Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Team: Chris Choi (mchoi@brandeis.edu), Lucian Fairbrother (lfairbrother@brandeis.edu), Eyal Cohen(eyalcohen@brandeis.edu)
Date: 3rd May 2022
Github repo: https://github.com/campusrover/RoboTag `
We wanted to create a dynamic project involving multiple robots. Since this project would be presented to people with a wide range of robotics knowledge, we wanted to create an intuitive project. We decided to recreate the game of tag using robots as most spectators know the rules, and so that each robot affects the other’s behavior.
The robots have one of two roles, cop and robber. The robbers flee from cops while avoiding obstacles, as the cops are in hot pursuit of them. When a cop is within a certain distance, and the cop catches the robber, their roles switch, and the new robber gets a 10-second head start to run away. If a spectating human feels left out of the fun, they can press a button to take control of their robot and chase the robber as the cop, or chase the cop as the robber.
Currently implemented two robots that can alternate between cop and robber, and user-controlled cop and robber.
COP ALGORITHYM- The cop algorithym was difficult to implement. The question of how to orient a cop towards moving coordinates was difficult for us to wrap our heads around. We first had to understand the pose variables. The pose orientation variable ranges from -3.14 to 3.14 and represents the angles a robot could be in, in radians. We eventually figured out a good compass algorithym, we used an if statement that calculated whether turning left or right was closer to the goal angle and then executed it. We had it go forward if the actual angle was within .2 radians of the goal angle
UDP-SOCKETS- We used UDP-sockets to send info accross our roscores. Because we had two roscores and we needed the robots to communicate their locations to each other we had them send their locations constantly over UDP sockets. We made a sender and receiver for each robot. The sender would subscribe to the AMCL_pose and then send out the message over the socket. The receiver would receive the message decode it, put it into a float64 list and publish it to the robot.
STATE SWITCH- State switching in our game is hugely important, if the robots aren't localized properly and one thinks a tag has happened while the other doesn't they will get caught as the same state. To deal with this we used AMCL to increase the localization and decrease any error. We also set up the tag such that the robber would stop for ten seconds after it became the cop and not be able to tag the new robber during that period. There were a few reasons we did this. Firstly because we wanted the new robber to have a chance to get away before it would get tagged again. Otherwise the two robots could get into an infinite loop of state switching. We also set the distance for the robber tag to be further than the cop to recognize a tag. The robber recognizes a tag at .35 and the cop recognizes it at .3 the reason for this is because the robber stops after recognizing the tag and the cop will keep going until it recognizes the tag. This makes it very unlikely for only one robot to recognize a tag which would result in them getting stuck in the same state.
Every robot needs its own computer to run.
On each computer clone the repository
Go into allinone.py and change one initialized state to robber, such that you have a cop and robber
go into tf_sender.py and change the ip address to the ip address of the other computer
Robo.launch- The main launch file for our project
NODES
Allinone.py - main program node
tf_sender.py - the socket sender node
receiver.py - the socket receiver node
OTHER FILES
Map.yaml
Map.pgm
AMCL
After the ideation period of Robotag, we faced a lot of difficulties and had to make many pivots throughout the project. We spent lots of time on not only development but also designing new methods to overcome obstacles. We had multiple sleepless nights in the lab, and hours-long Zoom meetings to discuss how we design our project. In these talks, we made decisions to move from one stage to another, start over from scratch for modularity, and strategize navigational methods such as move_base, TF, or our ultimate homebrewed algorithms.
First stage: Broadcast/Listener Pair Using TF. We tried to let robots directly communicate with each other by using TF's broadcast/listener method. We initially turned to TF as it is a simple way to implement following between robots. However, this solution was overly-predictable and uninteresting. Solely relying on TF would limit our ability to avoid obstacles in crowded environments.
Second stage: Increase modularity We decided to start over with a new control system with an emphasis on modularity. The new control system called ‘Control Tower’ is a node run on the computer that keeps a record of all robot’s roles and locations, then, orders where each robot has to go. Also, each robot ran the same code, that operates according to given stages. With this system, we would be able to switch roles freely and keep codes simple.
Third stage: move_base Although the Control Tower could properly listen to each robot, publishing commands to each robot was a grueling experience. For optimized maneuvering around a map with obstacles, we decided to use move_base. We successfully implemented this feature on one robot. Given coordinates, a robot could easily utilize move_base to reach that location. We were planning for this to be a cop’s method of tracking down the robber. We SLAMed a map of the second floor of our lab because it was mostly enclosed and has defining features allowing easier localizing. Using this map and AMCL, we could use move_base and move the robot wherever we wanted to. However, when it came time to run move_base on several robots, each robot’s AMCL cost map and move_base algorithm confused the opposing bot. Although in theory, this solution was the most favorable–due to its obstacle avoidance and accurate navigation–in practice, we were unable to figure out how to get move_base to work with multiple robots and needed to give up on AMCL and move_base sooner than we did.
Fourth stage: Using Odom After move_base and AMCL failed us, we used the most primitive method of localization, Odometry. We started each robot from the same exact position and watched as one robot would go roughly in the direction of the other. After a minute, each robot’s idea of the coordinate plane was completely different and it was clear that we could not move forward with using odometry as our method of localization. Due to the limitation of each robot needing to run the program from the same location, and its glaring inaccuracies, we looked elsewhere for our localization needs.
Fifth stage: Better Localization We missed the accuracy of AMCL. AMCL has fantastic localization capabilities combining both lidar and Odom and allows us to place a robot in any location on the map and know its present location, but we didn’t have time to wrestle with conflicting cost maps again, so we elected to run each robot on a separate computer. This would also allow future users to download our code and join the game with their robots as well! Once we had each robot running on its own computer, we created a strategy for robots to communicate between a UDP Socket, such that each one can receive messages about the others’ coordinates. This was an impromptu topic across multiple roscores!
From then on, our localization of each robot was fantastic and allowed us to focus on improving the cops’ tracking and the robber’s running away algorithm while effectively swapping their states according to their coordinate locations in their respective AMCLs.
go into your vnc and run roslaunch robotag robo.launch
Spring 2022 Brendon Lu, Joshua Liu
As old as the field of robotics itself, robot competitions serve as a means of testing and assessing the hardware, software, in-between relationships, and efficiencies of robots. Our group was inspired by previous robot-racing related projects that navigated a robot through a track in an optimal time, as well as the challenge of coordinating multiple robots. Subsequently, our project aims to simulate a NASCAR-style race in order to determine and test the competitive racing capabilities of TurtleBots. Our project’s original objectives were to limit-test the movement capabilities of TurtleBots, implement a system that would allow for the collaboration of multiple robots, and present it in an entertaining and interactive manner. We managed to accomplish most of our goals, having encountered several problems along the way, which are described below. As of the writing of this report, the current iteration of our project resembles a NASCAR time-trial qualifier, in which a TurtleBot moves at varying speed levels depending on user input through a gui controller, which publishes speed data to our ‘driver’ node. For our driver node, we’ve adapted the prrexamples OpenCV algorithm in order to ‘drive’ a TurtleBot along a track, explained below, which works in conjunction with a basic PID controller in order to safely navigate the track.
. .
Below is the general setup of each robot’s “node tree.” These are all running on one roscore; the names of these nodes are different per robot. Green nodes are the ones belonging to the project, whereas blue nodes represent nodes initialized by the Turtlebot. The interconnecting lines are topics depicting publisher/subscriber relationships between different nodes. The “driver” in the robot is the Line Follower node. This is what considers the many variables in the world (the track, pit wall (controller), car status, and more) and turns that into on-track movement. To support this functionality, there are some nodes and functions which help the driver.
This is a function inside the line follower node which we felt was better to inline. Its workings are explained in exhausting detail in the next section. The main bit is that it produces an image with a dot on it. If the dot is on the left, the driver knows the center of the track is on the left.
This node is another subscriber to the camera. It notifies a car whenever it has crossed the finish line. This is accomplished, again, with the masking function of OpenCV. It is very simple but obviously necessary. This also required us to put a bit of tape with a distinct color (green in our case) to use as a finish line.
For a robot to pass another on track, it has to drive around it. The first and final design we are going to use for this involves LiDAR. A robot knows when one is close enough to pass when it sees the scanner of another robot close enough in front of it. It then knows it can go back when it sees the passed robot far enough behind it, and also sees that the track to its side is clear.
The GUI serves as the driver’s controller, allowing the driver to accelerate or decelerate the car, while also showing information about current speed and current heat levels. In combination with the GUI, we also provide the driver with a window showing the Turtlebot’s view from the raspicam, in order to simulate an actual driving experience.
