Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Solving a maze is an interesting sub-task for developing real-world path schedule solutions on robots. Typically, developers prefer to use depth sensors such as lidar or depth camera to walk around in a maze, as there a lots of obstacle walls that the robot need to follow and avoid crashing. Depth sensors have their advantage to directly provide the distance data, which naturally supports the robot to navigate against the obstacles.
However, we have come up with another idea to solve the maze using the computer vision approach. By reading articles of previous experts working on this area, we know that the RGB image cameras (CMOS or CCD) could also be used to get the depth information when they have multiple frames captured at different points of view at the same time, as long as we have the knowledge of the relative position where the frames are taken. This is basically the intuition of how human eyes work and developers have made a lot of attempts on this approach.
Though it could calculate the depth data by using cameras no less than 2, it is not as accurate as directly using the depth sensors to measure the environment. Also, the depth calculation and 3D reconstruction requires a lot of computational resource with multiple frames to be processed at the same time. Our hardware resource might not be able to support a real-time response for this computation. So we decide not to use multiple cameras or calculate the depth, but to extract features from a single image that allows the robot to recognize the obstacles.
The feature extraction from a single frame also requires several image processing steps. The features we chose to track are the lines in the image frames, as when the robot is in a maze boundary lines will could be detected as because walls and the floor could have different colors. We find the lines detected from the frames, which slopes are in certain ranges, are exactly the boundaries between the floor and walls. As a result, we tried serval approaches to extract these lines as the most important feature in the navigation and worked on optimization to let the robot perform more reliable.
We also implemented several other algorithms to support the robot get out of the maze, including a pid controller. They will be introduced later.
To detect the proper lines stably, we used some traditional algorithms in the world of computer vision to process the frames step by step, including:
Gaussian blur to smooth the image, providing more chance to detect the correct lines. https://web.njit.edu/~akansu/PAPERS/Haddad-AkansuFastGaussianBinomialFiltersIEEE-TSP-March1991.pdf https://en.wikipedia.org/wiki/Gaussian_blur
converting image from RGB color space to HSV color space https://en.wikipedia.org/wiki/HSL_and_HSV
convert the hsv image to gray and then binary image
We also implemented a pid controller for navigation. Here are some information about the pid controller: https://en.wikipedia.org/wiki/PID_controller
The general idea has already been described in the above sections. In this section we will talk about the detail structure and implementation of the code.
Some of the algorithms we are using to detect the lines have implementations in the OpenCV library. For the Gaussian, HSV conversion, gray and binary conversion, Canny edge detection and Hough line detection, OpenCV provides packaged functions to easily call and use. At beginning of the project, we just simply tried these functions around in the gazebo simulation environment, with a single script running to try to detect the edge from the scene, which are the boundaries between the floor and the walls.
When the lines could be stably detected, we tested and adjusted in the real world. After it works properly, we tidy the code and make it a node called the line detector server. It subscribe the image from the robot's camera and always keeping to process the frames into the lines. It publishes the result as a topic where other nodes can subscribe to know about the information of the environment such as whether there is a wall or not. (As in some cases even there is a line at side, there could be no wall, we also check several pixels at the outer side of the line to determine whether there is truly a wall or not)
e.g. left line with left wall (white brick indicates a wall):
e.g. left line with no left wall (black brick indicates a floor):
Then, we considered about the maze configuration and determined that a maze can have 7 different kinds of possible turns, that are:
crossroad
T-road where the robot comes from the bottom of the 'T'
T-road where the robot comes from the left
We then decided that it is necessary to hard code the solution of these cases and make it an action node to let the robot turn properly as soon as one of such situation is detected. The reason of using the hard-coded solution in a turn is because when the robot walks close to the wall, the light condition will change so sharply that it could not detect the edges correctly. So we let the robot to recognize the type of the turn accurately before it enter and then move forward and/or turn for some pre-defined distances and degrees to pass this turn.
In order to solve the problem that the pi camera's view of angle is too small, we let robot to stop before enter a turn and turn in place to look left and right for some extra angles so that it will have broad enough view to determine the situation correctly.
e.g. left line detected correctly
e.g. fail to detect the left line, not enough view
e.g. turn a bit to fix the problem
e.g. no right line, turn and no detection, correct
This node is called corner handle action server. When the main node detects that there is a wall (line) in the front which is so near that the robot is about to enter a turn, it will send request to this corner handler to determine the case and drive over the turn.
In order to finally get out the maze, the robot also need a navigation algorithm, which is a part of the corner handler. We chose an easy approach which is the left-wall-follower. The robot will just simply turn left whenever it is possible, or go forward as the secondary choice, or turn right as the third choice, or turn 180 degrees backwards as the last choice. In this logic, the above 7 turn cases can be simplified into these 4 cases. For example, when the robot find there is a way to the left, it does not need to consider the right or front anymore and just simply turn left. When the actions (forward and turning) has been determined, the corner handle action server will send request to another two action servers to actually execute the forward and turning behaviors.
So the general idea is: when the robot detects a turn in the maze by analyzing the lines, its main node will call an action to handle the case and wait until the robot has passed that turn. In other time, the robot will use the pid algorithm to try to keep at the middle of the left and right walls in the maze, going forward until reaches the next turn. We have wrote the pid controller into a service node that the main node will send its request to calculate the robot's angular twist when the robot is not handling turns, the error is calculated by the different of intercept of left line on x = 0 and right line on x = w (w is the width of the frame image).
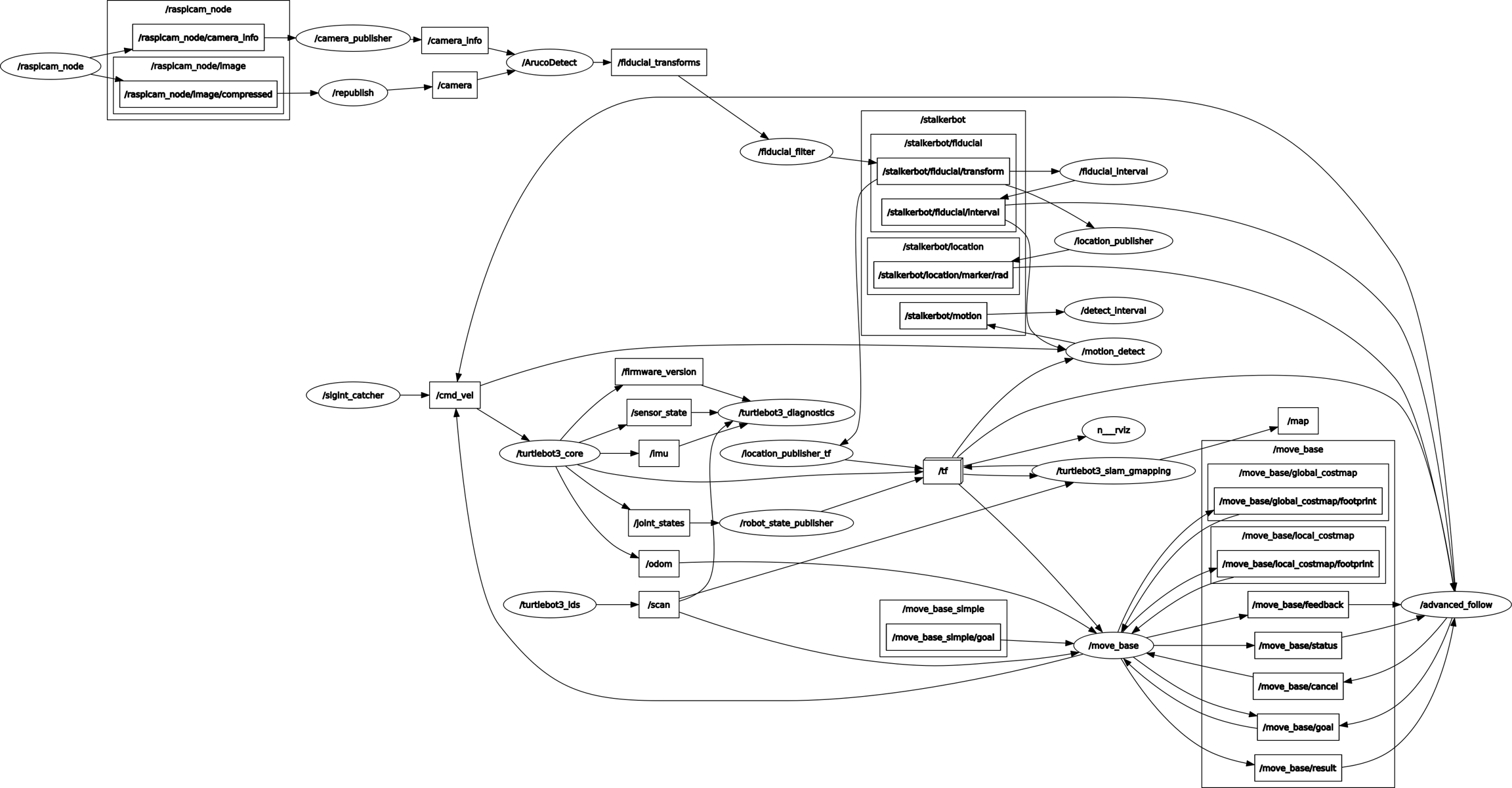
In conclusion, we have this node relationship diagram
Then the workflow of our whole picture is pretty straightforward. The below flowchart describes it:
In this section, we briefly talk about some details of the algorithms we use.
