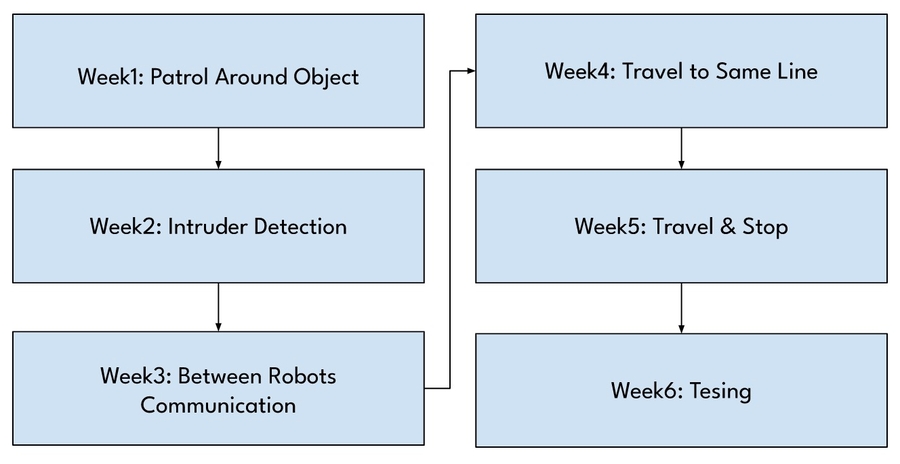



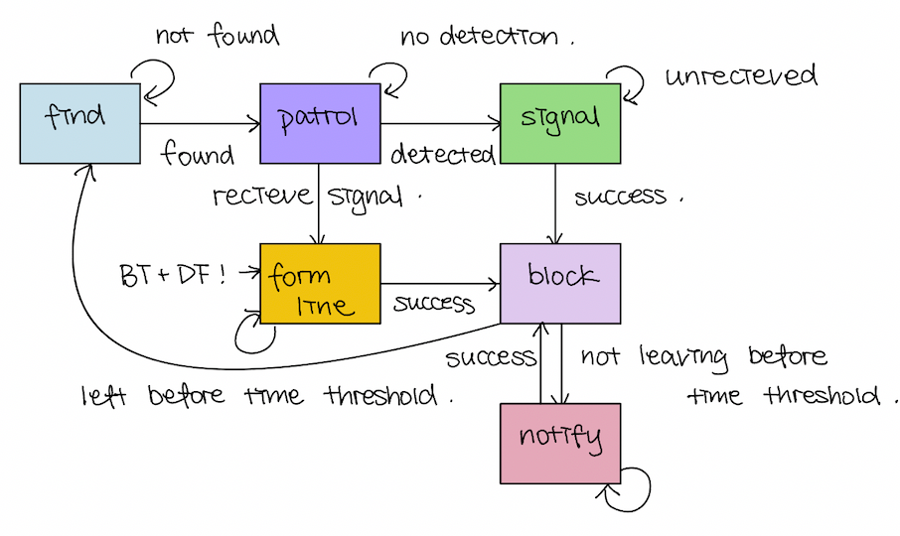






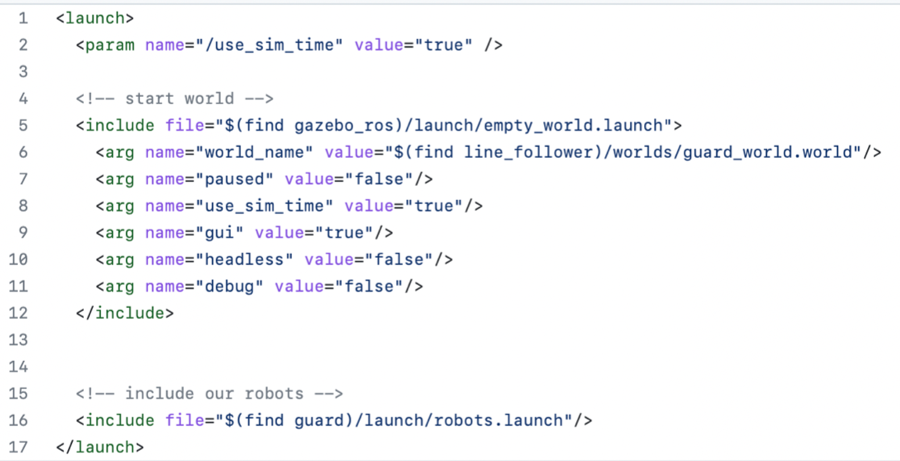

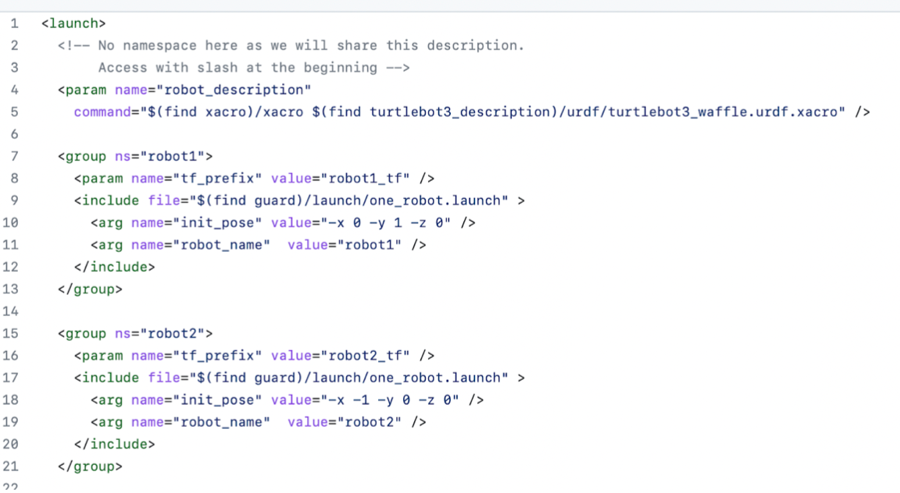

Solving a maze is an interesting sub-task for developing real-world path schedule solutions on robots. Typically, developers prefer to use depth sensors such as lidar or depth camera to walk around in a maze, as there a lots of obstacle walls that the robot need to follow and avoid crashing. Depth sensors have their advantage to directly provide the distance data, which naturally supports the robot to navigate against the obstacles.
However, we have come up with another idea to solve the maze using the computer vision approach. By reading articles of previous experts working on this area, we know that the RGB image cameras (CMOS or CCD) could also be used to get the depth information when they have multiple frames captured at different points of view at the same time, as long as we have the knowledge of the relative position where the frames are taken. This is basically the intuition of how human eyes work and developers have made a lot of attempts on this approach.
Though it could calculate the depth data by using cameras no less than 2, it is not as accurate as directly using the depth sensors to measure the environment. Also, the depth calculation and 3D reconstruction requires a lot of computational resource with multiple frames to be processed at the same time. Our hardware resource might not be able to support a real-time response for this computation. So we decide not to use multiple cameras or calculate the depth, but to extract features from a single image that allows the robot to recognize the obstacles.
The feature extraction from a single frame also requires several image processing steps. The features we chose to track are the lines in the image frames, as when the robot is in a maze boundary lines will could be detected as because walls and the floor could have different colors. We find the lines detected from the frames, which slopes are in certain ranges, are exactly the boundaries between the floor and walls. As a result, we tried serval approaches to extract these lines as the most important feature in the navigation and worked on optimization to let the robot perform more reliable.
We also implemented several other algorithms to support the robot get out of the maze, including a pid controller. They will be introduced later.
To detect the proper lines stably, we used some traditional algorithms in the world of computer vision to process the frames step by step, including:
Gaussian blur to smooth the image, providing more chance to detect the correct lines. https://web.njit.edu/~akansu/PAPERS/Haddad-AkansuFastGaussianBinomialFiltersIEEE-TSP-March1991.pdf https://en.wikipedia.org/wiki/Gaussian_blur
converting image from RGB color space to HSV color space https://en.wikipedia.org/wiki/HSL_and_HSV
convert the hsv image to gray and then binary image
We also implemented a pid controller for navigation. Here are some information about the pid controller: https://en.wikipedia.org/wiki/PID_controller
The general idea has already been described in the above sections. In this section we will talk about the detail structure and implementation of the code.
Some of the algorithms we are using to detect the lines have implementations in the OpenCV library. For the Gaussian, HSV conversion, gray and binary conversion, Canny edge detection and Hough line detection, OpenCV provides packaged functions to easily call and use. At beginning of the project, we just simply tried these functions around in the gazebo simulation environment, with a single script running to try to detect the edge from the scene, which are the boundaries between the floor and the walls.
When the lines could be stably detected, we tested and adjusted in the real world. After it works properly, we tidy the code and make it a node called the line detector server. It subscribe the image from the robot's camera and always keeping to process the frames into the lines. It publishes the result as a topic where other nodes can subscribe to know about the information of the environment such as whether there is a wall or not. (As in some cases even there is a line at side, there could be no wall, we also check several pixels at the outer side of the line to determine whether there is truly a wall or not)
e.g. left line with left wall (white brick indicates a wall):
e.g. left line with no left wall (black brick indicates a floor):
Then, we considered about the maze configuration and determined that a maze can have 7 different kinds of possible turns, that are:
crossroad
T-road where the robot comes from the bottom of the 'T'
T-road where the robot comes from the left
We then decided that it is necessary to hard code the solution of these cases and make it an action node to let the robot turn properly as soon as one of such situation is detected. The reason of using the hard-coded solution in a turn is because when the robot walks close to the wall, the light condition will change so sharply that it could not detect the edges correctly. So we let the robot to recognize the type of the turn accurately before it enter and then move forward and/or turn for some pre-defined distances and degrees to pass this turn.
In order to solve the problem that the pi camera's view of angle is too small, we let robot to stop before enter a turn and turn in place to look left and right for some extra angles so that it will have broad enough view to determine the situation correctly.
e.g. left line detected correctly
e.g. fail to detect the left line, not enough view
e.g. turn a bit to fix the problem
e.g. no right line, turn and no detection, correct
This node is called corner handle action server. When the main node detects that there is a wall (line) in the front which is so near that the robot is about to enter a turn, it will send request to this corner handler to determine the case and drive over the turn.
In order to finally get out the maze, the robot also need a navigation algorithm, which is a part of the corner handler. We chose an easy approach which is the left-wall-follower. The robot will just simply turn left whenever it is possible, or go forward as the secondary choice, or turn right as the third choice, or turn 180 degrees backwards as the last choice. In this logic, the above 7 turn cases can be simplified into these 4 cases. For example, when the robot find there is a way to the left, it does not need to consider the right or front anymore and just simply turn left. When the actions (forward and turning) has been determined, the corner handle action server will send request to another two action servers to actually execute the forward and turning behaviors.
So the general idea is: when the robot detects a turn in the maze by analyzing the lines, its main node will call an action to handle the case and wait until the robot has passed that turn. In other time, the robot will use the pid algorithm to try to keep at the middle of the left and right walls in the maze, going forward until reaches the next turn. We have wrote the pid controller into a service node that the main node will send its request to calculate the robot's angular twist when the robot is not handling turns, the error is calculated by the different of intercept of left line on x = 0 and right line on x = w (w is the width of the frame image).
In conclusion, we have this node relationship diagram
Then the workflow of our whole picture is pretty straightforward. The below flowchart describes it:
In this section, we briefly talk about some details of the algorithms we use.
The Process of Canny edge detection algorithm can be broken down to 5 different steps:
Apply Gaussian filter to smooth the image in order to remove the noise
Find the intensity gradients of the image
Apply non-maximum suppression to get rid of spurious response to edge detection
The simplest case of Hough transform is detecting straight lines, which is what we use. In general, the straight line y = mx + b can be represented as a point (b, m) in the parameter space. However, vertical lines pose a problem. They would give rise to unbounded values of the slope parameter m. Thus, for computational reasons, Duda and Hart proposed the use of the Hesse normal form
where r is the distance from the origin to the closest point on the straight line, and θ is the angle between the x axis and the line connecting the origin with that closest point.
It is therefore possible to associate with each line of the image a pair ( r , θ ).The ( r , θ ) plane is sometimes referred to as Hough space for the set of straight lines in two dimensions. This representation makes the Hough transform conceptually very close to the two-dimensional Radon transform. (They can be seen as different ways of looking at the same transform.)
Given a single point in the plane, then the set of all straight lines going through that point corresponds to a sinusoidal curve in the (r,θ) plane, which is unique to that point. A set of two or more points that form a straight line will produce sinusoids which cross at the (r,θ) for that line. Thus, the problem of detecting collinear points can be converted to the problem of finding concurrent curves.
After use the Hough line algorithm to find a set of straight lines in the frame. we use a slope filter to find a single line which slope is in a particular range and is also closest to a particular reference value. For the front line, we always use the one at most bottom of the frame, which means it is the closest wall.
Pid controller stands for a proportional, integral and derivative controller, which out put is them sum of these three terms, with each of them times a constant factor.
In our pid implementation, the raw input of the error is the term that will times the proportional factor. The integral term is calculated by the sum of the content of a error history deque, which keeps the latest 10 error history values and sum their product with the time gap between each other (graphically the area of a trapezoid). The derivative term is calculated by the difference of the current error and the last error, divided by the difference of their time gap.