Track construction was made specifically with the game design in mind. The track is made of two circles of tape: blue and tan in an oval-sh configuration. In the qualifying race, the cars drive on the tan line. In the actual race, the cars primarily drive on the blue line, which is faster. Cars will switch to the outer tan track to pass a slower one in the blue line, however. The intent behind some of the track’s odd angles is to create certain areas of the track where passing can be easier or harder. This rewards strategy, timing, and knowledge of the game’s passing mechanics. In qualifying, the tan track has turns that, under the right conditions, can cause the robot to lose track of the line. This is used as a feature in the game, as the players must balance engine power output with staying on track. If a careless player sends the car into the corner too quickly, it will skid off of the track, leaving the car without a qualifying time.
The core of our robot navigation relies on prrexamples’ OpenCV line follower algorithm, which analyzes a compressed image file to detect specific HSV color values, then computes a centroid representing the midpoint of the detected color values. The algorithm first subscribes to the robot’s raspberry pi camera, accepting compressed images over raw images in order to save processing power, then passes the image through the openCV’s bridge function, converting the ROS image to a CV2 image manipulatable by other package functions. In order to further save on process power, we resize the image using cv2.resize(), which changes the resolution of the image, reducing the number of pixels needing to be passed through the masking function. Regarding the resize() function, we recommend using cv2.INTER_AREA in order to shrink the image, and cv2.LINEAR_AREA or cv2.CUBIC_AREA in order to enlarge the image. Note that while using the cv2.CUBIC_AREA interpolation method will result in a higher quality image, it is also computationally more complex. For our project’s purposes, we used the cv2.INTER_AREA interpolation method. The algorithm then accepts a lower and upper bound of HSV color values to filter out of the CV2 image, called ‘masking’. The image then has all of its pixels removed except for the ones which fall within the specified range of color values. Then, a dot is drawn on the “centroid” of the remaining mass of pixels, and the robot attempts to steer towards it. To make the centroid more accurate and useful, the top portion of the image is stripped away before the centroid is drawn. This also means that if the color of surroundings happen to fall within the specified range of color values, the robot won’t take it into account when calculating the centroid (which is desirable).
Modular programming was a critical part of our program to determine which parts of our driver program were computationally intensive. The original line follower node processed the images inside the camera callback function. This arrangement causes the computer to be processed tens of times per second, which is obviously bad. The compression also would process the full size image. We tried remedying this by shrinking the already compressed image down to just 5% of its original size before doing the masking work. Unfortunately, both of these did not appear to have an effect on the problem.
We were able to construct a tkinter gui that interacts with other nodes. We accomplished this by initializing the gui as its own node, then using rostopics to pass user input data between the gui and other nodes.
Executing our project is twofold; first, run roslaunch nascar nascar.launch. Make sure the parameters of the launch file correspond to the name of the TurtleBot. Subsequently, open a separate terminal window and cd into the project folder, then run python tkinter_gui.py.
Our original project was an entirely different concept, and was meant to primarily focus on creating a system that allowed for multi-robot (2-4+) collaboration. We originally intended to create a “synchronized robot dancing” software, which was imagined as a set of 2, 3 or 4 robots performing a series of movements and patterns of varying complexity. Due to the project lacking an end goal and purpose, we decided to shift our focus onto our idea of a NASCAR-style racing game involving two robots. Rather than focusing on designing a system and finding a way to apply it, we instead began with a clear end goal/visualization in mind and worked our way towards it.
While working on our subsequent NASCAR-style multi-robot racing game, two major problems stuck out: one, finding suitable color ranges for the masking algorithm; two, computational complexity when using multiple robots. Regarding the first, we found that our mask color ranges needed to be changed depending heavily on lighting conditions, which changed based on time of day, camera exposure, and other hard-to-control factors. We resolved this by moving our track to a controlled environment, then calibrated our color range by driving the TurtleBot around the track. Whenever the TurtleBot stopped, we passed whatever image the raspicam currently saw through an image editor to determine HSV ranges, then multiplied the values to correspond with openCV’s HSV values (whereas GIMP HSV values range from H: 0-360, S: 0-100, and V: 0-100, openCV’s range from H: 0-180, S: 0-255, and V: 0-255). The cause of our second problem remains unknown, but after some experimentation we’ve narrowed down the cause to relating to computational power and complexity. When running our driver on multiple robots, we noticed conflicting cmd_vels being published resulting from slowdowns in our image processing function, realizing that adding additional robots would exponentially increase the computational load of our algorithm. We attempted to resolve this by running the collection of nodes associated with each robot on different computers, with both sets of nodes associated with the same roscore.
Overall, our group felt that we accomplished some of the goals we originally set for ourselves. Among the original objectives, which were to limit-test the movement capabilities of TurtleBots, implement a system that would allow for the collaboration of multiple robots, and present it in an entertaining and interactive manner, we felt we successfully achieved the first and last goal; in essence, our project was originally conceived as a means of entertainment. However, we were also satisfied with how we approached the second goal, as throughout the process we attempted many ways to construct a working multi-robot collaboration system; in the context of our project, we feel that our overtake algorithm is a suitable contribution to roboticists who would consider racing multiple robots.
Veronika Belkina Robotics Independent Study Fall 2022
Objectives
Document the Interbotix X100 arm and create a program that would send commands to the arm through messages and help explore the capabilities and limitations of the arm.
Create a program that would push a ball towards a target and also to guess if a ball is under a goal and push it out.
The original purpose of this project was to create an arm that could play catch with the user. This would have involved catching a ball that was rolling towards it, and also pushing the ball towards a target.
arm-controlarm-control is a basic command line program that allows the user to send commands to the arm through a ROS message. There are two nodes: send_command.py and arm_control.py. The arm must be turned on, connected to the computer, and the ROS launch files launched.
send_command.py allows for a user to input a command (from a limited pool of commands) such as moving the arm to a point, opening or closing the gripper, moving to the sleep position, etc. There are some basic error checks in place such as whether the command is correct or whether the inputs are the correct type. The user can enter one command at a time and see what happens. The node will then publish the proper message out. There are 8 message types for the various commands to simplify parsing through and figuring out what is happening. When the user decides to exit the program, the sleep message will be sent out to put the arm in the sleep position and exit out of the send_command program.
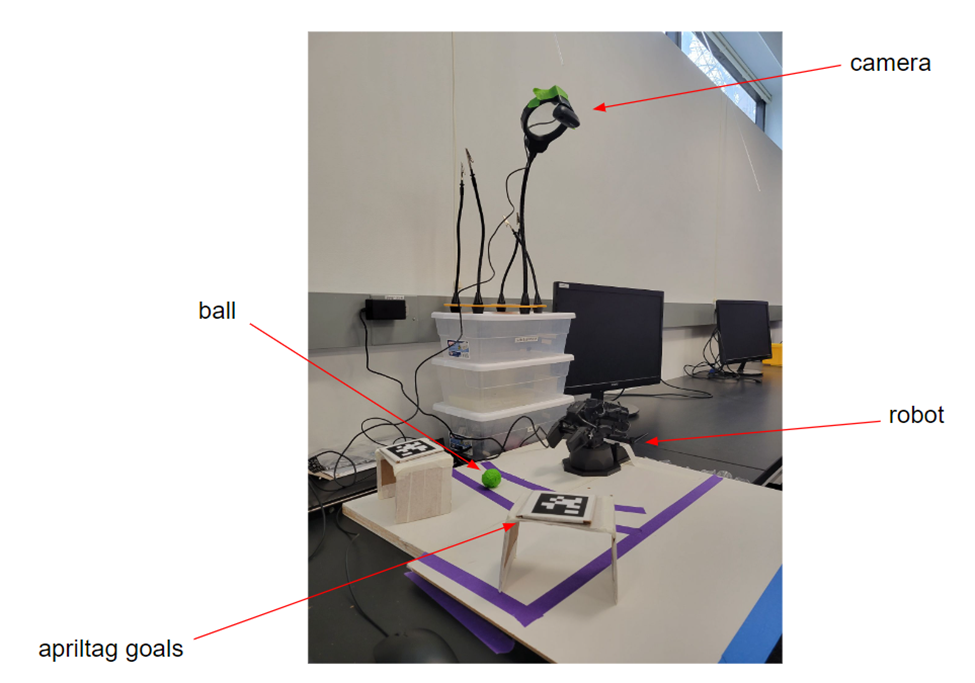
not-play-catchThis is the setup for play-catch. There is a board that is taped off to indicate the boundaries of the camera. The robot is placed in the center of the bottom half and its base-link is treated as the origin (world). There is a ball that is covered in green tape for colour detection, and Apriltags that are placed on top of goals. The camera is situated around 80 cm above the board to get a full view of the board.
Camera and Computer Vision
Camera.py
This node does the main masking and filtering of the images for colour detection. It then publishes a variety of messages out with the various image types after processing. It also allows for dynamic reconfiguration so that it is easier to find the colour that you need.