The Process of Canny edge detection algorithm can be broken down to 5 different steps:
Apply Gaussian filter to smooth the image in order to remove the noise
Find the intensity gradients of the image
Apply non-maximum suppression to get rid of spurious response to edge detection
The simplest case of Hough transform is detecting straight lines, which is what we use. In general, the straight line y = mx + b can be represented as a point (b, m) in the parameter space. However, vertical lines pose a problem. They would give rise to unbounded values of the slope parameter m. Thus, for computational reasons, Duda and Hart proposed the use of the Hesse normal form
where r is the distance from the origin to the closest point on the straight line, and θ is the angle between the x axis and the line connecting the origin with that closest point.
It is therefore possible to associate with each line of the image a pair ( r , θ ).The ( r , θ ) plane is sometimes referred to as Hough space for the set of straight lines in two dimensions. This representation makes the Hough transform conceptually very close to the two-dimensional Radon transform. (They can be seen as different ways of looking at the same transform.)
Given a single point in the plane, then the set of all straight lines going through that point corresponds to a sinusoidal curve in the (r,θ) plane, which is unique to that point. A set of two or more points that form a straight line will produce sinusoids which cross at the (r,θ) for that line. Thus, the problem of detecting collinear points can be converted to the problem of finding concurrent curves.
After use the Hough line algorithm to find a set of straight lines in the frame. we use a slope filter to find a single line which slope is in a particular range and is also closest to a particular reference value. For the front line, we always use the one at most bottom of the frame, which means it is the closest wall.
Pid controller stands for a proportional, integral and derivative controller, which out put is them sum of these three terms, with each of them times a constant factor.
In our pid implementation, the raw input of the error is the term that will times the proportional factor. The integral term is calculated by the sum of the content of a error history deque, which keeps the latest 10 error history values and sum their product with the time gap between each other (graphically the area of a trapezoid). The derivative term is calculated by the difference of the current error and the last error, divided by the difference of their time gap.
As above mentioned, our project is strongly relied on the accuracy of edge detection. At the beginning, we only apply Gaussian filter to remove the noise in the image then just apply double threshold to determine edges. However, it does not work well. Then we try to convert the denoised image to a hsv image and convert this hsv image into a binary image before applying canny function. Unfortunately, it does not work every time. Sometimes because of the light and shadow issue it cannot detect the desired edges. Finally, we changed our binary image generation method by considering 3 features, hue, saturation and value, rather than only one feature hue, which turns out works much more robust.
The algorithm to make robot walk straight without hitting the wall is also necessary. At the beginning we applied the traditional wall following algorithm, single side wall following. It only worked on some simple occasions and easily went wrong. What making this single side following algorithm worse is taking turns. Because we use the camera as our only sensor and when taking turns it might lose wall due to the perspective change. Therefore, it is hard to extend the single-side-wall-following algorithm to an all situation handle algorithm. Then we come up with an idea to detect both sides wall. To maintain the robot drives at the middle of road, we got both sides boundaries between ground and wall and maintain those 2 lines intersecting the edges of image at the same height. Another benefit from this algorithm is that the more lines we detected, the more information we get, then the more accurate reflection of surroundings.
Third view: https://drive.google.com/file/d/1lwV-g8Pd23ECZXnbm_3yocLtlppVsSnT/view?usp=sharing First view on screen: https://drive.google.com/file/d/1TGCNDxP1frjd9xORnvTLTU84wuU0UyWo/view?usp=sharing
do Canny edge detection on the binary image http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.420.3300&rep=rep1&type=pdf https://en.wikipedia.org/wiki/Canny_edge_detector
do Hough line detection on the edges result http://www.ai.sri.com/pubs/files/tn036-duda71.pdf https://en.wikipedia.org/wiki/Hough_transform
apply an slope filter on the lines to reliably find the boundary of the walls and the floor
left turn
right turn
dead end
Track edge by hysteresis: Finalize the detection of edges by suppressing all the other edges that are weak and not connected to strong edges.
The campus rover behavior tree project was conceived of as a potential avenue of exploration for campus rover’s planning framework. Behavior trees are a relatively new development in robotics, having been adapted from non-player character AI in the video game industry around 2012. They offer an alternative to finite state machine control that is both straightforward and highly extensible, utilizing a parent-child hierarchy of actions and control nodes to perform complex actions. The base control nodes - sequence, selector, and parallel - are used to dictate the overarching logic and runtime order of action nodes and other behavior subtrees. Because of their modular nature, behavior trees can be both combined and procedurally generated, even used as evolving species for genetic algorithms, as documented by Collendachise, Ogren, and others. Numerous graphical user interfaces make behavior trees yet more accessible to the practicing technician, evidenced by the many behavior tree assets available to game designers now as well as more recent attempts such as CoSTAR used for robotics. My aim for this project, then, was to implement these trees to be fully integrable with Python and ROS, discover the most user-friendly way to interact with them for future generations of campus rover, and integrate my library with the current campus rover codebase by communicating with move_base and sequencing navigation while, optimistically, replacing its finite state machine structure with predefined trees.
For the most part, I was successful in accomplishing these goals, and the final result can be found at https://github.com/chris8736/robot_behavior_trees. This repository contains a working behavior tree codebase written entirely in Python with ROS integration, including all main control nodes, some decorator nodes, and simple processes to create new action and condition nodes. Secondly, I was able to implement a unique command parser to interpret command strings to autonomously generate behavior trees designed to run. This command parser was later used to read a sequence of plain English statements from a text file, providing a means for anyone to construct a specific behavior tree with no knowledge of code. Thirdly, I was able to merge my project seamlessly with the robot arm interface project and the campus rover navigation stack to easily perform sequenced and parallel actions.