As above mentioned, our project is strongly relied on the accuracy of edge detection. At the beginning, we only apply Gaussian filter to remove the noise in the image then just apply double threshold to determine edges. However, it does not work well. Then we try to convert the denoised image to a hsv image and convert this hsv image into a binary image before applying canny function. Unfortunately, it does not work every time. Sometimes because of the light and shadow issue it cannot detect the desired edges. Finally, we changed our binary image generation method by considering 3 features, hue, saturation and value, rather than only one feature hue, which turns out works much more robust.
The algorithm to make robot walk straight without hitting the wall is also necessary. At the beginning we applied the traditional wall following algorithm, single side wall following. It only worked on some simple occasions and easily went wrong. What making this single side following algorithm worse is taking turns. Because we use the camera as our only sensor and when taking turns it might lose wall due to the perspective change. Therefore, it is hard to extend the single-side-wall-following algorithm to an all situation handle algorithm. Then we come up with an idea to detect both sides wall. To maintain the robot drives at the middle of road, we got both sides boundaries between ground and wall and maintain those 2 lines intersecting the edges of image at the same height. Another benefit from this algorithm is that the more lines we detected, the more information we get, then the more accurate reflection of surroundings.
Third view: https://drive.google.com/file/d/1lwV-g8Pd23ECZXnbm_3yocLtlppVsSnT/view?usp=sharing First view on screen: https://drive.google.com/file/d/1TGCNDxP1frjd9xORnvTLTU84wuU0UyWo/view?usp=sharing
do Canny edge detection on the binary image http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.420.3300&rep=rep1&type=pdf https://en.wikipedia.org/wiki/Canny_edge_detector
do Hough line detection on the edges result http://www.ai.sri.com/pubs/files/tn036-duda71.pdf https://en.wikipedia.org/wiki/Hough_transform
apply an slope filter on the lines to reliably find the boundary of the walls and the floor
left turn
right turn
dead end
Track edge by hysteresis: Finalize the detection of edges by suppressing all the other edges that are weak and not connected to strong edges.
r = x cos θ + y sin θ



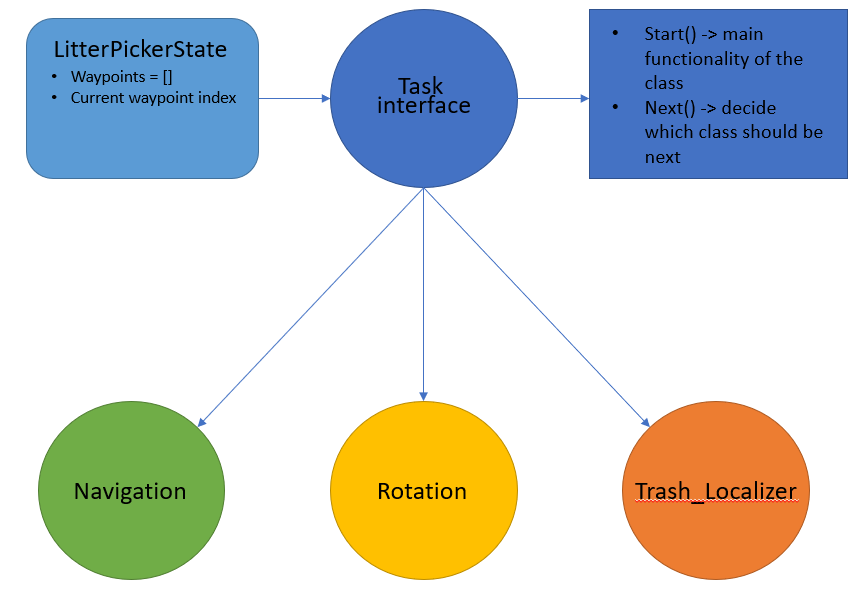


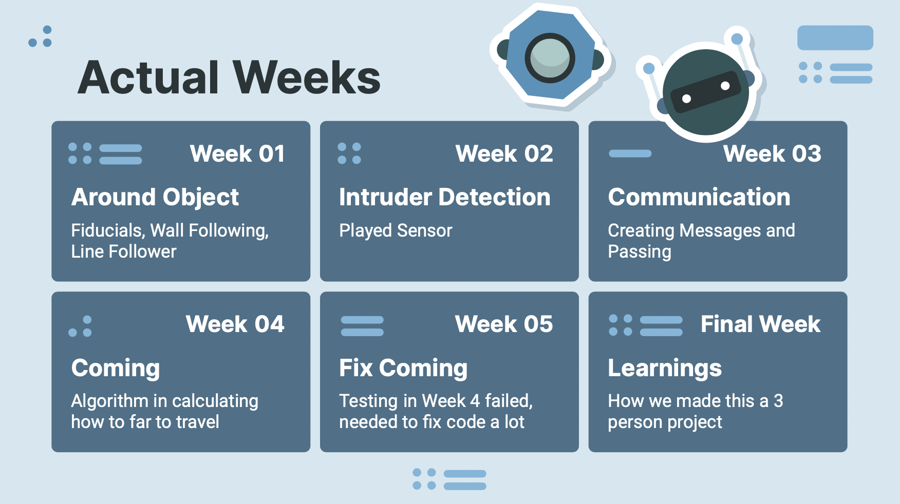
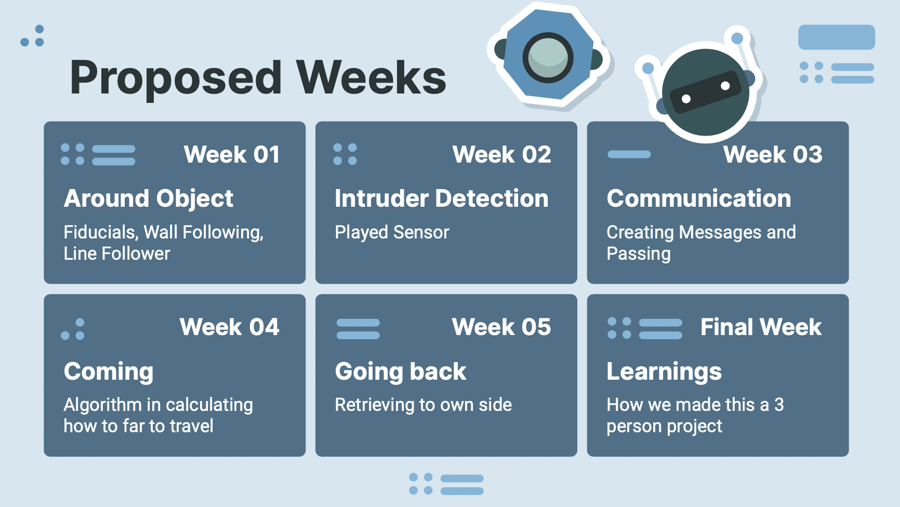

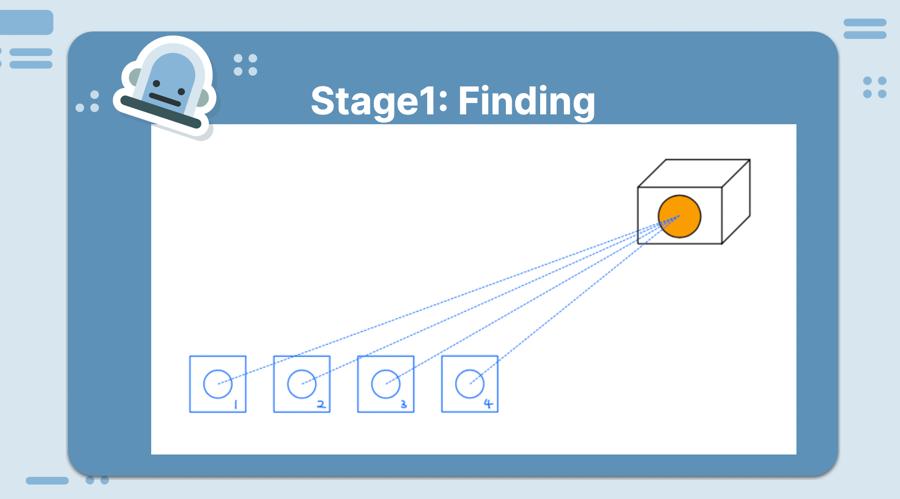
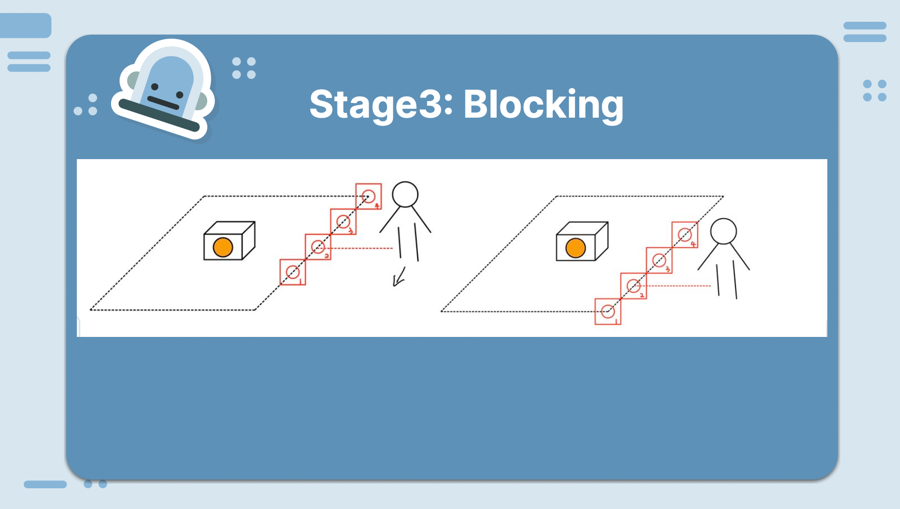
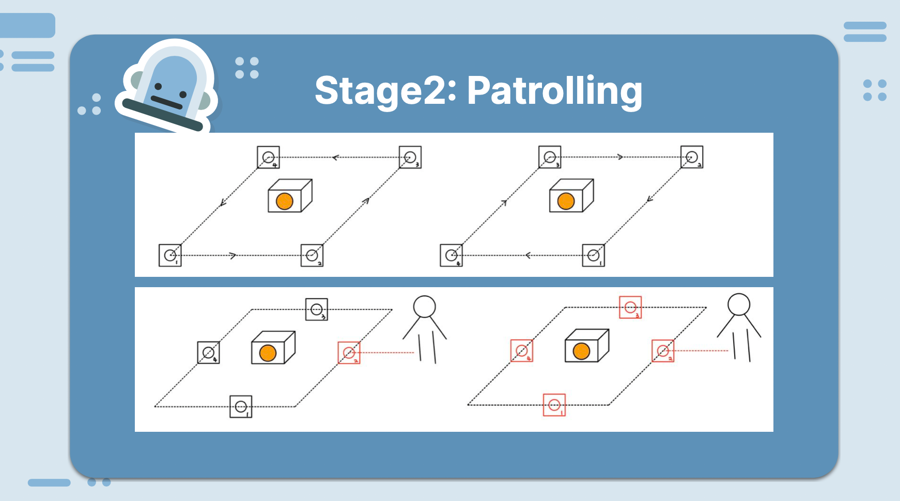
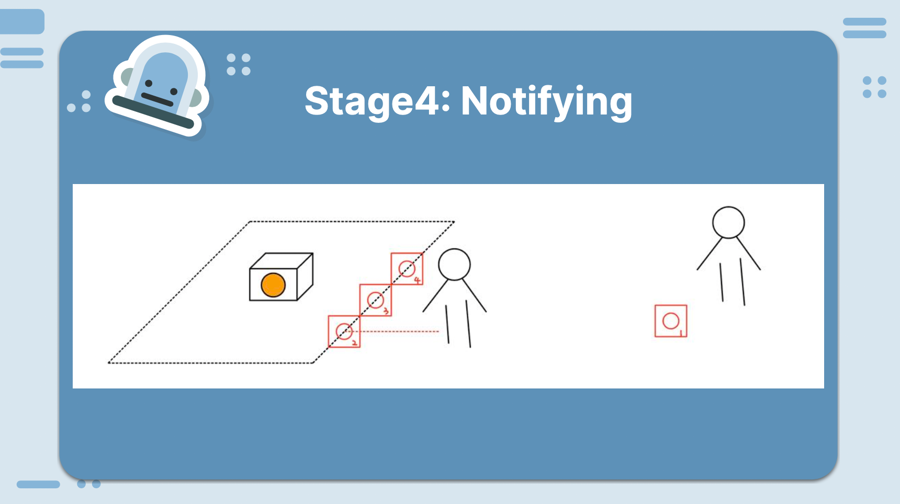



This still seems the best approach (if it ever worked). The Kinect camera was developed, at the first place,for human body gesture recognition and I could not think of any reason not using it but to reinvent wheels. However, since the library interfacing Kinect and ROS never worked and contains little documentation ( meaning it is very difficult to debug), I spent many sleepless nights and still wasn't able to get it working.However, for the next generation, I will still strongly recommend you give it a try.