Ball_distance.py
This node finds the green ball and determines its coordinates on the x-y plane. It publishes those coordinates and publishes an Image message that displays the scene with a box around the ball and the coordinates in centimeters in the corner.
Sending Commands
Pickup.py
The pickup node calculates the position of the ball and picks it up. It first turns to the angle in the direction of the ball and then moves in the x-z direction to pickup the ball. It then turns to the target Apriltag and puts the ball down 15cm away in front of the Apriltag. The calculations for the angles are down in the same way – determining the atan of the y/x coordinates. The steps are all done at trajectory time of 2.0 sec.
Push.py
The push node pushes the ball towards the target. It starts from the sleep position and then turns back to Apriltag target. Since it knows that the ball is already in position, it can push the ball with confidence after closing its gripper. The steps are all done at a trajectory time 0.9 sec to give extra impact to the ball and let it roll.
Guess.py
The guess node is a similar idea to the previous nodes, however, there is some random chance involved. The arm guesses between the two Apriltags, and then tries to push the ball out from under it. If a ball rolls out and is seen by the camera, then the arm will do a celebration dance. If there is no ball, then it will wait for the next turn. For this node, I had to make some adjustments to the way I publish the coordinates of the ball because when the ball wasn’t present, the colour detector was still detecting some colour and saying that there was a ball. So I adjusted the detector to only work when the detected box is greater than 30 pixels, otherwise, the node will publish (0,0,0). Since the ball is (x, y, 0.1) when it is being seen, there shouldn’t be a chance for an error with the ball being at (0,0,0). It would be (0,0,0,1) instead.
Miscellaneous
Main.py
The node that initiates the game with the user and the one that is run in the roslaunch file. From here, the other nodes are run. It also keeps track of the score.
Ball_to_transform.py
This node creates the transform for the ball using the coordinates that are published from ball_distance.py. It uses pose.yaml file to see what the name of the frame is, the parent frame, and the message topic the Pose is being published to.
Guide on how to use the code written
roslaunch arm_control command_center.launch
If you’re working with the actual arm, ensure that it is turned on and plugged into the computer before starting. Otherwise, if you’re working in simulation, then uncomment <arg name=use_sim value=true /> line in the launch file.
Tables
arm_control
not-play-catch
Messages
Other Files/Libraries
The idea for this project started a while ago, during the time when we were selecting what project to do in COSI119. I had wanted to play catch with a robot arm then, however, we ended up deciding on a different project at that time. But the idea still lived on inside me, and when Pito bought the PX100 over the summer, I was really excited to give the project a try.
The beginning was a little unorganized and a little difficult to get familiar with the arm because I had to stay home due to personal reasons for a month. I worked primarily on the computer vision aspects of the project at that time, setting up the Apriltag library and developing the colour detection for the ball and publishing a transform for it.
When I was able to finally return to the lab, it still felt hard to get familiar with the arm’s capabilities and limitations, however, after talking to Pito about it, I ended up developing the arm_control program to send commands and see how the ROS-Python API works more properly. This really helped push the project forward and from there, things felt like they went smoother. I was able to finish developing the pickup and pushing nodes. However, this program also allowed for me to see that the catching part of the project was not really feasible with the way things were. The commands each took several seconds to process, there had to be time between sending messages otherwise they might be missed, and it took two steps to move the arm in the x, y, z directions. It was a bit of a letdown, but not the end of the world.
As an additional part of the project, I was going to do a pick and place node, but it didn’t seem very exciting to be honest. So, I was inspired by the FIFA World Cup to create a game for the robot to play which developed into the guessing game that you see in the video.
This project had a lot of skills that I needed to learn. A big part of it was breaking down the task into smaller more manageable tasks to keep myself motivated and see consistent progress in the project. Since this project was more self-dictated than other projects that I have worked on, it was a challenge to do sometimes, but I’m happy with the results that I have achieved.
As I was writing this report, I had an insight that I felt would have made the program run much faster. It is a little sad that I hadn’t thought of it earlier which is simply to add a queue into the program to act as a buffer that holds commands as they come in. However, I wouldn’t have had to time to implement in a couple of days because it would require to rework the whole structure of the arm_control node. When I thought of the idea, I really didn’t understand how I didn’t think of it earlier, but I suppose that is what happens when you are in the middle of a project and trying to get things to work. Since I had written the arm_control program for testing and discovery and not for efficiency. But then I used it since it was convenient to use, but I didn’t consider that it was not really an optimized program. So next semester, I would like to improve the arm_control program and see if the arm runs the not-play-catch project faster.
Either way, I really enjoyed developing this project and seeing it unfold over time, even if it’s not exactly what I had aspired to do in the beginning. Hopefully, other people will also enjoy creating exciting projects with the arm in the future!
(I didn’t really want to change the name of the project, so I just put a not in front of it…)
Project report for Waiterbot, an automated catering experience
Introduction\
For this project, we wanted to create an automated catering experience. More and more, customer service jobs are being performed by chatbots and voicebots, so why not bring this level of automation to a more physical setting. We figured the perfect domain for this would be social events. Waiter bot serves as a voice activated full-service catering experience. The goal was to create a general purpose waiter robot, where all the robot needs is a map of a catering location, a menu, and coordinates of where to pick-up food and or drinks.
Original Objectives:\
Capable of speech to text transcription and intent understanding.
Has conversational AI.
Can switch between 3 states – Wander, Take_Order, and Execute – to achieve waiter-like behavior.
rosrun arm_control send_command.pyroslaunch playcatch play-catch.launch
Creates a transform for the ball.
camera.py
Does all the masking and filtering and colour detection to make the computer vision work properly.
Bool
Sends the arm to the sleep position
/arm_control/gripper
String
Opens or closes the gripper
/arm_control/exit
Bool
Exits the program and sends the arm to the sleep position
/arm_control/time
Float32
Sets the trajectory time for movement execution
/arm_control/celebrate
Bool
Tells the arm to celebrate!
send_command.py
Receives command line input from user and sends it to arm_control as a message
arm_control.py
Receives command line input from user and sends it to arm_control as a message
main.py
Brings everything together into a game
pickup.py
Locates the ball, determines if it can pick it up, and sends a series of commands to the arm to pick and place the ball in the correct angle for the Apriltag.
push.py
Pushes the ball towards the Apriltag using a series of commands.
guess.py
Guesses a box and pushes the ball out to see if it is there or not. If it is, then it does a celebratory dance. If it’s not, then it will wait for the next round sadly.
ball_distance.py
Calculates the location of the ball on the x-y plane from the camera and publishes a message with an image of the ball with a box around it and the coordinates of the ball.
/arm_control/point
Pose
Pose message which tells the arm where to go
/arm_control/pose
Pose
Pose message which sets the initial pose of the arm
/arm_control/home
Bool
Sends the arm to the home position
apriltag library
A library that allows for users to easily make use of Apriltags and get their transforms.
catch_settings.yaml
Apriltags settings to specify the family of tags and other parameters.
catch_tags.yaml
The yaml file for specifying information about the Apriltags.
pose.yaml
The yaml file for specifying information about the ball.
cvconfig.cfg
The dynamic reconfiguration file for colour detection and dynamically changing the colour that is being detected.
ball_to_transform.py
/arm_control/sleep
Relevant literature:
Core Functionality:
This application was implemented as two primary nodes. One node serves as the user-interface, which is a flask implementation of an Alexa skill. This node is integrated with a ngrok subdomain. This node processes the speech and sends a voice response to Alexa while publishing necessary information for navigation.
We created a custom message type called Order, which consists of three std_msg/String messages. This stores the food for the order, the drink for the order, and the name of the On the backend, a navigation node processes these orders, and looks up the coordinates for where the food and drink items are located. We created a map of the space using SLAM with AMCL. The robot uses this map along with move-base to navigate to its goal and retrieve this item. While Alexa works great for taking orders, one of its flaws is that it cannot be programmed to speak unprompted. When the robot arrives to retrieve the item, the navigation node supplies the alexa-flask node with the item the robot needs.
A worker can ask Alexa what the robot needs, and Alexa tells the worker what is needed. The user then tells Alexa that the robot has the item, and it proceeds to its next stop. Once the robot has collected all of the items, it returns to the location where it originally received the voice request. The navigation node then supplies the alexa-flask node with a message for the order it is delivering. The user can then ask Alexa if that is their order, and Alexa will read back the order to the user. After this, the order is deleted from the node, allowing the robot to take more orders.
Due to the physical size constraints of the robot, it can only carry at most three orders at a time. The benefit of using the flask-ask module, is that the Alexa voice response can take this into account. If the robot has too many orders, it can tell the user to come back later. If the robot is currently in motion, and the user begins to make a user, a String message is sent from the alexa-flask node to the navigation node telling the robot to stop. Once Alexa has finished processing the order, the alexa-node sends another String message to the navigation node telling the robot to continue moving. If the robot has no orders to fulfill, it will roam around, making itself available to users.