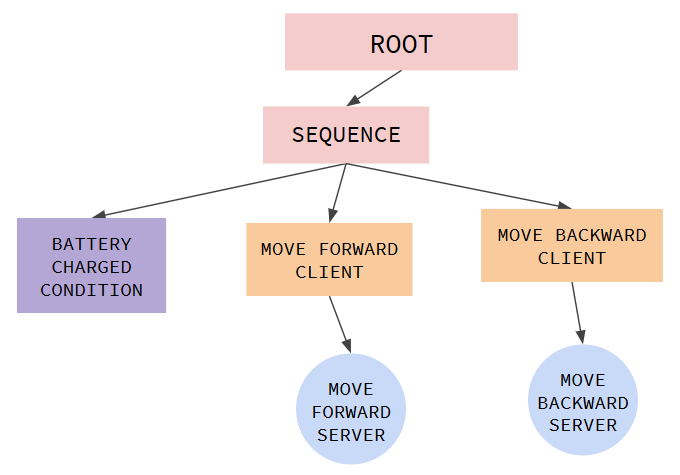
The codebase is inspired by the organization of the C++ ROS-Behavior-Trees package, found here: https://github.com/miccol/ROS-Behavior-Tree. Though powerful, I found this package somewhat unsupportive of new Python nodes, requiring obscure changes to catkin’s CMakeLists text file after every new action node or tree declaration. Despite this, I found the package’s overall organization neat and its philosophy of implementing behavior tree action nodes as ROS action servers sensible, so I attempted to adopt them. Rather than have singular action nodes, I implement auxillary client nodes that call pre-instantiated action servers that may in the future accept unique goals and provide feedback messages. For now, these action servers simply execute methods that may publish ROS topics, such as moving forward for two seconds, twisting 90 degrees clockwise, or just printing to console. This modified structure is shown below, in a program that moves forward and backward if battery is sufficient:
Control nodes - e.g. sequence, parallel, and selector nodes - are normal Python classes not represented by ROS nodes. I connect these classes and client nodes via parent-child relationships, such that success is implicitly propagated up the tree, and resets naturally propagate down. With these node files alone, behavior trees can be explicitly defined and run in a separate Python file through manually setting children to parent nodes.
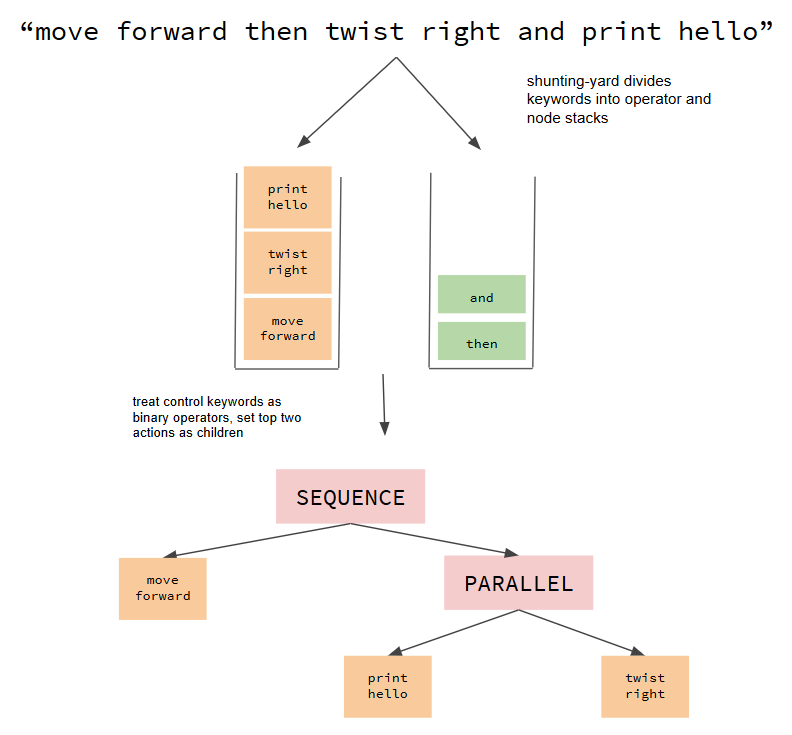
My command parsing script simply reads in strings from console or lines in a text file and interprets them as instructions for constructing a novel behavior tree. It utilizes the shunting-yard algorithm along with a dictionary of keywords to parse complex and potentially infinitely long commands, giving the illusion of natural language processing. Shunting-yard splits keywords recognized in the input string into a stack of values and a stack of operators, in this case allowing logic keywords such as “and” to access its surrounding phrases and set them as children of a control node. In addition to storing keys of phrases, the dictionary also holds references to important classes required to build the tree, such as condition nodes and action servers. The below figure shows example execution for the command “move forward then twist right and print hello” (note: one action represents both the client and server nodes):
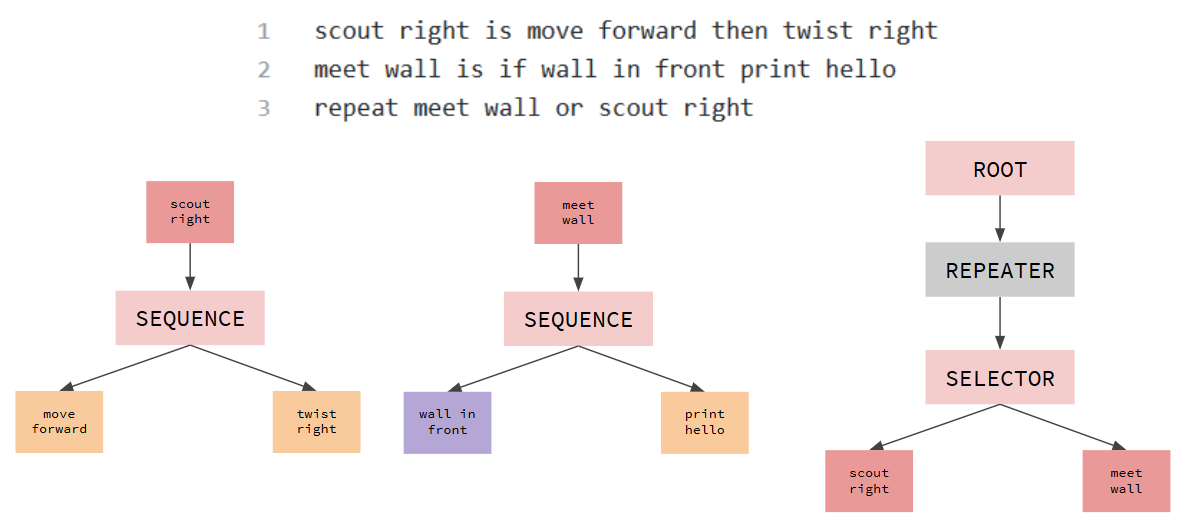
On its own, this approach has its limitations, namely that all the trees it creates will be strictly binary and right-heavy. I was able to solve the latter problem while implementing file parsing through the keyword “is”, allowing keywords to reference entire subtrees through commands such as:
More complex behaviors can thus be built from the bottom up, allowing for multiple levels of abstraction. Conciseness and good documentation allow this codebase to be highly modular. By inheriting from general Action and Condition node classes, making an external process an action or condition requires only a few extra lines of code, while incorporating it into the command parser requires only a dictionary assignment. This ease of use allowed me to very quickly implement action nodes referencing move_base to navigate campus rover towards landmarks, as well as actions publishing to the robot arm interface to make it perform sequenced gestures.
I began this project by searching online for behavior tree libraries I could use to further my understanding of and expedite my work. Within this week of searching, I settled on ROS-Behavior-Trees, utilized by Collendachise in the above literature. Though I succeeded at running the example code and writing up new Python action nodes, I had great difficulty attaching those new nodes to the library’s control nodes, written entirely in C++. After a particularly inefficient week, I decided to switch gears and move on to my own implementation, referencing the C++ library’s architecture and the literature’s pseudocode to set up my main nodes. Though successful, I found writing up a whole python file to represent a behavior tree while having to remember which parent-child relationships I had already set exceedingly inconvienient.