ROS BY EXAMPLE V1 INDIGO: Chapter 10.9 contains detailed instructions on how to get the package openni_tracker working but make sure you install required drivers listed in chapter 10.3.1 before you start.
This semester I mainly worked on the hand gesture recognition feature. Honestly I spent most of the time learning new concepts and techniques because of my ignorance in this area. I tried several approaches (most of them failed) and I will briefly review them in terms of their robustness and reliability.
The campus rover behavior tree project was conceived of as a potential avenue of exploration for campus rover’s planning framework. Behavior trees are a relatively new development in robotics, having been adapted from non-player character AI in the video game industry around 2012. They offer an alternative to finite state machine control that is both straightforward and highly extensible, utilizing a parent-child hierarchy of actions and control nodes to perform complex actions. The base control nodes - sequence, selector, and parallel - are used to dictate the overarching logic and runtime order of action nodes and other behavior subtrees. Because of their modular nature, behavior trees can be both combined and procedurally generated, even used as evolving species for genetic algorithms, as documented by Collendachise, Ogren, and others. Numerous graphical user interfaces make behavior trees yet more accessible to the practicing technician, evidenced by the many behavior tree assets available to game designers now as well as more recent attempts such as CoSTAR used for robotics. My aim for this project, then, was to implement these trees to be fully integrable with Python and ROS, discover the most user-friendly way to interact with them for future generations of campus rover, and integrate my library with the current campus rover codebase by communicating with move_base and sequencing navigation while, optimistically, replacing its finite state machine structure with predefined trees.
For the most part, I was successful in accomplishing these goals, and the final result can be found at https://github.com/chris8736/robot_behavior_trees. This repository contains a working behavior tree codebase written entirely in Python with ROS integration, including all main control nodes, some decorator nodes, and simple processes to create new action and condition nodes. Secondly, I was able to implement a unique command parser to interpret command strings to autonomously generate behavior trees designed to run. This command parser was later used to read a sequence of plain English statements from a text file, providing a means for anyone to construct a specific behavior tree with no knowledge of code. Thirdly, I was able to merge my project seamlessly with the robot arm interface project and the campus rover navigation stack to easily perform sequenced and parallel actions.
The codebase is inspired by the organization of the C++ ROS-Behavior-Trees package, found here: https://github.com/miccol/ROS-Behavior-Tree. Though powerful, I found this package somewhat unsupportive of new Python nodes, requiring obscure changes to catkin’s CMakeLists text file after every new action node or tree declaration. Despite this, I found the package’s overall organization neat and its philosophy of implementing behavior tree action nodes as ROS action servers sensible, so I attempted to adopt them. Rather than have singular action nodes, I implement auxillary client nodes that call pre-instantiated action servers that may in the future accept unique goals and provide feedback messages. For now, these action servers simply execute methods that may publish ROS topics, such as moving forward for two seconds, twisting 90 degrees clockwise, or just printing to console. This modified structure is shown below, in a program that moves forward and backward if battery is sufficient:
Control nodes - e.g. sequence, parallel, and selector nodes - are normal Python classes not represented by ROS nodes. I connect these classes and client nodes via parent-child relationships, such that success is implicitly propagated up the tree, and resets naturally propagate down. With these node files alone, behavior trees can be explicitly defined and run in a separate Python file through manually setting children to parent nodes.
My command parsing script simply reads in strings from console or lines in a text file and interprets them as instructions for constructing a novel behavior tree. It utilizes the shunting-yard algorithm along with a dictionary of keywords to parse complex and potentially infinitely long commands, giving the illusion of natural language processing. Shunting-yard splits keywords recognized in the input string into a stack of values and a stack of operators, in this case allowing logic keywords such as “and” to access its surrounding phrases and set them as children of a control node. In addition to storing keys of phrases, the dictionary also holds references to important classes required to build the tree, such as condition nodes and action servers. The below figure shows example execution for the command “move forward then twist right and print hello” (note: one action represents both the client and server nodes):
On its own, this approach has its limitations, namely that all the trees it creates will be strictly binary and right-heavy. I was able to solve the latter problem while implementing file parsing through the keyword “is”, allowing keywords to reference entire subtrees through commands such as:
More complex behaviors can thus be built from the bottom up, allowing for multiple levels of abstraction. Conciseness and good documentation allow this codebase to be highly modular. By inheriting from general Action and Condition node classes, making an external process an action or condition requires only a few extra lines of code, while incorporating it into the command parser requires only a dictionary assignment. This ease of use allowed me to very quickly implement action nodes referencing move_base to navigate campus rover towards landmarks, as well as actions publishing to the robot arm interface to make it perform sequenced gestures.
I began this project by searching online for behavior tree libraries I could use to further my understanding of and expedite my work. Within this week of searching, I settled on ROS-Behavior-Trees, utilized by Collendachise in the above literature. Though I succeeded at running the example code and writing up new Python action nodes, I had great difficulty attaching those new nodes to the library’s control nodes, written entirely in C++. After a particularly inefficient week, I decided to switch gears and move on to my own implementation, referencing the C++ library’s architecture and the literature’s pseudocode to set up my main nodes. Though successful, I found writing up a whole python file to represent a behavior tree while having to remember which parent-child relationships I had already set exceedingly inconvienient.
As the third generation of campus rover was not yet stable by this time, I decided the best use of my remaining time was to make the use of my code more intuitive, leading me to the command parser. I had used the shunting-yard algorithm in the past to parse numerical expressions, and was curious to see if it would work for lexical ones as well. Though it was challenging to hook up each of my servers to a unique key phrase while importing across directories, I eventually made something workable without any major roadblocks.
When I was finally able to get campus rover running on my machine, I had only a few weeks left to understand its code structure, map which topics I was to publish to, and rewrite existing action functionality with parameterized arguments if I wanted to do a meaningful integration. Though I worked hard to identify where navigation requests were sent and found success in having getting a robot find its way to the lab door, AMCL proved to be unreliable over many trials, and I struggled to figure out how to write new action goals to make even a surface level integration work with all landmarks. With the hope of making behavior trees easier to understand and access for future developers, I instead used the remaining time to refine my command parser, allowing it to read from file with all the functionality I mention above.
All things considered, I feel I have satisfied nearly all the initial goals I could have realistically hoped to accomplish. I made my own behavior tree library from scratch with no previous knowledge of the topic, and I find my codebase both very easy and enjoyable to work with. Though I was unable to work with campus rover for the majority of the final project session, I proved that integrating my codebase with outside projects through ROS could be done incredibly quickly. Finally, I was able to make progress in what I believe to be an unexplored problem - interpreting human commands to generate plans robots can use in the future.
https://ieeexplore.ieee.org/abstract/document/6907656
https://ieeexplore.ieee.org/abstract/document/7790863
https://ieeexplore.ieee.org/abstract/document/8319483
https://ieeexplore.ieee.org/abstract/document/7989070
As said before, we need a reliable way to extract hands. The first approach I tried was to extract hands by colors: we can wear gloves with striking colors (green, blue and etc) and desired hand regions can be obtained by doing color filtering. This approach sometimes worked fine but easily got distracted by subtle changes in lighting at most of the time. In a word, it was not robust enough. After speaking to Prof. Hong, I realized this approached had been tried by hundreds of people decades ago and will never work. Code can be found .

The use of deep convolutional neural networks has enjoyed unprecedented success over the past decade in applications everywhere from facial recognition to autonomous navigation in vehicles. Thus, it seemed appropriate for our project that such techniques would be optimal. We decided our best methodology for allowing a robot to ‘understand’ a wet floor sign was to train a deep convolutional neural network on images of a yellow wet floor sign. Upon further research of this problem statement and methodology, we discovered a research paper from ETH Zurich that seemed to best fit our needs. The paper, written in 2018, details how ETH Zurich’s Autonomous Formula One Racing Team computes the 3D pose of the traffic cones lining the track. Although we only have about six weeks to complete our project, we ambitiously set out to replicate their results. We would take their methodology and apply it to our wet floor sign problem. Their methodology consisted of three main phases. Phase 1 would be to perform object detection on a frame inputted from the racing car’s camera and output the 2D location of the traffic cone. We specify 2D because it is important to note that detection of obstacles in an image frame consists not of two coordinates, but of three. In this first phase, the researchers from ETH Zurich were only concerned with the computation of the location of bounding boxes around the cone within the frame. The output of this model would provide a probability that the detected bounding box contains a cone and what the x- and y-coordinates of the bounding box were in the image frame. The neural network architecture employed by the researchers was the YoloV3 architecture. Additionally, the researches trained this network on 2,000 frames labelled with the bounding box coordinates around the cones. In the second phase of the paper, a neural network was trained to regress the location of key points of the cones. For instance, the input to this network was the cropped bounding box region of where a cone was in the frame. This cropped image was then labelled with ‘key points’, specific locations on the cone that the second neural network would be trained. From there, once we have at least four points on the cone, knowing the geometry of the cone and calibration of the camera, the perspective n-points can be used to find the 3D pose of the cone.
Using the research paper as our guidelines, we set out to replicate their results. First came building the dataset that would be used for training both of our neural networks. We needed a yellow wet floor sign so we took one from a bathroom in Rabb. Over the course of two weeks, we teleoperated a Turtlebot3 around various indoor environments, driving it into the yellow wet floor sign, recording the camera data. From there, we labelled over 2,000 frames, placing bounding boxes around the yellow wet floor sign. This was by far the most tedious process we faced. From there, we needed to find a way to train a neural network to generalize on new frames. Upon further research, we came across a GitHub repository that was an implementation of the Yolov3 architecture in Keras and Python. There was quite a bit of configuration but we eventually were able to clone the repository onto our local machines and pass our data through it. However, the passing of data through our network required a significant amount of computation, and hence, we encountered our first roadblock. Needing a computer with greater computational resources, we turned to the Google Cloud Platform. We created a new account and were given a trial $300 in cloud credits. We created a virtual machine that we added two P100 GPUs. Graphic processing units are processors specifically made for rendering graphics. Although we were not rendering graphics, GPUs are used to processing tensors and thus, would perform the tensor and matrix computations at each node of the neural network with greater speed than standard central processing units. Once we trained a model to recognize the yellow wet floor signs, we turned our attention over to the infrastructure side of our project. This decision to focus on incremental steps proved to be our best decision yet as this was the aspect of our project with the most amount of bottlenecks. When trying to create our program, we encountered several errors with using Keras in the ROS environment. Notorious to debug, there were several errors within the compilation and execution of the training of the neural network that were impossible to solve after a couple weeks of figuring it out. We pivoted once again, starting from scratch and training a new implementation of the Yolov3 architecture. However, this repository was written in Pytorch, an API for deep learning that was more compatible with the ROS environment.
Using Torch instead of Keras, we moved towards repositories and restarted training with our old dataset. In this particular pivot, we approximately ~500 frames from the old 2,000 frame dataset was relabeled in Pascal VOC format instead of YOLO weights format. This decision was made to make training easier on Jesse's GPU. To replicate our training of YOLO weights on a custom data set, we followed this process below:
Firstly, decide upon an annotation style for the dataset. We initially had annotations in YOLO formats and then in Pascal VOC formats. These are illustrated below.
Example Pascal VOC annotation
Each frame should have an accompanied annotation file. Example ('atrium.jpg' and 'atrium.xml'). Pascal VOC is in XML format, and should include the path, height, width, and channels for the image. In addition, there should be the class of the image in the name section, as well as any bounding boxes (including their respective x and y).
Example YOLO annotation
Similarly, each frame should have an accompanying text file. For example ('atrium.jpg' and 'atrium.txt'). These should also be in the same directory with the same name.
In this txt file, each line of the file should represent an object which an object number, and its coordinates in the image. As seen below in the form of:
line: object-class x y width height
The object class should be an integer that is represented on the names file that the training script shall read from. (0 - Dog, 1 - Cat, etc).
The x, y, width, and height, should be float values that are to the width and height of the image (these are floats between 0.0 and 1.0)
Training Configurations
As we were retraining weights from PJReddie's site. It is here that one can find some of the pretrained weights for different YOLO implementations and their performance in mAP and FLOPS on the COCO dataset. The COCO dataset is a popular dataset for training in object detection and is called the Common Objects in Context dataset that includes over a quarter of a million images.
For our initial training, we used the YOLOv3-416 configuration and weights for 416 by 416 sized images, as well as the YOLOv3 tiny configuration and weights in the event of latency issues. Modifications were made in the yolov3.cfg file that we used for training for our single class inference.
Since we are doing single class detection our data and names file looks as so:
Fairly sparse as one can see, but easily modifiable in the event of training multiple class objects.
Actual training was done using the train.py script in our github repo. We played around with a couple hyper-parameters, but stuck with 25 epochs training in batch sizes of 16 on the 500 Pascal VOC labeled frames. Even with only 20 epochs, training on Jesse's slow GPU took approximately 20 hours.
Unfortunately, valuable data on our loss, recall, and precision were lost as laptop used to train unexpectedly died overnight during the training process. Lack of foresight resulted in not being able to collect these metrics during the training as they were to be conglomerated after every epoch finished. Luckily, the weights of 19 epochs were recovered in checkpoints however their performance had to be manually tested.