In terms of overall behavior, the WaiterBot alternates between wandering around the environment, taking orders and executing the orders. After initialization, it starts wandering around its environment while its order_log remains empty or while it’s not stopped by users. It randomly chooses from a list of coordinates from wander_location_list.py, turns it into a MoveBaseGoal message using the goal_pose() function, and has actionlib’s SimpleActionClient send it using client.send_goal(). And instead of calling client.wait_for_result() to wait till the navigation finishes, we enter a while loop with client.get_result() == None as its condition.
This has 2 benefits – it makes the navigation interruptible by new user order and allows WaiterBot to end its navigation once it’s within a certain tuneable range of its destination. We noticed during our experimentation that while having SimpleActionClient send MoveBaseGoal works really well in gazebo simulation, it always results in WaiterBot hyper-correcting itself continuously when it arrives at its destination. This resulted in long wait times which greatly hampers the efficiency of WaiterBot’s service. Therefore, we set it up so that the robot cancels its MoveBaseGoal using client.cancel_goal() once it is within a certain radius of its goal coordinates.
When a user uses the wake phrase “Alexa, tell WaiterBot (to do something)” in the proximity of the WaiterBot, the robot will interrupt its wandering and record an order. Once the order has been published as an Order message to the /orders topic, the robot will initiate an order_cb function, store the order on an order_log, and start processing the first order. Before it looks up the coordinates of the items, it will store an Odometry message from /odom topic for later use. It then looks at Order message’s data field food and look up its coordinates in loc_string.py. After turning it into a MoveBaseGoal, it uses client to send the goal. Once the Waiterbot arrives at its destination, it will broadcast a message, asking for the specific item it is there to collect. It will not move on to its next destination till it has received a String message from the order_picked_up topic.
After it has collected all items, it uses the Odometry it stored at the beginning of the order and set and send another MoveBaseGoal. Once it returns to its original location, to the user. If order_log is empty, it will being wandering again.
How to Use the Code:
git clone https://github.com/campusrover/waiter_bot.git
cm
Download ngrok and authorize ngrok token pip3 install flask-ask and sudo apt-install ros-noetic-navigation
Have waiterbot skill on an Alexa device
ssh into your robot
roslaunch waiter_bot waiter_bot.launch\
Tables and Descriptions of nodes, files, and external packages:
Story of the Project:\
Our original project intended to have at least two robots, one working as a robot waiter, the other working as a robot kitchen assistant. Initially, we planned to create our NLP system to handle speech and natural language understanding. This quickly became a problem, as we could only find a single dataset that contained food orders and its quality was questionable. At the same time, we attempted to use the Google Speech API to handle out speech-to-text and text-to-speech. We found a ROS package for this integration, but some dependencies were out of data and incompatible. Along with this, the firewalls the lab uses, made integration with this unlikely. We then attempted to use PocketSphinx which is an off-the-shelf automated speech recognition package which can run offline. Initial tests of this showed an incredibly high word-error-rate and sentence-error-rate, so we abandoned this quickly. Previous projects had success integrating Alexa with ROS nodes, so we decided to go in that direction.
Building off of previous work using Flask and ngrok for Alexa integration was fairly simple and straightforward thanks to previous documentation in the lab notebook. Building a custom Alexa skill for our specific purpose was accomplished quickly using the Alexa Developer Console. However, previous methods did not allow a feature that we needed for our project, so we had to find a new approach to working with Alexa.
At first, we tried to change the endpoint for the skill from an ngrok endpoint to a lambda.py provided by Amazon, but this was difficult to integrate with an ROS node. We returned to an approach that the previous projects had used, but this did not allow us to build Alexa responses that involved considering the robots state and asking the user for more information in a way that makes sense. For example, due to the physical size of the robot, it can probably never handle more than three orders. An order consists of a food, a drink, and name to uniquely identify the order. From the Alexa Developer Console, we could prompt the user for this information, then tell the user if the robot already had too many orders to take another one, but this felt like bad user-interface design. We needed a way to let the user know that the robot was too busy before Alexa went through the trouble of getting all this information. Then we found a module called Flask-ASK, which seamlessly integrated flask into the backend of an Alexa Skill. This module is perfect for Alexa ROS integration. On the Alexa Developer Console, all you need to do is define your intents and what phrases activate them. Then within your ROS, you can treat those intents like functions. Within those functions you can define voice responses based on the robot’s current state and also publish messages to other nodes, making the voice integration robust and seamless.
Navigation-wise, we experimented with different ways of utilizing SimpleActionClient class of the actionlib package. As we have mentioned above, we originally used client.wait_for_result() so that WaiterBot can properly finish navigating. wait_for_result(), however, is a black box by itself and prevented us from giving WaiterBot a more nuanced behavior, i.e. capable of interrupting its own navigation. So we looked into the documentation of actionlib and learnt about the get_result() function, which allowed us to tear away the abstraction of wait_for_result() and achieve what we want.
It was surprising (though it should not be) that having a good map also proved to be a challenge. The first problem is creating a usable map using SLAM method of the Gmapping package only, which is not possible with any sizeable area. We searched for software to edit the pgm file directly and settled on GIMP. Having a easy-to-use graphical editor proved to be highly valuable since we are free to tweak any imperfections of a raw SLAM map and modify the image as the basement layout changes.
Another challenge we had concerned the sizes of the maps and how that affect localization and navigation. At one point, we ended up making a map of half the basement since we wanted to incorporate WaiterBot into the demo day itself: WaiterBot would move freely among the guests as people chat and look at other robots and take orders if requested. The large map turned out to be a problem, however, since the majority of the space on the map is featureless. This affects two things: the amcl algorithm and the local map. To localize a robot with a map, AMCL starts with generating a normally distributed initalpose, which is a list of candidate poses. As the robot moves around, AMCL updates the probabilities of these candidate poses based on LaserScan messages and the map, elimating poses whose positions don't align their corresponding predictions. This way, AMCL is able to narrow down the list of poses that WaiterBot might be in and increase the accuracy of its localization. AMCL thus does not work well on a large and empty map since it has few useful features for predicting and deciding which poses are the most likely. We eventually settled down on having a smaller, more controlled map built with blocks.
An issue unique to a waffle model like Mutant is that the four poles interfere with the lidar sensor. We originally tried to subcribe to /scan topic, modify the LaserScan messages, and publish it to a new topic called /scan_mod and have all the nodes which subscribe to /scan such as AMCL to subscribe to /scan_mod instead. This was difficult because of the level of abstraction we had been operating on by roslaunch Turtlebot3_navigation.launch and it was not convenient to track down every node which subscribe to /scan. Instead, we went straight to the source and found a way to modify the LaserScan message itself so that its scan.range_min definition is big enough so that it encompasses the four poles. We learnt that we need to modify the
Self Assessment
Overall, we consider this project a success. Through this project, we were able to integrate conversational AI with a robotic application, learning more about Alexa skill development, mapping, localization, and navigation. While there are a few more things we wish we had time to develop, such as integrating a speaker to allow the robot to talk unprompted, or using a robotic arm to place food and drink items on the robot, this project served as a lesson in properly defining the scope of a project. We learned how to identify moments where we needed to pivot, and rapidly prototyped any new features we would need. In the beginning, we wanted to be evaluated on our performance with regards to integrating an NLP system with a robot, and we more than accomplished that. Our Alexa skill uses complex, multi-turn dialog, and our robotic application shows what may be possible for future automation. This project has been a combination of hardware programming, software engineering, machine-learning, and interaction design, all vital skills to be a proper roboticist.
Team: Peter Zhao (zhaoy17@brandeis.edu) and Veronika Belkina (vbelkina@brandeis.edu)
Date: May 2022
Github repo: https://github.com/campusrover/litter-picker
In waiter_bot/src bash ngrok_launch.sh
Order.msg
A custom message containing three String messages: food, drink and name
ld08_driver.cppnanoLaserScanscan.range_minwaiter_bot_navigation.py
Master node. Has 3 functions Wander, Take_Order and Execute, which serve as states
waiter_bot_alexa_hook.py
Receives speech commands from the user, and sends them to the navigation node
bm.pgm
An image file of the lab basement created using SLAM of the gmapping package
bm.yaml
Contains map information such as origin, threshold, etc. related to bm.pgm
menu_constants.py
contains the food menu and the drink menu
loc_dictionary.py
Contains a dictionary mapping food and drink items to their coordinates
wander_location_list.py
Contains a list of coordinates for the robot’s wandering behavior
Flask-ASK
A Python module simplfying the process of developing the backend for Alexa skills using a Flask endpoint
Ngrok
Creates a custom web address linked to the computer's local IP address for https transfers
The litter picker was born from a wish to help the environment, one piece of trash at a time. We decided on creating a robot that would wander around a specified area and look for trash using a depth camera and computer vision. Once it had located a piece of trash, it would move towards it and then push it towards a designated collection site.