As the third generation of campus rover was not yet stable by this time, I decided the best use of my remaining time was to make the use of my code more intuitive, leading me to the command parser. I had used the shunting-yard algorithm in the past to parse numerical expressions, and was curious to see if it would work for lexical ones as well. Though it was challenging to hook up each of my servers to a unique key phrase while importing across directories, I eventually made something workable without any major roadblocks.
When I was finally able to get campus rover running on my machine, I had only a few weeks left to understand its code structure, map which topics I was to publish to, and rewrite existing action functionality with parameterized arguments if I wanted to do a meaningful integration. Though I worked hard to identify where navigation requests were sent and found success in having getting a robot find its way to the lab door, AMCL proved to be unreliable over many trials, and I struggled to figure out how to write new action goals to make even a surface level integration work with all landmarks. With the hope of making behavior trees easier to understand and access for future developers, I instead used the remaining time to refine my command parser, allowing it to read from file with all the functionality I mention above.
All things considered, I feel I have satisfied nearly all the initial goals I could have realistically hoped to accomplish. I made my own behavior tree library from scratch with no previous knowledge of the topic, and I find my codebase both very easy and enjoyable to work with. Though I was unable to work with campus rover for the majority of the final project session, I proved that integrating my codebase with outside projects through ROS could be done incredibly quickly. Finally, I was able to make progress in what I believe to be an unexplored problem - interpreting human commands to generate plans robots can use in the future.
https://ieeexplore.ieee.org/abstract/document/6907656
https://ieeexplore.ieee.org/abstract/document/7790863
https://ieeexplore.ieee.org/abstract/document/8319483
https://ieeexplore.ieee.org/abstract/document/7989070
As said before, we need a reliable way to extract hands. The first approach I tried was to extract hands by colors: we can wear gloves with striking colors (green, blue and etc) and desired hand regions can be obtained by doing color filtering. This approach sometimes worked fine but easily got distracted by subtle changes in lighting at most of the time. In a word, it was not robust enough. After speaking to Prof. Hong, I realized this approached had been tried by hundreds of people decades ago and will never work. Code can be found here.
r = x cos θ + y sin θAs a very last minute and spontaneous approach, we decided to use a Leap Motion device. Leap Motion uses an Orion SDK, two IR camerad and three infared LEDs. This is able to generate a roughly hemispherical area where the motions are tracked.
It has a smaller observation area dn higher resolution of the device that differentiates the product from using a Kinect (which is more of whole body tracking in a large space). This localized apparatus makes it easier to just look for a hand and track those movements.
The set up is relatively simple and just involved downloading for the appropriate OS. In this case, Linux (x86 for a 32 bit Ubuntu system).
download the SDK from ; you can extract this package and you will find two DEB files that can be installed on Ubuntu.
Open Terminal on the extracted location and install the DEB file using the following command (for 64-bit PCs):
If you are installing it on a 32-bit PC, you can use the following command:
Once having Leap Motion installed, we were able to simulate it on RViz. We decided to program our own motion controls based on angular and linear parameters (looking at directional and normal vectors that leap motion senses):
This is what the Leap Motion sees (the raw info):
In the second image above, the x y and z parameters indicate where the leap motion detects a hand (pictured in the first photo)
This is how the hand gestures looked relative to the robot's motion:
So, we got the Leap Motion to successfully work and are able to have the robot follow our two designated motion. We could have done many more if we had discovered this solution earlier. One important thing to note is that at this moment we are not able to mount the Leap Motion onto the physical robot as LeapMotion is not supported by the Raspberry Pi (amd64). If we are able to obtain an Atomic Pi, this project should be able to be furthered explored. Leap Motion is a very powerful and accurate piece of technology that was much easier to work with than the Kinect, but I advise still exploring both options.
clone ros drivers:
edit .bashrc:
save bashrc and restart terminal then run:
to test run:
As a very last minute and spontaneous approach, we decided to use a Leap Motion device. Leap Motion uses an Orion SDK, two IR camerad and three infared LEDs. This is able to generate a roughly hemispherical area where the motions are tracked.
It has a smaller observation area dn higher resolution of the device that differentiates the product from using a Kinect (which is more of whole body tracking in a large space). This localized apparatus makes it easier to just look for a hand and track those movements.
The set up is relatively simple and just involved downloading for the appropriate OS. In this case, Linux (x86 for a 32 bit Ubuntu system).
download the SDK from https://www.leapmotion.com/setup/linux; you can extract this package and you will find two DEB files that can be installed on Ubuntu.
Open Terminal on the extracted location and install the DEB file using the following command (for 64-bit PCs):
$ sudo dpkg -install Leap-*-x64.deb
If you are installing it on a 32-bit PC, you can use the following command:
Once having Leap Motion installed, we were able to simulate it on RViz. We decided to program our own motion controls based on angular and linear parameters (looking at directional and normal vectors that leap motion senses):
This is what the Leap Motion sees (the raw info):
In the second image above, the x y and z parameters indicate where the leap motion detects a hand (pictured in the first photo)
This is how the hand gestures looked relative to the robot's motion:
So, we got the Leap Motion to successfully work and are able to have the robot follow our two designated motion. We could have done many more if we had discovered this solution earlier. One important thing to note is that at this moment we are not able to mount the Leap Motion onto the physical robot as LeapMotion is not supported by the Raspberry Pi (amd64). If we are able to obtain an Atomic Pi, this project should be able to be furthered explored. Leap Motion is a very powerful and accurate piece of technology that was much easier to work with than the Kinect, but I advise still exploring both options.
https://github.com/campusrover/gesture_recognition
Intro
In Kinect.md, the previous generations dicussed the prospects and limitations of using a Kinect camera. We attempted to use the new Kinect camera v2, which was released in 2014.
Thus, we used the libfreenect2 package to download all the appropiate files to get the raw image output on our Windows. The following link includes instructions on how to install it all properly onto a Linux OS.
https://github.com/OpenKinect/libfreenect2
We ran into a lot of issues whilst trying to install the drivers, and it took about two weeks to even get the libfreenect2 drivers to work. The driver is able to support RGB image transfer, IR and depth image transfer, and registration of RGB and depth images. Here were some essential steps in debugging, and recommendations if you have the ideal hardware set up:
Even though it says optional, I say download OpenCL, under the "Other" option to correspond to Ubuntu 18.04+
If your PC has a Nvidia GPU, even better, I think that's the main reason I got libfreenect to work on my laptop as I had a GPU that was powerful enough to support depth processing (which was one of the main issues)
Be sure to install CUDA for your Nvidia GPU
Please look through this for common errors:
https://github.com/OpenKinect/libfreenect2/wiki/Troubleshooting
Although we got libfreenect2 to work and got the classifier model to locally work, we were unable to connect the two together. What this meant is that although we could use already saved PNGs that we found via a Kaggle database (that our pre-trained model used) and have the ML model process those gestures, we could not get the live, raw input of depth images from the kinect camera. We kept running into errors, especially an import error that could not read the freenect module. I think it is a solvable bug if there was time to explore it, so I also believe it should continued to be looked at.
However, also fair warning that it is difficult to mount on the campus rover, so I would just be aware of all the drawbacks with the kinect before choosing that as the primary hardware.
https://www.kaggle.com/gti-upm/leapgestrecog/data
https://github.com/filipefborba/HandRecognition/blob/master/project3/project3.ipynb
What this model predicts: Predicted Thumb Down Predicted Palm (H), Predicted L, Predicted Fist (H), Predicted Fist (V), Predicted Thumbs up, Predicted Index, Predicted OK, Predicted Palm (V), Predicted C
As a very last minute and spontaneous approach, we decided to use a Leap Motion device. Leap Motion uses an Orion SDK, two IR camerad and three infared LEDs. This is able to generate a roughly hemispherical area where the motions are tracked.