Prediction
Inference via the turtlebot3s are done via a ROS node on a laptop that subscribes to the turtlebot's rpi camera, does some minor image augmentations and then saves the image to a 'views' directory. From this directory, a YOLO runner program is checking for recently modified files, then subsequently performs inference, draws bounding box predictions on said files and then writes to a text file with results as well as the modified frame.
The rational behind reading and writing files instead of predicting on ROS nodes from the camera is a result of struggles throughout the semester to successfully integrate Tensorflow graphs onto the ROS system. We ran into numerous session problems with Keras implementations, and ultimately decided on moving nearly all of the processing from the turtlebot3 into the accompanying laptop. This allows us to (nearly) get inference real time given frames from the turtlebot3.
An alternate way of doing inference, but in this case doing object detection with items with the COCO dataset rather than our custom dataset can be run via our yolo_runner.py node directly on ROS. This is an approach that does not utilize read/write and instead prints predictions and bounding boxes to the screen. However, with this approach drawing to the screen was cut due to how it lagged the process when attempting to perform inference on the turtlebot3's frames.
This project was a strong lesson in the risks of attempting a large project in a short time span that combines two complex fields within computer science (Robotics and Machine Learning) whilst learning much of it on the go. It was quite humbling to be very ambitious with our project goals and fall short of many of the "exciting" parts of the project. However, it was also a pleasure to have the freedom to work on and learn continuously while attempting to deploy models and demos to some fairly cutting edge problems. Overall, this made the experience a learning experience that resulted in not only many hours of head-banging and lost progress but also a deeper appreciation for the application of computer vision in robotics and the challenges of those who helped pave the way for our own small success.
The two largest challenges in the project was data collection for our custom dataset and integration with ROS. That is, creating and annotating a custom dataset took longer than expected and we ran into trouble with training where our images were perhaps not distinct enough/did not cover enough environments for our weights to make sufficient progress. For integration, we ran into issues between python2 and python3, problems with integrating Keras with ROS, and other integration issues that greatly slowed the pace of the project. This made us realize that in the future, not to discount the work required for integration across platforms and frameworks.
References:
As a very last minute and spontaneous approach, we decided to use a Leap Motion device. Leap Motion uses an Orion SDK, two IR camerad and three infared LEDs. This is able to generate a roughly hemispherical area where the motions are tracked.
It has a smaller observation area dn higher resolution of the device that differentiates the product from using a Kinect (which is more of whole body tracking in a large space). This localized apparatus makes it easier to just look for a hand and track those movements.
The set up is relatively simple and just involved downloading for the appropriate OS. In this case, Linux (x86 for a 32 bit Ubuntu system).
download the SDK from https://www.leapmotion.com/setup/linux; you can extract this package and you will find two DEB files that can be installed on Ubuntu.
Open Terminal on the extracted location and install the DEB file using the following command (for 64-bit PCs):
$ sudo dpkg -install Leap-*-x64.deb
If you are installing it on a 32-bit PC, you can use the following command:
Once having Leap Motion installed, we were able to simulate it on RViz. We decided to program our own motion controls based on angular and linear parameters (looking at directional and normal vectors that leap motion senses):
This is what the Leap Motion sees (the raw info):
In the second image above, the x y and z parameters indicate where the leap motion detects a hand (pictured in the first photo)
This is how the hand gestures looked relative to the robot's motion:
So, we got the Leap Motion to successfully work and are able to have the robot follow our two designated motion. We could have done many more if we had discovered this solution earlier. One important thing to note is that at this moment we are not able to mount the Leap Motion onto the physical robot as LeapMotion is not supported by the Raspberry Pi (amd64). If we are able to obtain an Atomic Pi, this project should be able to be furthered explored. Leap Motion is a very powerful and accurate piece of technology that was much easier to work with than the Kinect, but I advise still exploring both options.
https://github.com/campusrover/gesture_recognition
The final approach I took was deep learning. I used a pre-trained SSD (Single Shot multibox Detector) model to recongnize hands. The model was trained on the Egohands Dataset, which contains 4800 hand-labeled JPEG files (720x1280px). Code can be found here
Raw images from the robot’s camera are sent to another local device where the SSD model can be applied to recognize hands within those images. A filtering method was also applied to only recognize hands that are close enough to the camera.
After processing raw images from the robot, a message (hands recognized or not) will be sent to the State Manager. The robot will take corresponding actions based on messages received.
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy,Scott E. Reed, Cheng-Yang Fu, and Alexander C. Berg. SSD: single shot multibox detector. CoRR, abs/1512.02325, 2015. Victor Dibia, Real-time Hand-Detection using Neural Networks (SSD) on Tensorflow, (2017), GitHub repository,
Intro
In Kinect.md, the previous generations dicussed the prospects and limitations of using a Kinect camera. We attempted to use the new Kinect camera v2, which was released in 2014.
Thus, we used the libfreenect2 package to download all the appropiate files to get the raw image output on our Windows. The following link includes instructions on how to install it all properly onto a Linux OS.
https://github.com/OpenKinect/libfreenect2
We ran into a lot of issues whilst trying to install the drivers, and it took about two weeks to even get the libfreenect2 drivers to work. The driver is able to support RGB image transfer, IR and depth image transfer, and registration of RGB and depth images. Here were some essential steps in debugging, and recommendations if you have the ideal hardware set up:
Even though it says optional, I say download OpenCL, under the "Other" option to correspond to Ubuntu 18.04+
If your PC has a Nvidia GPU, even better, I think that's the main reason I got libfreenect to work on my laptop as I had a GPU that was powerful enough to support depth processing (which was one of the main issues)
Be sure to install CUDA for your Nvidia GPU
Please look through this for common errors:
https://github.com/OpenKinect/libfreenect2/wiki/Troubleshooting
Although we got libfreenect2 to work and got the classifier model to locally work, we were unable to connect the two together. What this meant is that although we could use already saved PNGs that we found via a Kaggle database (that our pre-trained model used) and have the ML model process those gestures, we could not get the live, raw input of depth images from the kinect camera. We kept running into errors, especially an import error that could not read the freenect module. I think it is a solvable bug if there was time to explore it, so I also believe it should continued to be looked at.
However, also fair warning that it is difficult to mount on the campus rover, so I would just be aware of all the drawbacks with the kinect before choosing that as the primary hardware.
https://www.kaggle.com/gti-upm/leapgestrecog/data
https://github.com/filipefborba/HandRecognition/blob/master/project3/project3.ipynb
What this model predicts: Predicted Thumb Down Predicted Palm (H), Predicted L, Predicted Fist (H), Predicted Fist (V), Predicted Thumbs up, Predicted Index, Predicted OK, Predicted Palm (V), Predicted C
As a very last minute and spontaneous approach, we decided to use a Leap Motion device. Leap Motion uses an Orion SDK, two IR camerad and three infared LEDs. This is able to generate a roughly hemispherical area where the motions are tracked.
It has a smaller observation area dn higher resolution of the device that differentiates the product from using a Kinect (which is more of whole body tracking in a large space). This localized apparatus makes it easier to just look for a hand and track those movements.
The set up is relatively simple and just involved downloading for the appropriate OS. In this case, Linux (x86 for a 32 bit Ubuntu system).
download the SDK from https://www.leapmotion.com/setup/linux; you can extract this package and you will find two DEB files that can be installed on Ubuntu.
Open Terminal on the extracted location and install the DEB file using the following command (for 64-bit PCs):
$ sudo dpkg -install Leap-*-x64.deb
If you are installing it on a 32-bit PC, you can use the following command:
Once having Leap Motion installed, we were able to simulate it on RViz. We decided to program our own motion controls based on angular and linear parameters (looking at directional and normal vectors that leap motion senses):
This is what the Leap Motion sees (the raw info):
In the second image above, the x y and z parameters indicate where the leap motion detects a hand (pictured in the first photo)
This is how the hand gestures looked relative to the robot's motion:
So, we got the Leap Motion to successfully work and are able to have the robot follow our two designated motion. We could have done many more if we had discovered this solution earlier. One important thing to note is that at this moment we are not able to mount the Leap Motion onto the physical robot as LeapMotion is not supported by the Raspberry Pi (amd64). If we are able to obtain an Atomic Pi, this project should be able to be furthered explored. Leap Motion is a very powerful and accurate piece of technology that was much easier to work with than the Kinect, but I advise still exploring both options.
Cosi 119a - Autonomous Robotics
Team: Stalkerbot
Team members: Danbing Chen, Maxwell Hunsinger
Github Repository: https://github.com/campusrover/stalkerbot
Final Report
<annotation>
<folder>signs_images</folder>
<filename>atriuma2.jpg</filename>
<path>/Users/jesseyang/Desktop/signs_images/atriuma2.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>416</width>
<height>416</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>232</xmin>
<ymin>218</ymin>
<xmax>281</xmax>
<ymax>290</ymax>
</bndbox>
</object>
</annotation>1 0.716797 0.395833 0.216406 0.147222
0 0.687109 0.379167 0.255469 0.158333
1 0.420312 0.395833 0.140625 0.166667classes=1
train=data/signs/train.txt
valid=data/signs/val.txt
names=config/coco.names
backup=backup/signplug in leap motion and type dmesg in terminal to see if it is detected
clone ros drivers:
$ git clone https://github.com/ros-drivers/leap_motion
edit .bashrc:
export LEAP_SDK=$LEAP_SDK:$HOME/LeapSDK
export PYTHONPATH=$PYTHONPATH:$HOME/LeapSDK/lib:$HOME/LeapSDK/lib/x64
save bashrc and restart terminal then run:
sudo cp $LeapSDK/lib/x86/libLeap.so /usr/local/lib
sudo ldconfig
catkin_make install --pkg leap_motion
to test run:
sudo leapd
roslaunch leap_motion sensor_sender.launch
rostopic list


Install OpenNI2 if possible
Make sure you build in the right location
plug in leap motion and type dmesg in terminal to see if it is detected
clone ros drivers:
$ git clone https://github.com/ros-drivers/leap_motion
edit .bashrc:
export LEAP_SDK=$LEAP_SDK:$HOME/LeapSDK
export PYTHONPATH=$PYTHONPATH:$HOME/LeapSDK/lib:$HOME/LeapSDK/lib/x64
save bashrc and restart terminal then run:
sudo cp $LeapSDK/lib/x86/libLeap.so /usr/local/lib
sudo ldconfig
catkin_make install --pkg leap_motion
to test run:
sudo leapd
roslaunch leap_motion sensor_sender.launch
rostopic list
In the recent years, the pace of development of autonomous robotics has quickened, due to the increase in demand for robots which perform actions in the absence of human control and minimal human surveillance. The robots are through the years more capable of performing an ever-various range of tasks, and one such task, which has become more prevalence in the capabilities of modern robots, is the ability to follow a person. Robots which are capable of following people are widely deployed and used for caretaking and assistance purposes.
Although the premise of a person-follow algorithm is simple, in practice the algorithm must consider several complexities and challenges, some of which depend on the general purpose of such said robots, and some of which are due to the inherent complication of the practice of robotics.
Stalkerbot is an algorithm which detects and follows the targeted individual until the robot has reached a certain distance within the target, which then it will stop. Although the algorithm has the capability to detect and avoid obstacles, it does not operate well in a spatially crowded environment where the room for robotic maneuver is limited. The algorithm works well only in an environment with enough light exposure; hence it will not function properly or at all in the darkness.
One of the most basic and perhaps fundamental challenge of such algorithm is the recognition of the targeted person. The ability of the algorithm to quickly and accurately identify and focus on the target is crucial, as it is closely linked to most of the other parts of the algorithm, which may include path finding, obstacle avoidance, motion detect, etc.
Although there are sophisticated methods of recognizing the potential target, including 3D Point Clouds and convoluted computer vision algorithms, our project will only be using a rather simple library in rospy called the Aruco Detect, which is a fiducial marker detection library which can detect and identify specific markers using a camera and return the pose and transformation of the fiducial. We chose to use the library because it is simple to implement and does not involve sophisticated and heavy computation such as machine learning, with, of course, the downside of the algorithm’s having dependency on fiducial marker as well as the library.
We will be using SLAM for local mapping of the robot, which takes in lidar data and generate the map of its immediate surroundings. We will also be using ros_navigation package, or more specifically, the move_base module in the package to facilitate the path finding algorithm of Stalkerbot. It is important to note that these two packages make up most of the computational consumption of the algorithm, as the rest of the generic scripts written in Python are standard, light-weight ROS nodes.
Sensors are the foundation of every robotics application, they are to bridge the gap between the digital world and the real world, they give perception to robots and allow them to respond to the changes in the real world, therefore it is not surprising that the other defining characteristics of a path finding algorithm is its sensors.
The sensors which we use for our algorithm are the lidar and the raspberry-pi camera. Camera will be used to detect the target via the aforementioned Aruco Detect library. We will support the detection algorithm with sensor data from the lidar which is equipped on the Turtlebot. These data will be used to map the surroundings of the robot in real time and play an important part in the path planning algorithm, which will enable the robot to detect and avoid obstacles on the path to the target.