Be able to localize and move to different waypoints within a given area
Capable of recognizing object to determine whether the object is trash
Predict the trash's location using depth camera
Collect the trash and bring to a collection site
In the summary of Nodes, Modules, and External Packages we show the corresponding tables with the names and descriptions of each file. Afterwards, we go into a more detailed description of some of the more important files within the program.
We created a variety of nodes, modules, and used some external packages while trying to determine the best architecture for the litter picker. The following tables (Table 1, 2, 3) show descriptions of the various files that are separated into their respective categories. Table 4 shows the parameters we changed so that the robot moves more slowly and smoothly while navigating using move_base.
Table 1: Description of the ROS Nodes
master.py
Coordinates the various tasks based on the current task's state
vision.py
Processes and publishes computer vision related messages. It subscribes to the bounding box topic, the depth camera, and rgb camera and publishes a Trash custom message that will be used by the Task classes to determine what to do.
Table 2: Description of our python modules used by the above nodes
task.py
Contains the interface which will be implemented by the other classes.
navigation.py
Contains the navigation class, which uses the waypoints state to navigate using the AMCL navigation package and updates the waypoints.
rotation.py
Includes the rotation class that publishes cmd_vel for the robot to rotate and look for trash.
trash_localizer.py
Has the trash localizer class, which publishes cmd_vel to the robot depending on information received from the vision node.
state.py
Holds the current state of the robot that is being passed around between the classes.
Table 3: External packages
darknet_ros
Uses computer vision to produce bounding boxes around the trash.
navigation stack
Navigation stack for navigation and obstacle avoidance.
usb_cam
astra rgb camera driver
Table 4: Parameters changed within the navigation stack file: dwa_local_planner_params_waffle.yaml
max_vel_theta
0.5
min_vel_theta
0.2
yaw_goal_tolerance
0.5
To simplify what information is being published and subscribed to, we created a custom message called Trash which includes three variables. A boolean called has_trash which indicated whether or not there is trash present. A float called err_to_center which returns a number that indicates how far from the center to the bounding_box center is. And a boolean called close_enough which will be true if we believe that the trash is at a reasonable distance to be collected, otherwise it will be false. These are used in the Rotation and Trash_localizer classes to publish the appropriate cmd_vel commands. It is under the message topic litter_picker/vision.
The vision node has several methods and callback functions to process the messages from the various topics it subscribes to and then publish that information as a Trash custom message.
Image 1: Display of the darknet_ros putting a bounded box around the identified object
darknet_ros is the computer vision package that looks for the types of trash specified in the trash_class.py. We want to be able to find things like bottles, cups, forks, and spoons that are lying around. This package integrates darknet with ros for easier use. We then subscribe to the darknet_ros/bounding_boxes topic that it publishes to and use that to to determine where the trash is.
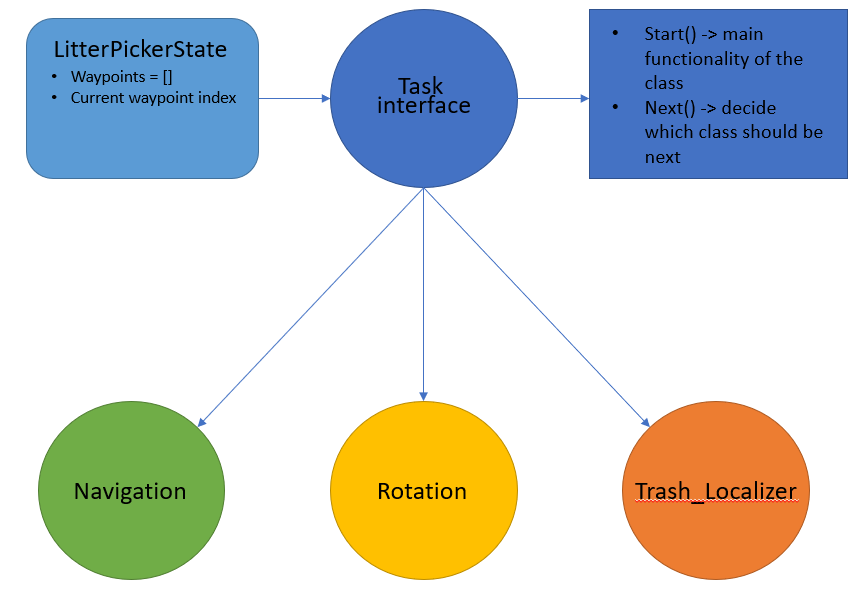
Image 2: A diagram to show the setup of the Task interface and its children classes
The Task interface contains its constructor and two other methods, start() and next(). When a Task instance is initiated, it will take in a state in the form of the LitterPickerState class which contains a list of waypoints and the current waypoint index. The start() method is where the task is performed and the next() method is where the next Task is set. We created three Task children classes called Navigation, Rotation, and TrashLocalizer which implemented the Task interface.
The Navigation class communicates with the navigation stack. In start(), it chooses the current waypoint and sends it to move_base using the move base action server. If the navigation stack returns that it has successfully finished, the has_succeed variable of the Navigation class will be set to true. If the navigation stack returns that it has failed, has_succeed will be set to false. Then when the next() method is called and if has_succeed is true, it will update the waypoint index to the next one and return a Rotation class instance with the updated state. If has_succeed is false, it will return an instance of the Navigation class and attempt to go to the same waypoint again.
The Rotation class publishes a cmd_vel command for a certain amount of time so that the robot will rotate slowly. During this rotation, the camera and darknet_ros are constantly looking for trash. The Rotation class subscribes to the Trash custom message. In the start() method, it looks at the has_trash variable to check if there is any trash present while it is rotating. If there is, then it will stop. In the next() method, it sets has_trash is true, then it will set the next task instance to be the TrashLocalizer task. Otherwise, it will set it to a Navigation task.
The TrashLocalizer class also subscribes to the Trash custom message. In the start() method, it publishes cmd_vel commands to move towards the trash and collect it in the plow. It uses the boolean close_enough to determine how far it has to go before before stopping. Then it sees if it sees that there is still a bounding box, it will use the trap_trash() method to move forward for a specified amount of time.
The master node has a class called LitterPicker which coordinates the Tasks as the robot executes them. There is a constructor, an execute() method, and a main method within it. It also includes the LitterPickerState class which contains a list of all the waypoints and an index for the current waypoint. The constructor takes in a Task and a LitterPickerState and two variables are initialized based on those two: current_task and state.
In the execute() method, there are two lines, as you can see below. The first line starts the execution of the current_task and the second line calls the next function of the current_task so that it can decide which Task should be executed next.
The main function initializes the node, creates an instance of the LitterPickerState using the waypoints file, creates an instance of the LitterPicker class using that state and a NavigationTask class. Then in the while not rospy.is_shutdown loop, it runs the execute() function.
If you wish to change the map file to better suit your location, then you can edit the map file (in <arg name = "map_file"...>) inside the litter_picker.launch, as well as change the initial position of the robot.
You can also edit the new_map_waypoints.txt file in the waypoints folder to match the coordinates that you would like for the robot to patrol around that should be in the following format:
When you ssh onto the robot, you will need to run bringup.
You will also need to run rosrun usb_cam usb_cam_node onboard the robot as well to initialize the depth camera's rgb stream.
Then enter roslaunch litter-picker litter_picker.launch. The program should launch with a few windows: rviz and YOLO camera view.
There were many challenges that we faced with this project, but let’s start from the beginning. At the start, we had tried to divide the work more so that we can create functionality more efficiently. Peter worked on finding a computer vision package that could create and creating the corresponding logic within the rotation node as well as creating the master node and implementing action lib when we had been using it. Veronika worked on creating the map and integrating the navigation stack into the program, installing the depth camera, and using it to localize the trash. Once we created most of the logic and were trying to get things to work, we became masters of pair programming and debugging together and for the rest of the project, we mainly worked together and constantly bounced ideas off each other to try and solve problems.
In the beginning, we had started with a simple state system using the topic publisher and subscriber way of passing information between nodes, however, that quickly became very complicated and we thought we needed a better way to keep track of the current state. We chose to use the actionlib server method which would send goals to nodes and then wait for results. Depending on the results, the master node would send a goal to another node. We also created a map of the area that we wanted to use for our project. Then we incorporated the AMCL navigation system into our state system. We decided that moving from waypoint to waypoint would be the best way to obtain the benefits of AMCL such as path planning and obstacle avoidance. This was a system that we kept throughout the many changes that we underwent throughout the project.