It has a smaller observation area dn higher resolution of the device that differentiates the product from using a Kinect (which is more of whole body tracking in a large space). This localized apparatus makes it easier to just look for a hand and track those movements.
The set up is relatively simple and just involved downloading for the appropriate OS. In this case, Linux (x86 for a 32 bit Ubuntu system).
download the SDK from https://www.leapmotion.com/setup/linux; you can extract this package and you will find two DEB files that can be installed on Ubuntu.
Open Terminal on the extracted location and install the DEB file using the following command (for 64-bit PCs):
$ sudo dpkg -install Leap-*-x64.deb
If you are installing it on a 32-bit PC, you can use the following command:
Once having Leap Motion installed, we were able to simulate it on RViz. We decided to program our own motion controls based on angular and linear parameters (looking at directional and normal vectors that leap motion senses):
This is what the Leap Motion sees (the raw info):
In the second image above, the x y and z parameters indicate where the leap motion detects a hand (pictured in the first photo)
This is how the hand gestures looked relative to the robot's motion:
So, we got the Leap Motion to successfully work and are able to have the robot follow our two designated motion. We could have done many more if we had discovered this solution earlier. One important thing to note is that at this moment we are not able to mount the Leap Motion onto the physical robot as LeapMotion is not supported by the Raspberry Pi (amd64). If we are able to obtain an Atomic Pi, this project should be able to be furthered explored. Leap Motion is a very powerful and accurate piece of technology that was much easier to work with than the Kinect, but I advise still exploring both options.
s### Hand Gesture Recognition After reaching the dead-end in the previous approach and being inspired by several successful projects (on Github and other personal tech blogs), I implemented an explict-feature-driven hand recognition algorithm. It relies on background extraction to "extract" hands (giving gray scale images), and based on which compute features to recognize the number of fingers. It worked pretty well if the camera and the background are ABSOLUTELY stationary but it isn't the case in our project: as the camera is mounted on the robot and the robot keeps moving (meaning the background keeps changing). Code can be founded
git clone https://github.com/ros-drivers/leap_motion export LEAP_SDK=$LEAP_SDK:$HOME/LeapSDK
export PYTHONPATH=$PYTHONPATH:$HOME/LeapSDK/lib:$HOME/LeapSDK/lib/x64 sudo cp $LeapSDK/lib/x86/libLeap.so /usr/local/lib
sudo ldconfig
catkin_make install --pkg leap_motion sudo leapd
roslaunch leap_motion sensor_sender.launch
rostopic list sudo dpkg -install Leap-*-x64.deb sudo dpkg -install Leap-*-x86.debplug in leap motion and type dmesg in terminal to see if it is detected
clone ros drivers:
$ git clone https://github.com/ros-drivers/leap_motion
edit .bashrc:
export LEAP_SDK=$LEAP_SDK:$HOME/LeapSDK
export PYTHONPATH=$PYTHONPATH:$HOME/LeapSDK/lib:$HOME/LeapSDK/lib/x64
save bashrc and restart terminal then run:
sudo cp $LeapSDK/lib/x86/libLeap.so /usr/local/lib
sudo ldconfig
catkin_make install --pkg leap_motion
to test run:
sudo leapd
roslaunch leap_motion sensor_sender.launch
rostopic list

















Install OpenNI2 if possible
Make sure you build in the right location
plug in leap motion and type dmesg in terminal to see if it is detected
clone ros drivers:
$ git clone https://github.com/ros-drivers/leap_motion
edit .bashrc:
export LEAP_SDK=$LEAP_SDK:$HOME/LeapSDK
export PYTHONPATH=$PYTHONPATH:$HOME/LeapSDK/lib:$HOME/LeapSDK/lib/x64
save bashrc and restart terminal then run:
sudo cp $LeapSDK/lib/x86/libLeap.so /usr/local/lib
sudo ldconfig
catkin_make install --pkg leap_motion
to test run:
sudo leapd
roslaunch leap_motion sensor_sender.launch
rostopic list
OpenCV
ROS Kinetic (Python 2.7 is required)
A Camera connected to your device
Copy this package into your workspace and run catkin_make.
Simply Run roslaunch gesture_teleop teleop.launch. A window showing real time video from your laptop webcam will be activated. Place your hand into the region of interest (the green box) and your robot will take actions based on the number of fingers you show. 1. Two fingers: Drive forward 2. Three fingers: Turn left 3. Four fingers: Turn right 4. Other: Stop
This package contains two nodes.
detect.py: Recognize the number of fingers from webcam and publish a topic of type String stating the number of fingers. I won't get into details of the hand-gesture recognition algorithm. Basically, it extracts the hand in the region of insteret by background substraction and compute features to recognize the number of fingers.
teleop.py: Subscribe to detect.py and take actions based on the number of fingers seen.
Using Kinect on mutant instead of local webcam.
Furthermore, use depth camera to extract hand to get better quality images
Incorporate Skeleton tracking into this package to better localize hands (I am using region of insterests to localize hands, which is a bit dumb).
Object avoidance is of the upmost importance for autonomous robotics applications. From autonomous vehicles to distribution center robots, the ability to avoid collisions is essentially to any successful robotics system. Our inspiration for this project came from the idea that the current Campus Rover significantly lacks semantic scene understanding. One type of scenes of particular concern are those that pose immediate danger to the robot. A possible scenarios is the campus rover is delivering a package and is moving along the hallway. The floor is wet and the robot is unable to understand the meaning of the yellow wet floor sign. The robot’s navigation system avoids the wet floor sign, but the radius of the water spill is greater than the width of the wet floor sign, and the robot’s wheels hit the water puddle. There is a staircase adjacent to this spill and when the robot’s wheels make contact with water, it spirals sideways, crashing down the stairs, breaking several of its components and the contents of the package. Our aim in this project is to provide a way for robots to avoid these scenarios through recognition of the trademark wet floor signs. The following report will go as follows. In section II, we will dive into relevant literature concerning our problem. Following that, we will detail our process and the difficulties we faced. Finally, in Section IV, we will provide a reflection of how our project went.
The use of deep convolutional neural networks has enjoyed unprecedented success over the past decade in applications everywhere from facial recognition to autonomous navigation in vehicles. Thus, it seemed appropriate for our project that such techniques would be optimal. We decided our best methodology for allowing a robot to ‘understand’ a wet floor sign was to train a deep convolutional neural network on images of a yellow wet floor sign. Upon further research of this problem statement and methodology, we discovered a research paper from ETH Zurich that seemed to best fit our needs. The paper, written in 2018, details how ETH Zurich’s Autonomous Formula One Racing Team computes the 3D pose of the traffic cones lining the track. Although we only have about six weeks to complete our project, we ambitiously set out to replicate their results. We would take their methodology and apply it to our wet floor sign problem. Their methodology consisted of three main phases. Phase 1 would be to perform object detection on a frame inputted from the racing car’s camera and output the 2D location of the traffic cone. We specify 2D because it is important to note that detection of obstacles in an image frame consists not of two coordinates, but of three. In this first phase, the researchers from ETH Zurich were only concerned with the computation of the location of bounding boxes around the cone within the frame. The output of this model would provide a probability that the detected bounding box contains a cone and what the x- and y-coordinates of the bounding box were in the image frame. The neural network architecture employed by the researchers was the YoloV3 architecture. Additionally, the researches trained this network on 2,000 frames labelled with the bounding box coordinates around the cones. In the second phase of the paper, a neural network was trained to regress the location of key points of the cones. For instance, the input to this network was the cropped bounding box region of where a cone was in the frame. This cropped image was then labelled with ‘key points’, specific locations on the cone that the second neural network would be trained. From there, once we have at least four points on the cone, knowing the geometry of the cone and calibration of the camera, the perspective n-points can be used to find the 3D pose of the cone.