On the Turtlebot3, the camera will be installed in the front at an inclination of about 35 degrees upwards and the lidar is installed at around 10cm above the ground level. These premises are important factors in the consideration of the design of the algorithm, and they often ease or pose limitations on the design space of the algorithm. In addition, the Turtlebot runs on Raspberry-pi 3 board. The board is adequate for running simple programming scripts; however, they are not fit to run computationally heavy script such as Aruco Detect or SLAM, therefore, these programs have to be run remotely and the data will have to be communicated to the robots wirelessly.
The very first design choice which we must consider is this: Where does the robot go? The question might sound simple, or even silly, because the goal of the algorithm is to follow a person, so the target of the robot must be the person which it follows. However, it is important to remember that the robot does not reach the target, instead it follows the target up to a certain distance behind the target, therefore a second likely choice for which where the robot should aim to move to is the point which is at said distance behind the target.
The two different approaches translate to two very different behaviors of the robots, for example, a direct following approach reacts minimally to the target’s sudden change in rotation, whereas the indirect following approach reacts more drastically to it. It should be said that under different situations one might be better than the other. If the target simply rotates but does not turn, for example, then by using the direct approach the robot would stand still, however, if the target intends to rotate, then the indirect approach helps more adequately to better prepare for the change of course preemptively than the direct approach.
We have chosen the direct approach in the development of Stalkerbot, because even though the indirect approach is often the more advantageous approach in many situations, it has a severe drawback that is associated with how the camera is mounted on the robot. For example, when the target turns, the robot must move side-ways, and since its wheels are not omnidirectional, but bidirectional, the robot must turn to move to the appropriate spot, and in term lose sight of the target in the process, because the robot can only detect what is in front of it, since the camera is mounted directly ahead of the robot, and no additional camera is mounted on the robot. The continuous update of the state of the target is crucial in the algorithm, and the lack of the information on the target is unjustifiable, hence the indirect approach is not considered.
Fiducial markers can be identified by their unique barcode-like patterns, and each is assigned an identification number. We only want to identify specific fiducial markers. The reason which we want to do this is this: there are other projects, including the campus_rover_3, who are using the same library as we do, and we do not wish to confuse the robots with the fiducials from other projects. All the accepted fiducials are stored as their identification number in an array in the configuration file. The node fiducial_filter filters out unwanted fiducial markers and republishes those that match against the fiducial markers whose identification number is in the configuration file.
It is important to ensure that the robot follows the target in a smooth manner. However, the detection capability with the camera which is mounted on the robot is not perfect. Although Aruco Detect can detect the fiducial markers, it is awfully inconsistent, and the detection rate drops significantly with distance, with the marker becoming almost impossible to detect at any distance farther than 2.5 meters. At normal range, it is expected that the algorithm will miss certain frames. To ensure the smoothness of the robot’s motor movement, a buffer time is introduced to the follow algorithm to take the momentary loss of information on the state of the target into account. If the robot is unable to detect any fiducial marker within this buffer duration, it will keep moving as if the target is still at the place when it is last detected, however when the robot is still unable to detect any markers after that grace period, the robot will stop. We have found that 200 milliseconds to be an appropriate time, with which the robot will run smoothly even if the detection algorithm does not.
These algorithms are contained in the advanced_follow node, which is also where all of the motion algorithms lie. This node is responsible for how the robot reacts to the change in the sensor data, therefore, this node can be seen as the core of the person-following algorithm. The details of this node will be explained further later in this section.
In order to compare the time elapsed since the robot has last recognized a fiducial marker and the current time, we have created a ROS node called fiducial_interval, which measures the time since the last fiducial marker is detected. Note that when the algorithm first starts, and no fiducial is detected, the node will publish nothing. Only when the first fiducial marker is detected, then the node will be activated and start to publish the duration.
Aruco Detect publishes the information on the fiducial markers which the robot detects, however, to extract and filter the important data (pose, mainly), and to filter the unwanted data (timestamp, id, fiducial size, error rate, etc), we have created a custom node called location_pub, which subscribes to fiducial_filter and publishes only the important information which will be useful for the Stalkerbot algorithm.
One of the biggest components of Stalkerbot is its communication with the ros_tf package. The package is a powerful library that aligns the locations and orientations of different objects that have coordinates on different coordinate frames. In Stalkerbot, we feed information of the relationship between two frames into ros_tf and we also extract those data from it. We require this because it is otherwise difficult to understand and calculate the pose of an object from, for example, the robot, when the data is gathered by the camera, which uses a different coordinate system, or frame, as the robot.
The node location_pub_tf publishes to ros_tf the pose of an object as perceived by another object. In the node, two different relationships are transmitted to ros_tf. Firstly, the node broadcasts a static pose of the camera from the robot. The pose is static because the camera is mounted on the robot and the pose between them will not change during the execution and runtime of Stalkerbot. Because it is a static broadcast, the pose is sent to ros_tf once, at the beginning of the algorithm, via a special broadcast object that specifies this broadcast is static. Furthermore, the node will, at a certain frequency, listen to the topic /stalkerbot/fiducial/transform and broadcast the pose of the target with respective to the frame of the camera to ros_tf. Note that, just like the node fiducial_interval, nothing will be broadcasted before the detection of the first fiducial marker.
Like mentioned before, not only do we broadcast the coordinates to ros_tf, we also request them from it as well. In fact, the only place where we request for any coordinates between two objects is in the advanced_follow node. The advanced follow node uses, additionally, the move_base module from ros_nav, however, to send a goal to the module requires the algorithm to have the coordinate frame between the frame map and target. Therefore, at a certain frequency, the node requests the pose between map and target from ros_tf. When the robot reaches the destination and the target is not in motion for a certain number of seconds, the follow algorithm will shut itself down. The detection of motion is contained in the motion_detect node. This is an algorithm just as complicated as the follow algorithm. It listens to the ros_tf transform between the robot and the target and calculate the distance from the pose of the current frame to the last known frame. However, most of the logic issued in this node is to enable the algorithm to recognize motion and the lack of motion in the presence of sensory noise. It uses average mean and a fluctuating distance threshold level to determine whether the object is moving at any given moment.
The node also implements a lingering algorithm which has a counter which counts down when the rest of the algorithm returns false and reverts the response to positive. When the counter reaches zero, it is no longer able to revert any negative response. The counter is reset when a fiducial marker is detected. This is again a method to combat the inconsistency of Aruco Detect, you can think of the counter as the minimal number of times the algorithm will return true. However, during the development stage, this method is not used anymore. The counter is specified to 0 according to the configuration file. Similar to fiducial_filter, it also has its corresponding interval node, motion_interval, which returns the time since the last time when the target is in motion.
Lastly, Stalkerbot also implements a special node called sigint_catcher, in which the node only activates when the program is terminated via KeyboardInterrupt. The only purpose of this node is to send an empty cmd_vel to roscore, thereby stopping the robot.
The inspiration for this project is a crowdfunding project that was initiated by a company called "Cowarobot", which aims to create the world's first auto-following suitcase/luggage. This project is a scaled-down version of this project. Initially, we had great ambitions for the project; we had plans to use facial recognition and machine learning to recognize the target which the robot follows, however, it is soon clear to us that given our expertise, the time which we have, and the scale of the problem, we have to scale down the ambition of the project as well. At the end of the project proposal period, we have made a very conservative model for our project – A robot follows a person wearing the fiducial marker in an open, obstacle-free environment, and we are glad to say that we have achieved this very basic goal and some more.
Over the course of the few weeks which we spent working on Stalkerbot, there arose numerous challenges, most of them were the result of our lack of deep understanding of ROS and robotic hardware. The two biggest challenge were the following: The inconsistency of the camera and Aruco Detect was our first big obstacle. We followed the lab instruction on how to enable the camera on the robot, however, for our project, a custom exposure mode is needed to improve the performance of the camera, and it took us some time to figure out how the camera should exactly be correctly configurated. However, over the course of the entire development of Stalkerbot, Aruco Detect sometimes cannot pick up on the fiducial markers. Sometimes, it is unable to detect any markers altogether at certain specific camera settings.
The second challenge is the ros_tf library, and in general how orientation and pose function in the 3D world. At the beginning of the algorithm development, we did not have to deal with poses and orientations, but when we had to deal with them, we realized the poses and orientations we thought were aligned were all over the place. It turned out, that the axes used by Aruco Detect and ros_tf were different. The x axis in ros_tf is the y axis in Aruco Detect, for example. In addition, communicating with ros_tf requires a good understanding of the package as well as spatial orientation. There are many pitfalls, such as mixing the target frame and the child frame, mixing up the map frame and the odom frame.
Over the course of the development, Danbing worked on the basic follow algorithm, fiducial_filter, fiducial_interval, motion_detect, detect_interval, and sigint_catcher. Max worked on location_pub, move_base_follow and the integration of move_base_follow to make advanced_follow.
















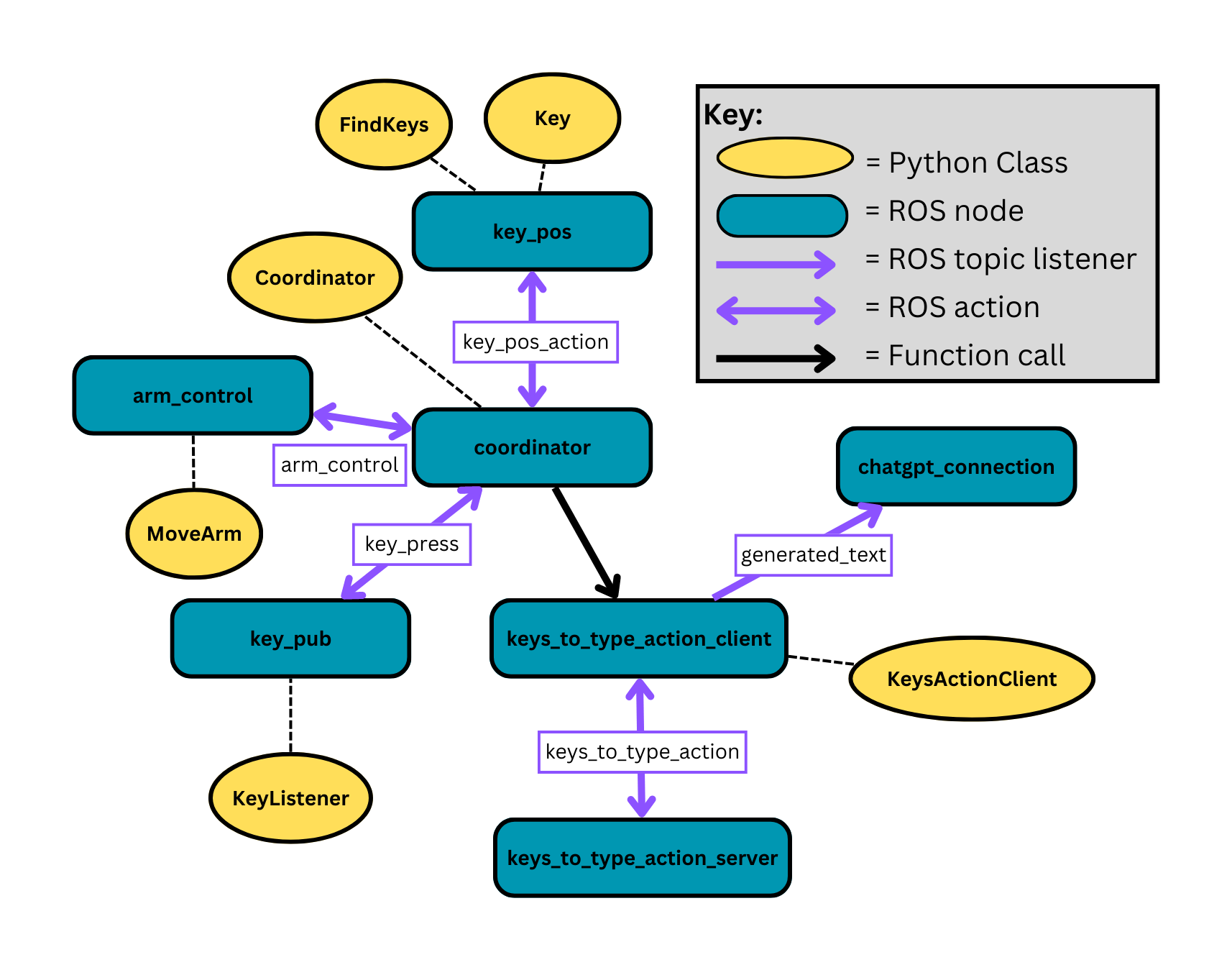
As a very last minute and spontaneous approach, we decided to use a Leap Motion device. Leap Motion uses an Orion SDK, two IR camerad and three infared LEDs. This is able to generate a roughly hemispherical area where the motions are tracked.
It has a smaller observation area dn higher resolution of the device that differentiates the product from using a Kinect (which is more of whole body tracking in a large space). This localized apparatus makes it easier to just look for a hand and track those movements.
The set up is relatively simple and just involved downloading for the appropriate OS. In this case, Linux (x86 for a 32 bit Ubuntu system).
download the SDK from ; you can extract this package and you will find two DEB files that can be installed on Ubuntu.