However, when we tested it with the ROS navigation stack, things did not work as expected. The navigation would go out of control as if something was interfering with it. After some testing, we concluded that the most likely cause of this was the actionlib servers, however we were not completely sure why this was happening. Perhaps the waiting for results by the servers was causing some blocking effect to the navigation stack.
We ended up completely changing the architecture of our program. Instead of making each task as a separate node, we made them into python classes where the master node can initiate different actions. The reason for this change is that we felt that the tasks does not have to be running in parallel, so a more linear flow would be more appropriate and resource-efficient. This change greatly simplified our logic and also worked much better with the navigation stack. We also edited some parameters which has been previously described within the navigation stack that allowed for the robot to move more smoothly and slowly.
Initially, we had wanted to train our computer vision model using the TACO dataset. However, there was not enough data and it took too long to train so we ended up choosing the pretrained yolo model that has some object classes such as bottle, cup, fork, and spoon that could be identified as trash. The YOLO algorithm and integrated with ros through the darknet_ros package as mentioned above. We had to make some changes to the darknet_ros files so that it could take in CompressedImage messages.
Close to the beginning of the project, we had set up the Astra depth camera. The story of the depth camera is long and arduous. We had begun the trash_localizer node by attempting to calculate a waypoint that the navigation stack could move to by determining the distance to the identified object and then calculating the angle. From there, we used some basic trigonometry to calculate the amount that needed to be traveled in the x and y directions. However, we found that the angle determined from the depth camera did not correspond with reality and therefore the waypoint calculated was not reliable. The next method we tried was to use the rotation node and stop the rotation when the bounding box was in the center and then use a pid controller to move towards the trash using the distance returned from the depth camera. There were several problems with that such as the bounding box being lost, but in general, this method seemed to work. Since we did most of this testing in Gazebo due to the LiDAR on Alien being broken, we didn't realize that we actually had an even larger problem at hand...
When we started to test the depth camera on the actual robot in a more in depth manner, we realized that it was not returning reliable data with the method that we had chosen. We started to explore other options related to the depth stream but found that we did not have enough time to fully research those functionalities and integrate it in our program. This is when we decided pivot once again and not use the depth part of the depth camera. Instead we used the position of the bounded box in the image to determine whether the object was close enough and then move forward.
There was a robotic arm in the original plan, however, due to the physical limitations of both the arm, the robot, and time constraints, we ended up deciding to use a snow plow system instead. We had several ideas of having a movable one, but they were too small for the objects that we wanted to collect so we created a stationary one out of cardboard and attached it to the front of the robot. It works quite well with holding the trash within its embrace.
Image 3: Alien with the Astra depth camera on top and the plow setup below posing for a photo
This project was much more challenging than we had anticipated. Training our own data and localizing an object based on an image and bounded box turned out to be very difficult. Despite the many problems we encountered along the way, we never gave up and persisted to present something that we could be proud of. We learned many lessons and skills along the way both from the project and from each other. One lesson we learned deeply is that a simulator is very different from the real world. Though for a portion of the time, we could only test simulator due to a missing LiDAR on our robot, it still showed the importance of real world testing to us. We also learned the importance of reasoning through the project structure and logic before actually writing it. Through the many frustrations of debugging, we experienced exciting moments of when something worked properly for the first time and then continued to work properly the second and third times.
In conclusion, we were good teammates who consistently showed up to meetings, communicated with each other, spent many hours working side by side, and did our best to complete the work that we had assigned for ourselves. We are proud of what we have learned and accomplished even if it does not exactly match our original idea for this project.

bool has_trash
float32 err_to_center
bool close_enoughdef execute(self):
self.current_task.start()
self.current_task = self.current_task.next()<include file="$(find litter_picker)/launch/navigation.launch">
<arg name="initial_pose_x" default="-1.1083"/>
<arg name="initial_pose_y" default="-1.6427"/>
<arg name="initial_pose_a" default="-0.6"/>
<arg name="map_file" default="$(find litter_picker)/maps/new_map.yaml"/>
</include>-4.211, 1.945, 0
-4.385, 4.937, 0
-4.38, 4.937, 0
-7.215, 1.342, 0
COSI 119a Fall 2022, Brandeis University
Date: May 4, 2022
If humans can’t enter an area because of unforeseen danger, what could be used instead? We created MiniScouter to combat this problem. The goal of our project was to create a robot that can be used to navigate or “scout” out spaces, with directions coming from the Leap Gesture Controller or voice commands supported by Alexa. The turtlebot robot takes in commands through hand gestures or voice, and interprets them. Once interpreted, the robot preforms the action requested.****
We referred to several documentations for the software used in this project:
We designed and created a voice and gesture controlled tele-operated robot. Voice control utilizes Alexa and Lambda integration, while gesture control is supported with the Leap Motion Controller. Communication between Alexa, the controller, and the robot is all supported by AWS Simple Queue Service integration as well as boto3.
The Leap Motion Controller
The Leap Motion Controller is an optical hand tracking module that captures hand movements and motions. It can track hands and fingers with a 3D interactive zone and identify up to 27 different components in a hand. The controller can be used for desktop based applications (as this project does) or in virtual reality (VR) applications.
The controller use an infrared light based stereoscopic camera. It illuminates the space near it and captures the user’s hands and fingers. The controller then uses a tracking algorithm to estimate the position and orientation of the hand and fingers. The range of detection is about 150° by 120° wide and has a preferred depth of between 10cm and 60cm, but can go up to about 80cm maximum, with the accuracy dropping as the distance from the controller increases.
The Leap Motion Controller maps the position and orientation of the hand and fingers onto a virtual skeletal model. The user can access data on all of the fingers and its bones. Some examples of bone data that can be accessed is shown below.
Alongside hand and finger detection, the Leap Motion Controller can additionally track hand gestures. The Leap Software Development Kit (SDK) offers support for four basic gestures:
Circle: a single finger tracing a circle
Swipe: a long, linear movement of a finger
Key tap: a tapping movement by a finger as if tapping a keyboard key
Screen tap: a tapping movement by the finger as if tapping a vertical computer screen
The controller also offers other data that can be used to manipulate elements:
Grab strength: the strength of a grab hand pose in the range [0..1]
An open hand has a grab strength of zero and a closed hand (fist) has a grab strength of one
Pinch strength: the strength of a pinch pose between the thumb and the closet finger tip as a value in the range [0..1]
As the tip of the thumb approaches the tip of a finger, the pinch strength increases to one
The Leap Motion Controller offers much functionality and a plethora of guides online on how to use it. It’s recommended that the user keep the implementation of an application simple as having too many gestures doing too many things can quickly complicate an algorithm.
Leap Motion Setup
The Leap Motion Controller can be connected to the computer using a USB-A to Micro USB 3.0 cable. After it’s connected, you’ll need to get the UltraLeap hand tracking software, available here. You may need to use older versions of the software since V4 and V5 only offer support and code in C. We found that V2 of the UltraLeap software best fit our needs as it offered Python support and still included a robust hand-tracking algorithm. We installed the necessary software and SDK for V2 from here. Once we had all the necessary hardware and software set-up, we used the UltraLeap Developer documentation for Python at this site to begin creating the algorithm for our project.
To start using the Leap Motion Controller, you’ll need to connect the device to your computer via a USB-A to Micro USB 3.0 cable. You’ll need to install the Leap software from their website at https://developer.leapmotion.com/. We found that we had to install older versions of the tracking software as the latest versions (V4 and V5) only supported C and that the Python version had been deprecated. For our needs, V2 worked best as it offered support for creating Python and came with a robust tracking system. After that, you’ll need to install the Leap SDK, with more details on how to set this up below. (See Setup for more details on how to set up Leap for this project specifically)
A widely known IOT home device, Amazon Alexa is Amazon’s cloud-based voice service, offering natural voice experiences for users as well as an advanced and expansive collection of tools and APIs for developer use.
When a phrase is said to Alexa, it’s first processed through the Alexa service, which uses natural language processing to interpret the users “intent” and then the “skill logic” (as noted down below) handles any further steps once the phrase has been interpreted.
We created an Alexa skill for this project as a bridge between the user and the robot for voice commands. The Alexa skill also utilizes AWS Lambda, a serverless, event-driven computing platform, for it’s intent handling. The Lambda function sends messages to the AWS SQS Queue that we used for Alexa-specific motion commands.
For example, if a user makes a request, saying “Alexa, ask mini scout to move forward”, the Alexa service identifies the user intent as “MoveForward”. Once identified, the lambda function is activated, and it uses a “handler” specific to the command to send a dictionary message to the queue.
AWS Simple Queue Service is a managed message queuing service used to send, store and retrieve multiple messages for large and small scale services as well as distributed systems.