Using the research paper as our guidelines, we set out to replicate their results. First came building the dataset that would be used for training both of our neural networks. We needed a yellow wet floor sign so we took one from a bathroom in Rabb. Over the course of two weeks, we teleoperated a Turtlebot3 around various indoor environments, driving it into the yellow wet floor sign, recording the camera data. From there, we labelled over 2,000 frames, placing bounding boxes around the yellow wet floor sign. This was by far the most tedious process we faced. From there, we needed to find a way to train a neural network to generalize on new frames. Upon further research, we came across a GitHub repository that was an implementation of the Yolov3 architecture in Keras and Python. There was quite a bit of configuration but we eventually were able to clone the repository onto our local machines and pass our data through it. However, the passing of data through our network required a significant amount of computation, and hence, we encountered our first roadblock. Needing a computer with greater computational resources, we turned to the Google Cloud Platform. We created a new account and were given a trial $300 in cloud credits. We created a virtual machine that we added two P100 GPUs. Graphic processing units are processors specifically made for rendering graphics. Although we were not rendering graphics, GPUs are used to processing tensors and thus, would perform the tensor and matrix computations at each node of the neural network with greater speed than standard central processing units. Once we trained a model to recognize the yellow wet floor signs, we turned our attention over to the infrastructure side of our project. This decision to focus on incremental steps proved to be our best decision yet as this was the aspect of our project with the most amount of bottlenecks. When trying to create our program, we encountered several errors with using Keras in the ROS environment. Notorious to debug, there were several errors within the compilation and execution of the training of the neural network that were impossible to solve after a couple weeks of figuring it out. We pivoted once again, starting from scratch and training a new implementation of the Yolov3 architecture. However, this repository was written in Pytorch, an API for deep learning that was more compatible with the ROS environment.
Using Torch instead of Keras, we moved towards repositories and restarted training with our old dataset. In this particular pivot, we approximately ~500 frames from the old 2,000 frame dataset was relabeled in Pascal VOC format instead of YOLO weights format. This decision was made to make training easier on Jesse's GPU. To replicate our training of YOLO weights on a custom data set, we followed this process below:
Firstly, decide upon an annotation style for the dataset. We initially had annotations in YOLO formats and then in Pascal VOC formats. These are illustrated below.
Example Pascal VOC annotation
Each frame should have an accompanied annotation file. Example ('atrium.jpg' and 'atrium.xml'). Pascal VOC is in XML format, and should include the path, height, width, and channels for the image. In addition, there should be the class of the image in the name section, as well as any bounding boxes (including their respective x and y).
Example YOLO annotation
Similarly, each frame should have an accompanying text file. For example ('atrium.jpg' and 'atrium.txt'). These should also be in the same directory with the same name.
In this txt file, each line of the file should represent an object which an object number, and its coordinates in the image. As seen below in the form of:
line: object-class x y width height
The object class should be an integer that is represented on the names file that the training script shall read from. (0 - Dog, 1 - Cat, etc).
The x, y, width, and height, should be float values that are to the width and height of the image (these are floats between 0.0 and 1.0)
Training Configurations
As we were retraining weights from . It is here that one can find some of the pretrained weights for different YOLO implementations and their performance in mAP and FLOPS on the COCO dataset. The COCO dataset is a popular dataset for training in object detection and is called the Common Objects in Context dataset that includes over a quarter of a million images.
For our initial training, we used the YOLOv3-416 configuration and weights for 416 by 416 sized images, as well as the YOLOv3 tiny configuration and weights in the event of latency issues. Modifications were made in the yolov3.cfg file that we used for training for our single class inference.
Since we are doing single class detection our data and names file looks as so:
Fairly sparse as one can see, but easily modifiable in the event of training multiple class objects.
Actual training was done using the train.py script in our github repo. We played around with a couple hyper-parameters, but stuck with 25 epochs training in batch sizes of 16 on the 500 Pascal VOC labeled frames. Even with only 20 epochs, training on Jesse's slow GPU took approximately 20 hours.
Unfortunately, valuable data on our loss, recall, and precision were lost as laptop used to train unexpectedly died overnight during the training process. Lack of foresight resulted in not being able to collect these metrics during the training as they were to be conglomerated after every epoch finished. Luckily, the weights of 19 epochs were recovered in checkpoints however their performance had to be manually tested.
Prediction
Inference via the turtlebot3s are done via a ROS node on a laptop that subscribes to the turtlebot's rpi camera, does some minor image augmentations and then saves the image to a 'views' directory. From this directory, a YOLO runner program is checking for recently modified files, then subsequently performs inference, draws bounding box predictions on said files and then writes to a text file with results as well as the modified frame.
The rational behind reading and writing files instead of predicting on ROS nodes from the camera is a result of struggles throughout the semester to successfully integrate Tensorflow graphs onto the ROS system. We ran into numerous session problems with Keras implementations, and ultimately decided on moving nearly all of the processing from the turtlebot3 into the accompanying laptop. This allows us to (nearly) get inference real time given frames from the turtlebot3.
An alternate way of doing inference, but in this case doing object detection with items with the COCO dataset rather than our custom dataset can be run via our yolo_runner.py node directly on ROS. This is an approach that does not utilize read/write and instead prints predictions and bounding boxes to the screen. However, with this approach drawing to the screen was cut due to how it lagged the process when attempting to perform inference on the turtlebot3's frames.
This project was a strong lesson in the risks of attempting a large project in a short time span that combines two complex fields within computer science (Robotics and Machine Learning) whilst learning much of it on the go. It was quite humbling to be very ambitious with our project goals and fall short of many of the "exciting" parts of the project. However, it was also a pleasure to have the freedom to work on and learn continuously while attempting to deploy models and demos to some fairly cutting edge problems. Overall, this made the experience a learning experience that resulted in not only many hours of head-banging and lost progress but also a deeper appreciation for the application of computer vision in robotics and the challenges of those who helped pave the way for our own small success.
The two largest challenges in the project was data collection for our custom dataset and integration with ROS. That is, creating and annotating a custom dataset took longer than expected and we ran into trouble with training where our images were perhaps not distinct enough/did not cover enough environments for our weights to make sufficient progress. For integration, we ran into issues between python2 and python3, problems with integrating Keras with ROS, and other integration issues that greatly slowed the pace of the project. This made us realize that in the future, not to discount the work required for integration across platforms and frameworks.
References:
while not rospy.is_shutdown():
twist = Twist()
if fingers == '2':
twist.linear.x = 0.6
rospy.loginfo("driving forward")
elif fingers == '3':
twist.angular.z = 1
rospy.loginfo("turning left")
elif fingers =='4':
twist.angular.z = 1
rospy.loginfo("turning right")
else:
rospy.loginfo("stoped")
cmd_vel_pub.publish(twist)
rate.sleep() <annotation>
<folder>signs_images</folder>
<filename>atriuma2.jpg</filename>
<path>/Users/jesseyang/Desktop/signs_images/atriuma2.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>416</width>
<height>416</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>232</xmin>
<ymin>218</ymin>
<xmax>281</xmax>
<ymax>290</ymax>
</bndbox>
</object>
</annotation>1 0.716797 0.395833 0.216406 0.147222
0 0.687109 0.379167 0.255469 0.158333
1 0.420312 0.395833 0.140625 0.166667classes=1
train=data/signs/train.txt
valid=data/signs/val.txt
names=config/coco.names
backup=backup/sign





This still seems the best approach (if it ever worked). The Kinect camera was developed, at the first place,for human body gesture recognition and I could not think of any reason not using it but to reinvent wheels. However, since the library interfacing Kinect and ROS never worked and contains little documentation ( meaning it is very difficult to debug), I spent many sleepless nights and still wasn't able to get it working.However, for the next generation, I will still strongly recommend you give it a try.