Open Terminal on the extracted location and install the DEB file using the following command (for 64-bit PCs):
If you are installing it on a 32-bit PC, you can use the following command:
Once having Leap Motion installed, we were able to simulate it on RViz. We decided to program our own motion controls based on angular and linear parameters (looking at directional and normal vectors that leap motion senses):
This is what the Leap Motion sees (the raw info):
In the second image above, the x y and z parameters indicate where the leap motion detects a hand (pictured in the first photo)
This is how the hand gestures looked relative to the robot's motion:
So, we got the Leap Motion to successfully work and are able to have the robot follow our two designated motion. We could have done many more if we had discovered this solution earlier. One important thing to note is that at this moment we are not able to mount the Leap Motion onto the physical robot as LeapMotion is not supported by the Raspberry Pi (amd64). If we are able to obtain an Atomic Pi, this project should be able to be furthered explored. Leap Motion is a very powerful and accurate piece of technology that was much easier to work with than the Kinect, but I advise still exploring both options.
The current society considers robots as a crucial element. It is because they have substituted human beings concerning the daily functions, which could be dangerous or essential. Therefore, the designation of an effective technique of navigation for robots that can achieve mobility as well as making sure that they are secure is the crucial considerations related to autonomous robotics. The report, therefore, addresses the pathfinding in robots using A-Star Algorithm, Wavefront Algorithm, as well as using Reinforcement Learning. The primary aim of path planning in robotics is to establish safe paths for the robots that can achieve mobility. The preparation of routes in robotics should achieve optimality. These algorithms target the development of strategies that are intended to provide solutions to problems like the ability of a robot to detect the distance between objects that causes obstructions, techniques of evading the obstacles, as well as how to achieve mobility between two elements of blockage in the shortest possible path. Moreover, the project is meant to help in coming up with the shortest route, if possible, that the Robot can use to reach the destination.
When carrying out the project, there were a lot of resources, even though some were not directly addressing the issues, and I was able to get numerous information that helped in connecting the points and getting the right idea. Apart from the readily available internet sources, I as well-referred to several related papers, Professor Sutton's book, and Professor David Silver's lecture.
A two-dimensional environment where the robot training was to be undertaken was created. The atmosphere was made in such a way that for the Robot to finds its path from location A to B, there are several obstacles, destructions, and walls that would hinder it from getting to the destination. The result would be to identify how the Robot would meander through the barriers to reach the desired position. A robot sensor was used to help the robot to perceive the environment. To determine the best way of path determination, the following criteria were utilized, A star Algorithm and Wavefront Algorithm and Reinforcement Learning.
The technique is a crucial way of traversal of graphs and pathfinding. It has brains, unlike other traversal strategies and algorithms. The method can be efficiently adopted into ensuring that the shortest path is efficiently established. It is regarded as one of the most successful search algorithms, which are the best to be used to find the most concise way in the graphs and notes. The Algorithm uses heuristics to find the solution paths as well as the information concerning the path cost to come up with the best and shortest route. In this project, the use of the A-star Algorithm would be necessary for that it would help in the determination of the shortest path that can be used by the Robot to reach the destination. In working places or any other environment, we always look for the shortest routes which we can use to reach the target. The Robot was designed using this Algorithm, which helps in the productive interaction with the environment to find out the best paths that can be used to reach the destination. An example of an equation that shows this form algorithm is f(n) = g(n) + h(n) in which f(n) is the lowest cost in the node, g(n) is the exact cost of the path and h(n) the heuristic estimated cost from a node.
Path MAP
To make it more efficient and more tactical, the wavefront algorithm was utilized to help in determining the correct path that can be used by the Robot to reach the destination effectively. This type of Algorithm is regarded as a cell decomposition path method. When the workplace paths are divided into equal segments, getting the right paths can always be an issue; however, using this Algorithm will help to come up with the correct way that can easily use by the Robot in reaching the destination. The method uses the breadth-first search based on the position in which the target is. The nodes in this method are increasingly assigned values from the target note. At sometimes, the modified wavefront algorithm would be suggested in future research to come up with the best estimate of the path that is needed to be followed. The improved version of the system as well uses the notes; nevertheless, it provides for the most accurate results. In this project, for the remote censored Robot to find the correct path to reach the target faster, the wavefront algorithm was utilized.
In the allocation of the nodes, the following equation holds
Map (i,j) = {min (neighborhood (i j)) + 4 [empty diagonal cell]/ min (neighborhood (i j)) + 3 other empty cell obstacle cell]
The equation in shows the allocation of the nodes with reference to the coordinates (i,j). The algorithm thus provides a solution if it exists incompleteness and provides the best solution.
Path MAP
To ensure that the Robot is adequately trained on the environment to determine the best path that can quickly and faster lead to the target, a deep reinforcement algorithm will be necessary. The reinforcement algorithm will, therefore, be the component that will majorly control the Robot in the environment. For instance, the Algorithm will be planted on the Robot to help in avoiding the obstructions such that when the Robot is about to hit an obstacle, it will quickly sense the obstacle and change the direction but leading to the target. Moreover, deep learning with help the Robot to get used to the environment of operation. It is said that the Robot is as well able to master the path through the deep learning inclusions. Still and moving obstacles can only be determined and evaded by the Robot through the use of deep learning, which can help the Robot to recognize the objects. In general, one way to make the Robot to find the path of operating effectively and to work in the environment effectively is to involve deep learning in this operation. To improve the artificial intelligence of the system, a deep learning algorithm will be of importance.
𝑄ˆ(𝑠, 𝑎) = (1 − 𝛼𝑡). 𝑄ˆ(𝑠, 𝑎) + 𝛼𝑡(𝑟 + 𝛾 max 𝑎 ′ 𝑄ˆ(𝑠 ′ , 𝑎′ ))
Figure portrays the single target fortification learning system. Where the specialist, spoke to by an oval, is in the state (s) at time step (t). The operator plays out the activity-dependent on the Q-esteem. The earth gets this activity, and accordingly, it restores the following states' to the operator and a comparing reward (r) for making a move (a).
Path MAP
Training Result Difference between Learning Rate
Learning Rate = 0.0001, Batch Size = 200
Best Model
Learning Rate = 0.0002, Batch Size = 200
Learning Rate = 0.0003, Batch Size = 200
Learning Rate = 0.0004, Batch Size = 200
In most cases, in a system which is a bit complex, the deep reinforcement learning may not be the best option but, one can decide to go by the deep double q learning which is embedded by Q-matrix which is being advanced to help in finding the paths in very complicated places. Moreover, when the Robot is to be operated in a large environment, it may take time for the deep reinforcement learning to help in getting the correct codes; thus, the use of double Q learning should be an option. It is in this manner recommended that in the next projects, there can be the use of this system to get more harmonized results.
𝑉 𝜋 (𝑠) = 𝐸{ ∑︁∞ 𝑘=0 𝛾 𝑘 𝑟𝑡+𝑘+1|𝑠𝑡 = 𝑠}
As opposed to Q learning, the Double Q learning equation is vectorial functions.
The figure portrays the multi-objective reinforcements support learning structure. Like the single goal RL system, in MORL structure, the operator is spoken to by an oval and is in the state (s) at time step (t). The specialist makes a move dependent on the accessible Q-values. The earth gets this activity, and accordingly, it restores the following state s' to the specialist.
In the early days, there were many concerns about how to proceed with this project. I wanted to study how to find something new rather than simply applying an existing path algorithm to the robot. I also considered a model called GAN, but decided to implement reinforcement learning, realizing that it was impossible to generate as many path images as to train GAN. The biggest problem with implementing reinforcement learning was computing power. Reinforcement learning caused the computer's memory to soar to 100 percent and crash. I tried and ran several options, but to no avail, I decided to reinstall Ubuntu. After the reinstallation, I don't know why, but it's no longer to a computer crash due to a sharp rise in memory. Currently, even with a lot of repetitive learning, it does not exceed 10% of memory.
Another problem with reinforcement learning was the difficulty in adjusting hyperparameters. Since reinforcement learning is a model that is highly influenced by hyperparameters, it was necessary to make fine adjustments to maximize performance. Initially, the code did not include grid search, but added a grid search function to compare hyperparameters. It took about six hours to get around 500 epochs, so I didn't experiment with a huge variety of hyperparameters. However, after three consecutive weeks of training, I found the best performing hyperparameters.
The third problem with reinforcement learning was that the results of learning were not very satisfactory. According to various papers, existing Deep Q Learning can be overestimate because same Q is used. Therefore, although it has not been fully applied to the code yet, I will apply Double Q Learning and Dueling Network in the near future.
In conclusion, it gets imperative to note the issue of path findings in the intelligence machine has been long in existence. Nevertheless, through these methods, the correct paths can be gotten, which is short but can help the Robot in reaching the target.
Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529.
Mnih, Volodymyr, et al. "Playing atari with deep reinforcement learning." arXiv preprint arXiv:1312.5602 (2013). https://arxiv.org/abs/1312.5602
Nuin, Yue Leire Erro, et al. "ROS2Learn: a reinforcement learning framework for ROS 2." arXiv preprint arXiv:1903.06282 (2019). https://arxiv.org/abs/1903.06282
Van Hasselt, Hado, Arthur Guez, and David Silver. "Deep reinforcement learning with double q-learning." Thirtieth AAAI conference on artificial intelligence. 2016. https://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/viewPaper/12389

clone ros drivers:
edit .bashrc:
save bashrc and restart terminal then run:
to test run:
Jacob Smith COSI 119a Fall 2019, Brandeis University
Github Repository: [Arm Interface Project](<https://github.com/campusrover/Robot-Arm-Interface)
Introduction and Relevant literature
The goal of this project was to implement a robotic arm to the campus rover. The scope of the project was planned to go from the high level details of a ROS package and nodes to the low level servo commands to control the motor and everything in between. The final goal of the project was to use the arm in a campus rover application.
Adding an arm not only increases the possible behaviors of the campus rover, but created a framework to integrate any electronic component. In addition, it allowed the testing of the concept of interfacing by seeing if a user not familiar with the arm can control it with ROS.
The author already had a background in Arduino Programming. The main source of information for this project were online tutorials and electronics forums and consultation with Charlie Squires (see Appendix A). For the evaluation of the arm's performance, I two publications on evaluation of robot structures and measuring user experience where consulted [1,2].
The requirements of the project where to interface the ROS based campus rover with a four servo robotic arm and an ultrasonic distance sensor. The servos can each move half a rotation at any speed using the VarSpeedServo library [8], and the ultrasonic sensor returns the distance in inches when requested. Both components are interacted using the Arduino microprocessor attached to the arm. That microprocessor is attached to the Rasberry Pi that is the main computer of the campus rover. The goal of the project was to allow these components to communicate with each other and to integrate into ROS, which is explained next.
Technical descriptions, illustrations
The final project is a comprehensive electronics interacting system that allows the arm, manipulator, and distance sensor to be controlled using ROS framework using abstractions. The interfacing scheme is represented below, and could easily be expanded for other electronics components. The main concept is to separate the command of a component from the low-level instruction, similar to how a user can publishcmd_vel and control a dynamixel motor. The figure below represents the existing commands that can be sent to the arm, utilizing both inputs and outputs.
This report will now explain the components of the project in a top-down order, as a potential user of the arm would view it. These components consist of: the startup scripts, ROS Publisher, ROS Subscriber, Arduino Program, and the hardware being interfaced with.
The startup scripts allow the appropriate ROS nodes to start and allow the arm to be controlled by a ROS Publisher. These are important because they provide information on how to use the arm to someone unfamiliar with Serial and ssh connection issues.
The ROS Publisher publishes to the armcommand topic. The command is formatted in terms of a component tag, along with integers for required parameters. For example, MANIP 1 closes the hand or ARM 0 330 0 20 20 extends the arm at low power. The python node below waves the arm when a face is shown below, and shows how simply the arm can be controlled in ROS.
The Arm Interface Node is run locally on the Rasberry Pi on the robot because it needs to communicate to the Arduino. This node establishes the Serial connection to the Arduino on the arm ( returning an error message of the arm is unplugged and attempting to reconnect). Then, the node subscribes to the armcommand topic. When a command is published to that topic, the callback function of the subscriber sends the command to the Arduino and publishes the feedback from the Arduino to the ArmResponse Topic. The graph of ROS nodes demonstrates the chain of arm interface and response nodes.
Finally, the Arduino Program running on the Arm itself sets up the program to run the motors and distance sensor, establish the serial connection, and parses data coming over the serial connection. This is accomplished by reading the tag and waiting for the correct number of integer arguments. For example, if "ARM" is received, the program loads the next four arguments received into an array and makes a function call to move the arm position. The program to control the manipulator is shown below, note how it hides the actual degree measurements on whether the servo is open or closed and returns an error message if the improper command is specified.
Then, the Arduino commands the motor to move to the specified angle and returns the distance sensor reading (The heartbeat doubles as the distance reading). The arm and associated reverse kinematics program was provided by Charlie Squires (with the author rearranging the microprocessor and battery connection so the arm could be removed from its original mounting and added to the robot).
Next, a survey of interesting problems and techniques is presented. One persistent and surprising problem with the project was the USB connection between the raspberry Pi and the Arduino. Firstly, the USB needs to be unplugged for the arm to be connected properly, and the arm doesn't check which USB port it's plugged in to. These problems could be solved with a voltage regulator and a modification to the arm interface node to check a list of possible usb ports.