The robot, Alexa, and the Leap motion controller all utilize the AWS Simple Queue Service to pass commands to each other. There are two options when creating queues, a standard queue, and a “FIFO” queue - first in first out, i.e. messages will only be returned in the order they were received. We created two FIFO queues, one for Leap, called “LeapMotionQueue”, and one for Alexa, called “AlexaMotionQueue”.
In the Alexa lambda function and the Leap script, a boto3 client is created for SQS, which is used to connect them to the queue.
On VNC, the robot makes the same connection to SQS, and since all of our work is carried out through one AWS account, it’s able to access the data pushed to both queues upon request.
Boto3 is the latest version of the AWS SDK for python. This SDK allows users to integrate AWS functionalities and products into their applications, libraries and scripts. As mentioned above, we used Boto3 to create a SQS ‘client’, or connection, so that our Leap script and our Alexa skill could access the queues.
Initially, we planned on having the Leap Motion Controller plugged directly into the robot, but after some lengthy troubleshooting, it was revealed that the Raspberry Pi the robot uses would not be able to handle the Leap motion software. Instead of giving up on using Leap, we thought of other ways that would allow communication between our controller and the robot.
At the suggestion of a TA (thanks August!) to look into AWS, we looked for an AWS service that might be able to support this type of communication. The Simple Queue Service was up to the task - it allowed our controller to send information, and allowed the robot to interpret it directly. (Deeper dive into this issue in the Problems/Pivots section)
One of the first and most important design choices we had to consider on this project was which gestures we should use to complete certain actions. We had to make sure to use gestures that were different enough so that the Leap Motion Controller would not have difficulty distinguishing between two gestures, as well as finding gestures that could encompass all the actions we wanted to complete. We eventually settled on the following gestures that were all individual enough to be identified separately:
Hand pitch forward (low pitch): move backward
Hand pitch backward (high pitch): move forward
Clockwise circle with fingertip: turn right
Counter-clockwise circle with fingertip: turn left
Grab strength 1 (hand is a fist): stop all movement
Another aspect we had to take into consideration when creating the algorithm was how much to tune the values we used to detect the gestures. For example, with the gesture to move forward and backward, we had to decide on a pitch value that was not so sensitive that other gestures would trigger the robot to move forward/backward but sensitive enough that the algorithm would know to move the robot forward/backwards. We ran the algorithm many times with a variety of different values to determine which would result in the greatest accuracy across all gestures. Even with these considerations, the algorithm sometimes was still not the most accurate, with the robot receiving the wrong command from time to time.
We implemented this algorithm on the local side. Within the code, we created a Leap Motion Listener object to listen to commands from the Leap Motion Controller. The Leap Listener takes in data such as number of hands, hand position in an x, y, z plane, hand direction, grab strength, etc. This data is then used to calculate what gestures are being made. This information then makes a request to the queue, pushing a message that looks like the following when invoked:
On the VNC side, the motion is received from the SQS queue and turned back into a dictionary from a string. The VNC makes use of a dictionary to map motions to a vector containing the linear x velocity and angular z velocity for twist. For example, if the motion is “Move forward,” the vector would be [1,0] to indicate a linear x velocity of 1 and an angular z velocity of 0. A command is published to cmd_vel to move the robot. The current time ensures that all of the messages are received by the queue as messages with the same data cannot be received more than once.
For the Alexa skill, many factors had to be considered. We wanted to implement it in the simplest way possible, so after some troubleshooting with Lambda we decided on using the source-code editor available in the Alexa developer portal.
In terms of implementing the skill, we had to consider the best way handle intents and slots that would not complicate the way messages are sent to the queue. We settled on giving each motion an intent, which were the following:
MoveForward
MoveBackward
RotateLeft
RotateRight
Stop
In order for these ‘intents’ to work with our robot, we also had to add what the user might say so that the Alexa service could properly understand the intent the user had. This meant adding in several different “utterances”, as well as variations of those utterances to ensure that the user would be understood. This was very important because each of our intents had similar utterances. MoveForward had “move forward”, MoveBackward has “move backwards”, and if the Alexa natural language processor only has a few utterances to learn from it could easily confuse the results meant for one intent for a different intent.
Once the intent was received, the Lambda function gets to work. Each handler is a class of it’s own. This means that if the intent the Alexa service derives is “RotateRight”, it invokes only the “RotateRightHandler” class. This class makes a request to the queue, pushing a message that looks like the following when invoked.
Once this reaches VNC, the ‘intent_name’ - which would be a string like ‘MoveForward’ - is interpreted by converting the string into a dictionary, just like the Leap messages. We had to add the current time as well, because when queue messages are identical they are grouped together, making it difficult to pop them off the queue when the newest one arrives. If a user requested the robot to turn right twice, the second turn right message would not make it to the queue in the same way as the first one since those message are identical. Adding the time makes each message to the queue unique - ensuring it reaches the robot without issue.
The way that motions would be handled from two different sources in VNC was a huge challenge at one point during this project. Once we decided we’d incorporation voice control into our robots motion, it was clear that switching back and forth between leap commands and voice commands would be an issue. At first, we thought we’d try simultaneous switching between the two, but that quickly proved to be difficult due to the rate in which messages are deleted from each queue. It was hard to ensure that each command would used while reading from both of the queues, as messages could arrive at the same time. So we made the executive decision that voice commands take priority over Leap commands.
This means that when an Alexa motion is pushed onto the queue, if the script that’s running on VNC is currently listening to the Leap queue, it will pause the robot and proceed to listen to commands from the Alexa queue until it receives a stop command from Alexa.
This simplified our algorithm, allowing for the use of conditionals and calls to the SQS class we set up to determine which queue was to be listened to.
On the VNC, there are 3 classes in use that help the main function operate.
MiniScoutAlexaTeleop
MiniScoutLeapTeleop
SQS_Connection
The MiniScoutMain file handles checking each queue for messages and uses conditionals to determine which queue is to be listened to as well as making calls to the two teleop classes for twist motion calculation.
The SQS_Connection class handles queue connection, and has a few methods that assist the main class with it. The method has_queue_message() returns whether the requested queue has a message or not. This method makes a request to the selected queue, asking for the attribute ApproximateNumberOfMessages . This was the only way we could verify how many messages were present in the queue, but it proved to be a challenge as this request only returns the approximate number of messages in the queue. At any time during the request could the number change. This meant that we had to set a couple of time delays in the main script as well as checking the queue more than once to accomodate for this possibility. The method get_sqs_message() makes a request to the queue for a message, but only is called in the main function if has_queue_message() returns True . This helps insure that the request does not error out and end our scripts execution.
The MiniScoutAlexaTeleop class handles incoming messages from the Alexa queue and converts them into twist messages based on the intent received in the dictionary that are then published to cmd_vel once returned.
The MiniScoutLeapTeleop class takes the dictionary that is received from the SQS queue. It makes use of this dictionary to map motions to a vector containing the linear x velocity and angular z velocity for twist, and then returns it.
Clone the Mini Scout repository (Be sure to switch to the correct branch based on your system)
Install the Leap Motion Tracking SDK
Note: Software installation is only needed on one 'local' device. If your laptop runs on MacOS, clone the MacOS branch and follow the MacOS instructions. If your laptop runs on Windows, clone the Windows branch and follow the Windows instructions
Mac (V2):
Windows (Orion, SDK included):
Mac OS Installation
Note: The MacOS software does not currently work with macOS Monterey, but there is a hack included below that does allow it to work
Once installed, open the Leap Motion application to ensure correct installation.
A window will pop up with controller settings, and make sure the leap motion icon is present at the top of your screen.
Note: If your MacOS software is an older version than Monterey, skip this step. Your visualizer should display the controller’s cameras on it’s own.
Restart your computer, leaving your Leap controller plugged in. Do not quit the Leap Application. (so it will open once computer is restarted)
Once restarted, the computer will try to configure your controller. After that is complete, the cameras and any identifiable hand movement you make over the controller should appear.
Windows Installation
Note: the Leap Motion Controller V2 is not compatible with a certain update of Windows 10 so you’ll have to use the Orion version of the Leap software
With V2, you can go into Program Files and either replace some of the .exe files or manually change some of the .exe files with a Hex editor
However, this method still caused some problems on Windows (Visualizer could see hands but code could not detect any hand data) so it is recommended that Orion is used
AWS Setup
Create a AWS Account (if you have one already, skip this step)
Create an SQS Queue in AWS
Adding your credentials to the project package
In your code editor, open the cloned gesture bot package
navigate to the “credentials” folder
Running the script
Before running this script, please make sure you have Python2.7 installed and ready for use
navigate to the ‘scripts' folder and run ‘python2.7 hello_robot_comp.py'
Using the Alexa Skill
This step is a bit more difficult.