ROS BY EXAMPLE V1 INDIGO: Chapter 10.9 contains detailed instructions on how to get the package openni_tracker working but make sure you install required drivers listed in chapter 10.3.1 before you start.
This semester I mainly worked on the hand gesture recognition feature. Honestly I spent most of the time learning new concepts and techniques because of my ignorance in this area. I tried several approaches (most of them failed) and I will briefly review them in terms of their robustness and reliability.
This project began as an effort to improve the localization capabilities of campus rover as an improvement to lidar based localization. Motivating its conception were the following issues: Upon startup, in order to localize the robot, the user must input a relatively accurate initial pose estimate. After moving around, if the initial estimate is good, the estimate should converge to the correct pose.
When this happens, this form of localization is excellent, however sometimes it does not converge, or begins to diverge, especially if unexpected forces act upon the robot, such as getting caught on obstacles, or being picked up. Furthermore, in the absence of identifiable geometry of terrain features, localization may converge to the wrong pose, as discussed in . While the article may discuss aerial vehicles, the issue is clearly common to SLAM.
One solution incolves fiducials, which are square grids of large black and white pixels, with a bounding box of black pixels that can be easily identified in images. The pattern of pixels on the fiducial encodes data, and from the geometry of the bounding box of pixels within an image we can calculate its pose with respect to the camera. So, by fixing unique fiducials at different places within the robot's operating environment, fixed locations can be used to feed the robot accurate pose estimates without the user needing to do so manually.
Fiducial SLAM is not a clearly defined algorithm. Not much is written on it specifically, but it is a sub-problem of SLAM, on which a plethora of papers have been written. In the authors discuss how Fiducial SLAM can be seen as a variation of Landmark SLAM. This broader algorithm extracts recognizable features from the environment and saves them as landmarks, which is difficult with changes in lighting, viewing landmarks from different angles, and choosing and maintaining the set of landmarks.
If successful, using landmarks should be allow the robot to quickly identify its pose in an environment. Fiducial SLAM provides a clear improvement in a controlled setting: fiducials can be recognized from a wide range of angles, and given that they are black and white, are hopefully more robust to lighting differences, with their main downside being that they must be manually placed around the area. Therefore, the goal of this project was to use fiducial markers to generate a map of known landmarks, then use them for localization around the lab area. It was unknown how accurate these estimates would be. If they were better than lidar data could achieve, fiducials would be used as the only pose estimation source, if not, they could be used simply as a correction mechanism.
This project uses the ROS package , which includes the packages aruco_detect and fiducial_slam. Additionally, something must publish the map_frame, for which I use the package turtlebot3/turtlebot3_navigation, which allows amcl to publish to map_frame, and also provide the utility of visualizing the localization and provide navigation goals.
I used the raspberry pi camera on the robots, recording 1280x960 footage at 10 fps. Setting the framerate too fast made the image transport slow, but running it slow may have introduced extra blur into the images. Ideally the camera is fixed to look directly upwards, but many of the lab's robots have adjustable camera angles. The transform I wrote assumes the robot in use has a fixed angle camera, which was at the time on Donatello.
To set up the environment for fiducial mapping, fiducials should be placed on the ceiling of the space. There is no special requirement to the numbering of the fiducials, but I used the dictionary of 5x5 fiducials, DICT_5X5_1000, which can be configured in the launch file. They do not need to be at regular intervals, but there should not be large areas without any fiducials in them. The robot should be always have multiple fiducials in view, unless it is pressed up against a wall, in which case this is obviously not practical. This is because having multiple fiducials in view at once provides a very direct way to observe the relative position of the fiducials, which fiducial_slam makes use of. Special attention should be made to make sure the fiducials are flat. If, for example, one is attached on top of a bump in the ceiling, it will change the geometry of the fiducial, and decrease the precision with which its pose, especially rotation, can be estimated by aruco_detect.
Before using the code, an accurate map generated from lidar data or direct measurements should be constructed. In our case we could use a floor plan of the lab, or use a map generated through SLAM. It does not matter, as long as it can be used to localize in with lidar. Once the map is saved, we can begin constructing a fiducial map. First, amcl should be running, to publish to map_frame. This allows us to transform between the robot and the map. We must also know the transform between the robot and the camera, which can be done with a static transform I wrote, rpicam_tf.py. aruco_detect provides the location of fiducials in the camera's frame. Then we run fiducial_slam, which can now determine fiducial's locations relative to the map_frame. We must pay special attention to the accuracy of amcl's localization while constructing the fiducial map. Although the purpose of this project is to prevent the need to worry about localization diverging, at this stage we need to make sure the localization is accurate, at least while the first few fiducials are located. The entire area should be explored, perhaps with teleop as I did.
The fiducial_slam package was clearly the most important part of this project, but after using it, I realize it was also the biggest problem with the project, so I am dedicating this section to discussing the drawbacks to using it and how to correct those, should anyone want to try to use fiducial SLAM in the future.
The package is very poorly documented. Its contains very little information on how it works, and how to run it, even if one follows the link provided. The information on how to run the packages at a very basic level is incomplete, since it does not specify that something must publish to map_frame for the packages to function.
The error messages provided are not very helpful. For example, when fiducial_slam and aruco_detect are run without amcl publishing to move base, they will both appear to work fine and show no errors, even though the rviz visualization will not show a camera feed. There is another error I received which I still have not solved. Upon launching the fiducial_slam package, it began crashing, and in the error message there was only a path to what I assume to be the source of the error, which was the camera_data argument, as well as a C++ error which related to creating an already existent file, with no information about which file that is. However, when I checked the camera_data argument, and even changed the file so I did not provide that parameter, the same error specifying a different path showed up. Note that upon initially trying to use the package, I did not specify the camera_data argument and this error did not appear, which suggests that parameter was not actually the problem. Issues like these are incredibly difficult to actually diagnose, making the use of the package much more challenging than it should be.
Code documentation is poor, and even now I am unsure which variety of SLAM the code uses. Compare to the previously mentioned on TagSLAM, which clearly indicates the algorithm uses a GTSAM nonlinear optimizer for graph-based slam. TagSLAM is a potential alternative to fiducial_slam, although as I have not tested its code, I can only analyze its documentation. I think TagSLAM would be much easier to use than fiducial_slam, or perhaps some other package I have not looked at. It may also be possible for a large team (at least three people) to implement the algorithm themselves.
The original learning goal of this project was for me to better understand how fiducial detection works, and how SLAM works. Instead, my time was mostly spent discovering how the fiducial_slam package works. My first major issue was when trying to follow the tutorial posted on the ROS wiki page. I wasn't given any error messages in the terminal window running fiducial_slam, but noticed that rviz was not receiving camera data, which I assumed indicated that the issue was with the camera.
After much toil and confusion, it turned out that for some reason, the data was not passed along unless something published to move_base. I did not originally try to run the packages with amcl running because I wrongly assumed that the package would work partially if not all parameters were provided, or at least it would give error messages if they were necessary. After solving that problem, I encountered an issue with the camera transforms, which I quickly figured out was that there was no transform between base_link and the camera. I solved this with a static transform publisher, which I later corrected when fiducial_slam allowed me to visualize where the robot thought observed fiducials were. Once I was mapping out fiducial locations, I believed that I could start applying the algorithm to solve other problems. However, overnight, my code stopped working in a way I'm still confused about. I do not remember making any modifications to the code, and am not sure if any TAs updates the campus rover code in that time in a way that could make my code break. After trying to run on multiple robots, the error code I kept getting was the fiducial_slam crashed, and that there was some file the code attempted to create, but already existed. Even after specifying new map files (which didn't yet exist) and tweaking parameters, I could not diagnose where the error was coming from, and my code didn't work after that.