An interesting challenge when integrating the arm into the facial recognition project (see below) was when the arm command topic was being published many times a minute, faster than the arm could actually move. This problem doesn't occur with cmd_vel because the motor moves continuously, while the arm's actions are discrete. We solved the problem with a node which only requests to move the arm every few seconds.
In terms of the Arduino program, it uses the simplest form of Charlie Squire's kinematics program, and that could be abstracted into an Arduino library for code clarity. Currently all commands do not stop the execution of the Arduino program, meaning that the program doesn't wait for the arm to finish moving. This allows the components to be redirected on the fly.
Finally, one must consider how the project can be extended to other electronics components, such as a second arm or a package delivery system. In future work, sensors and a ROS action could be implemented to allow for more complicated movements, such as an action to grab a package. That would be implemented by finding the location of a package, and perhaps using a camera to calculate its location. That location could then be passed into coordinates and published to the arm command topic.
Story of the project
I completed this project individually, but benefited from the support of Charlie Squires, both from his original work on the arm and his advice throughout the project. He remounted and fixed the arm, added the ultrasonic sensor, and was a helpful consultant. Late in the project, I also was able to work with Luis and Chris. Chris and I worked quickly on a proof of concept showing how the behavior trees can be used in connection with the arm, and with Luis we where able to prepare our facial recognition-arm demonstration (See videos Appendix A).
Next, the workflow of the project will be discussed, taking a bottom-up approach. First, I wrote an Arduino program to print output over the USB cable, and a python program to read the output from the raspberry pi. Then in version two, I had the Raspberry Pi write to the Arduino, and when the Arduino received a character, it would open and close the manipulator. Next, I improved the Arduino program to open or close the gripper based on whether an 'o' or a 'c' character was sent by the raspberry pi, which also printed output from the Arduino. This is an example of two way communication between the Arduino and the Raspberry pi. Then, I added the ability to move the rest of the servos in the arm.
With the basic infrastructure in place to control, I converted the python program on the Raspberry Pi to the ROS arm interface subscriber and added more error handling. I then wrote a simple ROS node to publish commands to the subscriber. In other words, in the first part of the project I allowed the arm to be controlled from the raspberry Pi, and then I used ROS to allow the arm to be controlled with any ROS node.
The record of the stages of networking the components of this project will prove useful to the student who wishes to learn about the low level details of interfacing (Arduino Library Example V1-V4 and Raspi V1-V4 in 1). Finally, I made the interface general by creating the tagging system of component and arguments (MANIP 0), which can be easily extended to other components, such as the ultrasonic sensor which reports the distance to the ground.
A major goal of the project was to see how useful it is to people not familiar with Arduino who want to contribute to Campus Rover. To that end, I verified the bash scripts with a TA for the class, who was able to get the arm running using my instructions. In addition, Luis was able to control the arm just by publishing the the arm command topic, and not going to a lower level. This integration with the facial recognition project also allowed me to make the program easier to use and port into another project.
Problems that were solved, pivots that had to be taken
The main problem of this project occurred when a piece of hardware didn't perform the way I expected it to. It was easy to get sidetracked with the details of exactly how a servo works compared to the higher level architectural details.
One pivot during this project was the realization that the servos have no ability to report their angle to the user. I investigated the Servo library I am using, VarSpeedSevo to determine the isMoving function could at least return whether the motor was moving, but my testing showed that it couldn't detect this [9]. Plotting the number of times the servo moved by different degrees shows that there is no correlation between where the servo is jammed and what the isMoving function returns. The lack of feedback data made implementing a ROS action less feasible, because an action should be able to know when it is finished. This is an example of the kind of investigation that the next user of the arm interfacing project should hopefully be able to avoid.
Another problem was the mounting of the arm, as the campus rover was not designed to have a place for it. I initially mounted it above the lidar, but we ended up mounting it on top of the robot (see videos in Appendix A). Hopefully the next iteration of campus rover will include a mount for the arm that is stable and doesn't interfere with the lidar.
Assessment
Overall, I believe the project was a success. The robotic arm is now mounted on the campus rover and can be controlled with ROS commands. In addition, the project presents an on overview of related problems and should be a strong foundation for other hardware additions to the campus rover robot.
The next step of the project would be to add rotation sensors to the arm and write a ROS action to control them, but that should be feasible for the next user now that the main layout is in place. Finally, my main intellectual challenge was thinking architecturally, as this is the first time I had to create a generic system that could be used after me.
In conclusion, I wish to thank the COSI 119a TAs, Professor Salas, and Mr. Squires for their support of this project, and I hope future students find my work useful.
Sources
[1]
[2]
[3]
[4] Vemula, Bhanoday. Evaluation of Robot Structures. 2015 https://www.diva-portal.org/smash/get/diva2:859697/FULLTEXT02.pdf Accessed November 19 2019 [5] Tullis Thomas and Albert, William Chapter 5 of Measuring the User Experience, 2nd Edition 2013
[6] My Original Project Proposal
[7] My Revised Project proposal
[9]
[8] (Please see github repository README files for sources)
Videos
Main Project Video
Behavior Tree Integration Video
Facial Recognition Video
s### Hand Gesture Recognition After reaching the dead-end in the previous approach and being inspired by several successful projects (on Github and other personal tech blogs), I implemented an explict-feature-driven hand recognition algorithm. It relies on background extraction to "extract" hands (giving gray scale images), and based on which compute features to recognize the number of fingers. It worked pretty well if the camera and the background are ABSOLUTELY stationary but it isn't the case in our project: as the camera is mounted on the robot and the robot keeps moving (meaning the background keeps changing). Code can be founded
git clone https://github.com/ros-drivers/leap_motion export LEAP_SDK=$LEAP_SDK:$HOME/LeapSDK
export PYTHONPATH=$PYTHONPATH:$HOME/LeapSDK/lib:$HOME/LeapSDK/lib/x64 sudo cp $LeapSDK/lib/x86/libLeap.so /usr/local/lib
sudo ldconfig
catkin_make install --pkg leap_motion sudo leapd
roslaunch leap_motion sensor_sender.launch
rostopic list sudo dpkg -install Leap-*-x64.deb sudo dpkg -install Leap-*-x86.debIt seems that many of the problems we were having resulted from the Turtlebot2 running off of a lot of proprietary software, while the Mutant (based off of a Turtlebot3) is much simpler. Using ROS, we did run into many hiccups and there was a significant amount of troubleshooting involved. A lot of information about the troubleshooting can be found in the lab notebook, on the Mutant page. As ROS is very complicated, without a doubt any future generation will also be faced with a significant amount of troubleshooting. We found the rqt_graph tool to be one of the most helpful -- it allows the user to see which nodes are subscribing/publishing, etc. Much of the time problems stem from this, and being able to see this visually can be very helpful.
We participated in the development of the campus rover similar to Gen 2, where we would brainstorm projects and Pito would lead the adoption by each group of a given project. While everyone was (for the most part) able to complete their projects, we left integration of the different parts (computer vision, hand gestures, navigation) until the last day, which created some difficulties. We highly recommend teams to work on integration throughout the process so that integration is as smooth as possible for the demo at the end of the semester!
In future generations, we recommend further improving the robustness of features that were implemented, such as hand gestures and CV. In addition, part of Gen 3’s goal was to allow the project to run on any Turtlebot. While the code should be able to run on any Turtlebot3, a speaker of some sort would need to be attached for the talk services. These talk services allow the robot to update the user with its progress throughout its use. With these new features, we tried to give direction to further development of the project. We think that these features will guide future generations of the class in development of the campus rover, ultimately leading to a campus rover that will actually be able to deliver packages on campus.
Best of luck,
Gen 3
We, the Gen 2 team, hope in this letter (and in the ancillary documentation contained in the labnotebook repo) to pass on the experience and knowledge we have gathered over the past semester to the Gen 3 team and beyond. We hope that future teams will not only build upon our accomplishments, but also that they will learn from and avoid our mistakes.
We began Campus Rover as a first-come-first-serve brainstorming of projects and possible features of the final Campus Rover product, where students would create teams (1-3 student sized teams for 6 total students) and pick from the list of projects for that current iteration (typically the week from the current class to the next week's meeting). Often, a project would take longer than a single iteration, in which case a team would usually remain on the project for the next iteration.
While this system allowed us to initially take on virtually any project we liked, and gave us a great deal of control over the Campus Rover's final functionality, the protocol gave us expected headaches as we approached the final demo date. By the third or fourth to last iteration (3-4 weeks before the final demo), we were forced as a team to change gears towards combining and debugging the individual projects from our previous iterations. This involved the implementation of states (states.py and all_states.py), controller nodes (rover_controller.py), and other nodes solely for structurally organizational purposes. While these nodes perform satisfactorily for the extent of our Campus Rover (demo and features-wise), they could have put in much more work if implemented chronologically.
In future generations of the Campus Rover, we recommend starting where we finished. With a robust, scaleable node framework, implementing new features would not only be faster and easier, but the nodes will also be able to be implemented with customized standardized guidelines that will gurantee consistency throughout the architecture. For example, with the introduction of states, we had hoped to better organize the robot by its current objective (i.e. navigating, teleoping, etc). However, since many of our existing functionalities were already built, we ran into problems refactoring them to reflect and operate under states.
Implementing high level node control proved its worth again when developing the web application. In order for the application to provide rich feedback including the robot's position, navigation goal, etc, it must be able to access this information. With some exhaustive high-level state and node handling, this information would already be available throughout the architecture, and easily integrated into the web app (see Flask & ROS.md).
For an ideal Gen 3 implementation of Campus Rover, we think that full syncronization and managing of nodes is imperative. Most (if not all) robot functionality should come second to a standardized and organized framework. Consider sorting messages coming from sensors, the web app, and other nodes, so that any subscribing node can easily select and sort through incoming messages. Also, though our implementation was useful to us in the end, a deeper and more easily managed state mechanism would greatly help organization of the robot's features and tasks.
Good luck!
Gen 2

Team: Pito Salas (rpsalas@brandeis.edu) and Charlie Squires (charliesquires@gmail.com)
Date: xxx
Github repo: xxxx `
Use this template as a starting point. You can add sections if you need to by preceding them with the double pound sign,
You can make a numbered list
By doing this
And a bulletted list like
This by putting in asterisks
Write a useful summary for the future
Show off your work
Learn a little bit about markdown
Learn the importance of spelling, grammar and editing
Look at the result in the browser to make sure it looks right
We created a single markdown file explaining our product.
set_arm(100, 200, 90, 0 servoSpeed);
4 coordinates, speed
Type 4 Coordinates
Set Manipulator
MANIP setting
manipulator(true =open/false =code);
open or close
Type Binary Manipulator
Get Distance
Published to Arm Response topic
Automatic
Distance
Type Output Sensor
Set Arm Coordinates
ARM x y base power
Deep reinforcement learning is a family of techniques that utilizes deep neural networks to approximate either a state-action value function (mapping state-action pairs to values) or a state directly to action probabilities (known as policy-gradient methods). In this project, we implemented and tested two Deep RL algorithms. The first is the DDPG agent first proposed by DeepMind [^1]. To help in understanding and implementing this algorithm we also found a very helpful blog post [2] and associated PyTorch implementation of the DDPG agent. The second algorithm implemented was the Soft Actor-Critic agent proposed by Haarnoja et al. from the University of California Berkeley [3]. Again, a blog post was very helpful in understanding the agent and provided a PyTorch implementation [4].
The computer vision components, there was a mixture of GitHub repositories, Open-CV tutorials and a blog post posted on analyticsvidhya, written by Aman Goel. The analyticsvidhya blog post helped me to understand the facial_recognition library in python and how to properly implement it[5]. The GitHub repository that was used as a reference for the proof of concept implementation that was done on Mac OS was written by Adam Geitgey, who is the author of the facial recognition python library[6]. His Github repository along with his README helped me understand how the algorithm works and how to latter modify it within an ROS environment.
There was an assortment of ROS wiki articles used to troubleshoot and understand the errors that were occurring with OpenCV reading the data that was coming from the TurtleBot 3. The wiki articles lead me to the cv_bridege ROS package that can convert a ROS compressed image topic to an OpenCV format[7].
For the driving component of this project, the first step was to create a racetrack to simulate the robot on. To do this, I used Gazebo’s building editor to create a racecourse out of straight wall pieces (there are no default curved pieces in Gazebo). Creating the course (seen in Figure 1) involved saving a .sdf file from gazebo inside the turtlebot3_gazebo/models folder, a .worlds file in turtlebot3_gazebo/world, and a launch file in turtlebot3_gazebo/launch. The initial goal was to train the agent to drive counter-clockwise around the track as fast as possible. To do this, I implemented 5 types of nodes to carry out the different parts of the canonical RL loop (Figure 2) and manually chose 31 points around the track as “checkpoints” to monitor the robot’s progress within a training episode. How close the agent is to the next checkpoint is monitored from timestep to timestep and is used to compute the rewards used to train the agent.