Go to the Alexa Developer Console
Using MiniScout in ROS
Clone the branch entitled vnc into your ROS environment
install boto3 using similar steps as the ones above
running hello robot!
run the hello_robot_comp.py script on your computer
run the hello_robot_vnc.py script on your robot
When we first started our project, we had the idea of creating a seeing-eye dog robot that would guide the user past obstacles. We decided we wanted to use the Leap Motion Controller in our project and we planned to have the user direct the robot where to go using Leap. We would then have the robot detect obstacles around it and be able to localize itself within a map. Our final project has definitely deviated a lot from our original project. At the beginning, we made our project more vague to just become a “gesture-controlled bot” since we felt that our project was taking a different direction than the seeing-eye dog bot we had planned on. After implementing features for the robot to be commanded to different positions through hand gestures and voice commands, we settled on creating a mini scouter robot that can “scout” ahead and help the user detect obstacles or dangerous objects around it.
Our first main challenge with the Leap Motion Controller was figuring out how to get it connected. We first attempted to connect the controller directly to the robot via USB. However, the computer on the turtlebot3 ended up not being strong enough to handle Leap, so we had to consider other methods. August recommended using AWS IOT and we began looking into AWS applications we could use to connect between the local computer and VNC. We settled on using AWS SQS to send messages from the local computer to the VNC and the robot and we used boto3 to add SQS to our scripts.
Our next challenge was with getting the Leap Motion Controller setup. The software we needed for Leap ended up not being compatible with Monterey (the OS Nazari’s laptop was on) and it didn’t seem to work when attempting to set it up on Windows (Helen’s laptop). For Mac, we found a workaround (listed above under setup) to get V2 of the Leap software working. For Windows, we had to try a couple different versions before we found one that worked (Orion).
There were also challenges in finding the best way to represent the gestures within the algorithm for moving the robot. Our gestures were not clear at times and having the robot constantly detect gestures was difficult. We had to make changes to our code so that the robot would see a gesture and be able to follow that command until it saw another gesture. This way, Leap would only have to pick up on gestures every few seconds or so - rather than every second - making the commands more accurate.
When we started implementing a voice control system into the robot, we had challenges with finding a system that wasn’t too complex but worked well with our needs. We first explored the possibility of using pocketsphinx package but this ended up not being the most accurate. We decided to use Amazon Alexa and AWS lambda to implement voice recognition.
Overall, we are very satisfied with the progress on this project. It was quite tricky at times, but working with AWS and finding a new way for the controller to communicate with the robot was an unexpected “pivot” we took that worked out well in the long run. The entire project was truly a learning experience, and it’s exciting to watch our little Mini Scouter move as it uses the code we created over the last three months.
utils.py
Provides some helper functions for the rest of the modules.
topics.py
A single place to store all the subscribed topics name as constants
trash_class
Contain the yolo classes that are considered trash
sqs_message = {
"Current Time":current_time.strftime("%H:%M:%S"),
"Motion Input": "Leap",
"Motion": motion
}sqs_message = {
"Motion Input": "Alexa",
"Intent": intent_name,
"Current Time":current_time.strftime("%H:%M:%S")
}MacOS
path on computer/mini_scouter
│
├── Alexa
│ ├── VoiceControlAlexaSkill.zip
│ ├── VoiceControlAlexaSkill
│ ├── interactionModels
│ ├── custom / en-US.json
│ ├── lambda
│ ├── Credentials.py
│ ├── lambda_function.py
│ ├── requirements.txt
│ ├── utils.py
│ └── skill.json
│ └── intents.txt
├── src
│ ├── credentials
│ ├── __init__.py
│ └── Add_Credentials.py
│ ├── MacOSLeap
│ ├── Leap.py
│ ├── LeapPython.so
│ └── libLeap.dylib
├── hello_robot_comp.py
├── LeapGestureToSQS.py
└── .gitignore
Windows
path on computer/mini_scouter
│
├── Alexa
│ ├── VoiceControlAlexaSkill.zip
│ ├── AlexaSkillUnzipped
│ ├── interactionModels
│ ├── custom / en-US.json
│ ├── lambda
│ ├── Credentials.py
│ ├── lambda_function.py
│ ├── requirements.txt
│ ├── utils.py
│ └── skill.json
│ └── intents.txt
├── src
│ ├── credentials
│ ├── __init__.py
│ └── Credentials.py
│ ├── WindowsLeap
│ ├── Leap.py
│ ├── LeapPython.so
│ └── libLeap.dylib
├── LeapGestureToSQS.py
└── .gitignore
vnc
catkin_ws/src/mini_scout_vnc
│
├── src
│ ├── credentials
│ └── Credentials.py
│ ├── hello_robot
│ └── src
│ ├── Credentials.py
│ └── hello_robot_vnc.py
│ ├── sqs
│ └── sqs_connection.py
│ ├── teleop
│ ├── MiniScoutAlexaTeleop.py
│ └── MiniScoutLeapTeleop.py
│ └── MiniScoutMain.py
├── CMakeLists.txt
├── README.md
├── package.xml
└── .gitignorePlug your leap motion controller into your controller via a USB port.
From the icon dropdown menu, select visualizer.
The window below should appear.
Orion is slightly worse than V2 at detecting hand motions (based off of comparing the accuracy of hand detection through the visualizer
Orion is fairly simple to set up; once you install the file, you just run through the installation steps after opening the installation file
Make sure to check off “Install SDK” when running through the installation steps
After the installation is completed, open “UltraLeap Tracking Visualizer” on your computer to open the visualizer and make sure the Leap Motion Controller is connected
The window below should look like this when holding your hands over the Leap Motion Controller:
Search for “Simple Queue Service”
Click “Create Queue”
Give your queue a name, and select ‘FIFO’ as the type.
Change “Content-based deduplication” so that its on. There is no need to change any of the other settings under “Configuration”
Click “Create Queue”. No further settings need to be changed for now.
This is the type of queue you will use for passing messages between your robot, the leap controller, alexa and any additional features you decide to incorporate from the project.
Creating your Access Policy
Click “Edit”
Under “Access Policy”, select advanced, and then select “Policy Generator”
This will take you to the AWS Policy Generator. The Access Policy you create will give your Leap software, Alexa Skill and robot access to the queue.
Add your account ID number, which can be found under your username back on the SQS page, and your queue ARN, which can also be found on the SQS page.
Select “Add Statement”, and then “Generate Policy” at the bottom. Copy this and paste it into the Access Policy box in your queue (should be in editing mode).
Repeat step 1-5 once more, naming the queue separately for Alexa.
Create an AWS access Key (Start at “Managing access keys (console)”)
https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_access-keys.html
Save the details of your AWS access key somewhere safe.
Installing AWS CLI, boto3
Follow the steps at the link below:
https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html
Once completed, downgrade your pip version with:
sudo easy_install pip==20.3.4
(this is needed since the LEAP portion of the project can only run on python2.7)
Run the following commands
pip install boto3
pip freeze
Your “OWNER_ID” can be found in the top right hand corner of your aws console
“lmq_name” is the name of your queue + “.fifo”
i.e. leapmotionqueue.fifo
change the name of Add_Credentials.py to Credentials.py
You will need to do this step with each credentials file in each package
IMPORTANT
UNDER NO CONDITION should this file be uploaded to github or anywhere else online, so after making your changes, run nano .git/info/exclude and add Credentials.py
Please make sure that it is excluded by running git status and then making sure it’s listed under Untracked files
If everything is installed correctly you should see some output from the controller!
to run the teleop script, run ‘LeapGestureToSQS.py’ while your controller is plugged in and set up!
Click “Create Skill”
Give your skill a name. Select Custom Skill. Select ‘Alexa-Hosted Python’ for the host.
Once that builds, go to the ‘Code’ tab on the skill. Select ‘Import Code’, and import the “VoiceControlAlexaSkill.zip” file from the repository, under the folder “Alexa”
Import all files.
In Credentials.py, fill in your credentials, ensuring you have the correct name for your queue.
“vcq_name” is the name of your queue + “.fifo”
Click ‘Deploy’
Once Finished, navigate to the ‘Build’ tab. Open the intents.txt file from the repository’s ‘Skill’ folder (under the Alexa folder), and it’s time to build our intents.
Under invocation, give your skill a name. This is what you will say to activate it. We recommend mini scout! Be sure to save!
Under intents, click ‘Add Intent’ and create the following 5 intents:
Move
MoveForward
MoveBackward
RotateLeft
RotateRight
Edit each intent so that they have the same or similar “Utterances” as seen in the intents.txt file. Don’t forget to save!
Your skill should be good to go! Test it in the Test tab with some of the commands, like “ask mini scout to move right”
catkin_makegive execution permission to the file MiniScoutMain.py
change each Add_Credentials.py file so that your AWS credentials are correct, and change the name of each file to Credentials.py


check that boto3 is actually there!
python -m pip install --user boto3