This tracking of the robot’s ground truth position in the track is done by a node called GazeboListener.py which subscribes to Gazebo’s /gazebo/model_states topic. This node also requested reward values from a service called RewardServer.py every 100ms and published them to a topic called /current_reward. These rewards are the critical instructive component of the canonical RL loop as they instruct the agent as to which actions are good or bad in which situations. For this project, the “state” was the average of the past 5 LIDAR scans. This averaging was done in order to smooth out the relatively noisy LIDAR readings. The LIDAR smoothing was implemented by a node called scanAverager.py which subscribed to /scan and published to /averaged_scan.
To choose the actions, I made minor alterations to the PyTorch implementations of the DDPG or SAC agents given by [2,4]. This involved wrapping PyTorch neural network code in class files myRLclasses/models.py and myRLclasses/SACmodels.py. I then wrapped the logic for simulating these agents in the Gazebo track in a ROS node called RLMaster_multistart.py which handled action selection, sending cmd_vel commands, storing experience in the agent’s replay buffer, and resetting the robot’s position when a collision with a wall was detected (end of an episode). These collisions actually proved difficult to detect given the minimum range of the robot’s LIDAR (which is larger than the distance to the edge of the robot). Therefore I said there was a collision if 1) the minimum distance in the LIDAR scan was < .024M, 2) the actual velocity of the robot differed significantly (above a threshold) then the velocity sent to the robot (which in practice happened a lot), and 3) the actual velocity of the robot was less than .05M/s. This combination of criteria, in general, provided relatively robust collision detection and was implemented in a node called CollisionDetector.py.
Having implemented the necessary nodes, I then began training the robot to drive. My initial approach was to have every training episode start at the beginning of the track (having the episode ends when the robot crashed into a wall). However, I found that this caused the robot to overfit this first corner and be unable to learn to make the appropriate turn after this corner. Therefore, I switched to a strategy where the robot would start at a randomly chosen checkpoint for 10 consecutive episodes and then a different randomly chosen checkpoint would be used for the next 10 episodes and so on. This allowed the robot to gain experience with the whole track even if it struggled on particular parts of it. Every timestep, the current “state” (/averaged_scan) was fed into the “actor” network of the DDPG agent which would emit a 2D action (linear velocity and angular velocity). I would then clip the action values to be in the allowable range (-.22 - .22 for linear velocity and -.5 to .5 for angular velocity). Then, noise generated by an Ornstein-Uhlenbeck process would be added to these clipped actions. This added noise provides the exploration for the DDPG model. For the SAC agent, no noise is added to the actions as the SAC agent explicitly is designed to learn a stochastic policy (as opposed to the deep **deterministic **policy gradient). This noisy action would then be sent as cmd_vel commands to the robot. The subsequent timestep, a new state (scan) would be observed and the resulting reward from the prior timestep’s action would be computed. Then the prior scan, the chosen action, the subsequent scan, and the resulting reward would be pushed as an “experience tuple” into the DDPG agent’s memory replay buffer which is implemented as a deque. This replay buffer (stored in myRLclasses/utils.py) holds up to 500,000 such tuples to provide a large body of data for training. At the end of each timestep, a single batch update to all of the agent’s networks would be carried out, usually with a batch_size of 1024 experience tuples. Additionally, every 50 episodes I would do 1000 network updates and then save the agent as a .pkl file.
Finally, I wrote a node to allow a human to control the robot using teleop controls and save the experience in the agent’s replay buffer. This was in the hope that giving the agent experience generated by a human would accelerate the learning process. This was implemented by a node called StoreHumanData.py.
The facial recognition aspect of the RL Racer project took different python techniques and converted and optimized it to work with ROS. There is no launch file for this program. To run this program, you must first have the TurtleBot 3 and have brought up the camera software and have your facial_ recognition as the current directory in terminal. The command to run the code is as follows: $rosrun facial_recognition find_face.py
To do this we had to fundamentally rethink the program structure and methods for it to work. The first thing we had to contend with was the file structure while running the program through ROS, which you can see in figure 4 and figure 5. This was just a little quirk while working with ROS as compared to Python. While running the program you have to be directly in the Facial_recognition folder, anywhere else would result in a “file not found” error while trying to access the images. The Alternative to having to be in the folder for this to work, was to have all the images in the same “scripts” folder, which made for messy “Scripts” and made it confusing while adding new photos.
The steps for adding a photo are as simple as adding to the “face_pcitures” directory as shown figure 6. The image should have a clear view of the face you want the algorithm to recognize. The image does not have to be a giant picture of just a face. After you add an image to the file path you have to package you must call “load_image_file”, which will load the image. The next step is to encode the loaded image and find the face in the image. To do this you must all the “face_encodings” method in the facial_recognition package and pass the image you have loaded as an argument. After the images are added and encoded you add the facial encoding to a list and add the names to a list of names of type String of the people in the list in order. Since Luis is the first face that was added to the prior list, then it will be the first name in the list of names. This is the implementation of the node version of facial recognition that constantly publishes the names of faces that it finds, but there is also a service implementation.
The major difference between the service implementation is the segmentation of the image callback and image processing as you can see in figure 7. We keep track of the frame in a global variable called frame that can be later accessed. We also need the name of the person to be passed and we only process the next 20 frames and if we don’t see the person requested, we will send no. This also is reinforced with a suggested control request implementation.
The color recognition and control node came from a desire to define hazards. There was also a need to still follow other rules while training the neural net and to keep other factors in mind. This uses the basics of OpenCV to create color masks that you can put a specific RGB value you want to pick up. To run the program, you need to run python files in two separate windows. The first command is $ rosrun facial_ recognition racecar_signal.py The second command is: $ rosrun faical_recognition red_light_green_light.py. The racecar_signal node does all the image processing while the red_light_green_light node is a state machine that determines what to send over cmd_vel.
To add color ranges that you want to pick up you have to add the RGB ranges as NumPy arrays as seen in figure 8. After you manually add the RGB range or individual value you want to detect, you must create a find colors object based on the ranges. In this case, the ROS video image comes from the HSV variable. That was set whole converting the ROS Image to an OpenCV format.
The two deep RL algorithms tried were the Deep Deterministic Policy Gradient (DDPG) and Soft Actor-Critic (SAC) agents. The major difference between these methods is that the DDPG is deterministic, that is it outputs a single action every timestep, whereas the SAC agent outputs the parameters of a probability distribution from which an action is drawn. In addition, the DDPG agent is trained simply to maximize reward, whereas the SAC agent also tries to maximize the “entropy” of its policy. Simply, it balances maximizing reward with a predefined amount of exploration. For the first few weeks of the project, I exclusively tried training the DDPG agent by playing around with different hyperparameters such as noise magnitude and batch size as well as tuning the collision detection. I found that the agent was able to make significant progress and at one point completed two full laps of the track. However, after leaving the agent to train overnight, I returned to find that its performance had almost completely deteriorated and was mostly moving backward, clearly a terrible strategy. After doing a little more reading on the DDPG I found that it is an inherently unstable algorithm in that it is not guaranteed to continually improve. This prompted me to look for an alternative deep RL algorithm that was not so brittle. This search led me to the SAC algorithm which was specifically said to be more robust and sample efficient. I again implemented this agent with help from a blog post and started tuning parameters and found that it took longer (almost 3500 episodes) to show any significant learning however it seems to be maintaining its learning better. I am unsure what the problem with my current training method is for the DDPG agent and suspect the problem may just be due to the brittleness of the algorithm. One possible change that could help both agents would be to average over the LIDAR readings (within one scan) to reduce the dimensionality of the input (currently 360 inputs) to the networks which should help reduce learning complexity at the cost of lower spatial resolution. Finally, an interesting behavior produced by both robots was that during straight parts of the course, they learned a strategy of alternating between full left and full right turn instead of no turn at all. It will be interesting to see if this strategy gets worked out over time or is an artifact of the simulation environment
The facial_recognition package comes with a pre-built model that has a 99.38% accuracy rate and built-in methods for facial encoding and facial comparison[8]. The algorithm takes the facial encodings from loaded images that can be manually added a given script and uses landmarks to encode the pictures face. Using OpenCV we take the frames from a given camera, the algorithm finds the faces in the frame, encodes them, then compares the captured data facial encodings. One of the main challenges that I faced while trying to optimize the algorithm further resulted in failure because I could not figure out how to increase the processing time of facial recognition. This was mostly to do with my computer, but there was also a concern of wifi image loss or just slow wifi. Since ROS compressed image is just a published topic published, which relies on wifi. I got around this by manually dropping frames. I tried ROS each way at first limiting the queue and adding sleep functions, but it causes some problems when trying to implement this with other nodes. These methods would just throughout the frames it would still wait within a queue and still have to be processed. To get around these limitations I hardcoded a counter to only take 1 every 6 frames that come in and process it. It is not ideal but it works. The service implementation does something similar as I only want to a total of 24 processed frames, but still following the 1 out of 6 frame method. In total even though I am being sent (6*24) =144, I am only processing 24 frames, but this only occurs when the desired face is not in the frame.
The sign detection of RL racer was supposed to feature real signs detection, but We ran into a problem finding models of American sign or even when we did we could not get it to run. This is why we went the color route and because we could not train a model in time. The control nodes and the color detection nodes all work, but we were never able to implement it into the RL racer because it took longer than expected to train racer. The theory of color detection is that we can mimic signs by using specific RGB values that we want the robot to pick up. So, Green would be Go, Red would be stopped, and Yellow would be a cushion. Obviously, this is to mimic traffic signals.
This project was very interesting and a lot of fun to work on, even though we had to pivot a few times in order to have a finished product. However, we still learned a lot and worked well together always talking, even though we had two distinct parts we wanted to get done in order to come together. Unfortunately, we could not bring everything together that we wanted we still accomplished a lot.
We were disappointed to learn just how unstable the DDPG agent was after initial success but are hopeful that the now operational SAC agent will be able to accomplish the task with more training.
The problem that my facial recognition aspect has is that you have to be within 3 feet for an algorithm to reliably tell who you are or if there is a face on screen. I tried a few things with resizing the image or even try to send uncompressed image topics, but it did not work. An interesting solution that we tried was if we can tell that there was a face there, but now who it was we could take the bounding box of the unknown face, cut it out because we knew where it was on the image, then zoom in. This approach did not work because the image was too low quality.
We both did a good job of accomplishing what we wanted to, even though we had to pivot a few times. We believe that the code we implemented could be used in further projects. The deep RL code could be used to learn to drive around pre-gazeboed maps with some adaptation and the general method could be applied anywhere continuous control is needed. The facial recognition algorithm can be easily added to the code base of Campus Rover for package delivery authentication and any other facial recognition applications.
[1]: Lillicrap et al., 2015. Continuous control with deep reinforcement learning https://arxiv.org/pdf/1509.02971.pdf
[2]: Chris Yoon. Deep Deterministic Policy Gradients Explained. https://towardsdatascience.com/deep-deterministic-policy-gradients-explained-2d94655a9b7b
[3]: Haarnoja et al., 2018. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. https://arxiv.org/abs/1801.01290
[4]: Vaishak V. Kumar. Soft Actor-Critic Demystified. https://towardsdatascience.com/soft-actor-critic-demystified-b8427df61665
[5]: Blog, Guest. “A Simple Introduction to Facial Recognition (with Python Codes).” Analytics Vidhya, May 7, 2019. https://www.analyticsvidhya.com/blog/2018/08/a-simple-introduction-to-facial-recognition-with-python-codes/.
[6]: Geitgey, Adam, Facial Recognition, GitHub Repository https://github.com/ageitgey/face_recognition
[7]: “Wiki.” ros.org. Accessed December 13, 2019. http://wiki.ros.org/cv_bridge/Tutorials/UsingCvBridgeToConvertBetweenROSImagesAndOpenCVImages.
[8]: PyPI. (2019). face_recognition. [online] Available at: https://pypi.org/project/face_recognition/ [Accessed 16 Dec. 2019].
OpenCV
ROS Kinetic (Python 2.7 is required)
A Camera connected to your device
Copy this package into your workspace and run catkin_make.
Simply Run roslaunch gesture_teleop teleop.launch. A window showing real time video from your laptop webcam will be activated. Place your hand into the region of interest (the green box) and your robot will take actions based on the number of fingers you show. 1. Two fingers: Drive forward 2. Three fingers: Turn left 3. Four fingers: Turn right 4. Other: Stop
This package contains two nodes.
detect.py: Recognize the number of fingers from webcam and publish a topic of type String stating the number of fingers. I won't get into details of the hand-gesture recognition algorithm. Basically, it extracts the hand in the region of insteret by background substraction and compute features to recognize the number of fingers.
teleop.py: Subscribe to detect.py and take actions based on the number of fingers seen.
Using Kinect on mutant instead of local webcam.
Furthermore, use depth camera to extract hand to get better quality images
Incorporate Skeleton tracking into this package to better localize hands (I am using region of insterests to localize hands, which is a bit dumb).



while not rospy.is_shutdown():
twist = Twist()
if fingers == '2':
twist.linear.x = 0.6
rospy.loginfo("driving forward")
elif fingers == '3':
twist.angular.z = 1
rospy.loginfo("turning left")
elif fingers =='4':
twist.angular.z = 1
rospy.loginfo("turning right")
else:
rospy.loginfo("stoped")
cmd_vel_pub.publish(twist)
rate.sleep()