In hindsight, I see that my problem was choosing the fiducial_slam package. I chose it because it worked with ArTag markers, which the lab was already using, and I assumed that would make it simpler to integrate it with any existing code, and I could receive help from TAs in recognizing fiducials with aruco_detect. Unfortunately that did not make up for the fact that the fiducial_slam package wasn't very useful. So one thing I learned from the project was to pick packages carefully, paying special attention to documentation. Perhaps a package works well, but a user might never know if they can't figure out what the errors that keep popping up are.
OpenCV
ROS Kinetic (Python 2.7 is required)
A Camera connected to your device
Copy this package into your workspace and run catkin_make.
Simply Run roslaunch gesture_teleop teleop.launch. A window showing real time video from your laptop webcam will be activated. Place your hand into the region of interest (the green box) and your robot will take actions based on the number of fingers you show.
This package contains two nodes.
detect.py: Recognize the number of fingers from webcam and publish a topic of type String stating the number of fingers. I won't get into details of the hand-gesture recognition algorithm. Basically, it extracts the hand in the region of insteret by background substraction and compute features to recognize the number of fingers.
teleop.py: Subscribe to detect.py and take actions based on the number of fingers seen.
Using Kinect on mutant instead of local webcam.
Furthermore, use depth camera to extract hand to get better quality images
Incorporate Skeleton tracking into this package to better localize hands (I am using region of insterests to localize hands, which is a bit dumb).
Three fingers: Turn left
Four fingers: Turn right
Other: Stop
while not rospy.is_shutdown():
twist = Twist()
if fingers == '2':
twist.linear.x = 0.6
rospy.loginfo("driving forward")
elif fingers == '3':
twist.angular.z = 1
rospy.loginfo("turning left")
elif fingers =='4':
twist.angular.z = 1
rospy.loginfo("turning right")
else:
rospy.loginfo("stoped")
cmd_vel_pub.publish(twist)
rate.sleep()





















In this project, we proposed to use deep learning methods to accomplish two tasks. 1. To navigate the robot throughout a racecourse using LIDAR data only and 2. To recognize certain signs (stop, go) and act accordingly. For the first objective, we implemented 2 deep reinforcement learning algorithms (Deep Deterministic Policy Gradient and Soft Actor-Critic) to try and learn to map LIDAR sensor data to appropriate actions (linear and angular velocities). We intended to train these algorithms on multiple simulated race tracks in the Gazebo simulation environment and if possible deploy the trained network on a real-world robot. For the second objective, we adapted existing computer vision models to recognize hazard signs like stop, yield, go, and caution. The last of our original objectives was to implement a facial recognition algorithm to work with the TurtleBot 3 architecture and hardware constraints.
Deep reinforcement learning is a family of techniques that utilizes deep neural networks to approximate either a state-action value function (mapping state-action pairs to values) or a state directly to action probabilities (known as policy-gradient methods). In this project, we implemented and tested two Deep RL algorithms. The first is the DDPG agent first proposed by DeepMind [^1]. To help in understanding and implementing this algorithm we also found a very helpful blog post [2] and associated PyTorch implementation of the DDPG agent. The second algorithm implemented was the Soft Actor-Critic agent proposed by Haarnoja et al. from the University of California Berkeley [3]. Again, a blog post was very helpful in understanding the agent and provided a PyTorch implementation [4].
The computer vision components, there was a mixture of GitHub repositories, Open-CV tutorials and a blog post posted on analyticsvidhya, written by Aman Goel. The analyticsvidhya blog post helped me to understand the facial_recognition library in python and how to properly implement it[5]. The GitHub repository that was used as a reference for the proof of concept implementation that was done on Mac OS was written by Adam Geitgey, who is the author of the facial recognition python library[6]. His Github repository along with his README helped me understand how the algorithm works and how to latter modify it within an ROS environment.
There was an assortment of ROS wiki articles used to troubleshoot and understand the errors that were occurring with OpenCV reading the data that was coming from the TurtleBot 3. The wiki articles lead me to the cv_bridege ROS package that can convert a ROS compressed image topic to an OpenCV format[7].
For the driving component of this project, the first step was to create a racetrack to simulate the robot on. To do this, I used Gazebo’s building editor to create a racecourse out of straight wall pieces (there are no default curved pieces in Gazebo). Creating the course (seen in Figure 1) involved saving a .sdf file from gazebo inside the turtlebot3_gazebo/models folder, a .worlds file in turtlebot3_gazebo/world, and a launch file in turtlebot3_gazebo/launch. The initial goal was to train the agent to drive counter-clockwise around the track as fast as possible. To do this, I implemented 5 types of nodes to carry out the different parts of the canonical RL loop (Figure 2) and manually chose 31 points around the track as “checkpoints” to monitor the robot’s progress within a training episode. How close the agent is to the next checkpoint is monitored from timestep to timestep and is used to compute the rewards used to train the agent.
This tracking of the robot’s ground truth position in the track is done by a node called GazeboListener.py which subscribes to Gazebo’s /gazebo/model_states topic. This node also requested reward values from a service called RewardServer.py every 100ms and published them to a topic called /current_reward. These rewards are the critical instructive component of the canonical RL loop as they instruct the agent as to which actions are good or bad in which situations. For this project, the “state” was the average of the past 5 LIDAR scans. This averaging was done in order to smooth out the relatively noisy LIDAR readings. The LIDAR smoothing was implemented by a node called scanAverager.py which subscribed to /scan and published to /averaged_scan.
To choose the actions, I made minor alterations to the PyTorch implementations of the DDPG or SAC agents given by [2,4]. This involved wrapping PyTorch neural network code in class files myRLclasses/models.py and myRLclasses/SACmodels.py. I then wrapped the logic for simulating these agents in the Gazebo track in a ROS node called RLMaster_multistart.py which handled action selection, sending cmd_vel commands, storing experience in the agent’s replay buffer, and resetting the robot’s position when a collision with a wall was detected (end of an episode). These collisions actually proved difficult to detect given the minimum range of the robot’s LIDAR (which is larger than the distance to the edge of the robot). Therefore I said there was a collision if 1) the minimum distance in the LIDAR scan was < .024M, 2) the actual velocity of the robot differed significantly (above a threshold) then the velocity sent to the robot (which in practice happened a lot), and 3) the actual velocity of the robot was less than .05M/s. This combination of criteria, in general, provided relatively robust collision detection and was implemented in a node called CollisionDetector.py.
Having implemented the necessary nodes, I then began training the robot to drive. My initial approach was to have every training episode start at the beginning of the track (having the episode ends when the robot crashed into a wall). However, I found that this caused the robot to overfit this first corner and be unable to learn to make the appropriate turn after this corner. Therefore, I switched to a strategy where the robot would start at a randomly chosen checkpoint for 10 consecutive episodes and then a different randomly chosen checkpoint would be used for the next 10 episodes and so on. This allowed the robot to gain experience with the whole track even if it struggled on particular parts of it. Every timestep, the current “state” (/averaged_scan) was fed into the “actor” network of the DDPG agent which would emit a 2D action (linear velocity and angular velocity). I would then clip the action values to be in the allowable range (-.22 - .22 for linear velocity and -.5 to .5 for angular velocity). Then, noise generated by an Ornstein-Uhlenbeck process would be added to these clipped actions. This added noise provides the exploration for the DDPG model. For the SAC agent, no noise is added to the actions as the SAC agent explicitly is designed to learn a stochastic policy (as opposed to the deep **deterministic **policy gradient). This noisy action would then be sent as cmd_vel commands to the robot. The subsequent timestep, a new state (scan) would be observed and the resulting reward from the prior timestep’s action would be computed. Then the prior scan, the chosen action, the subsequent scan, and the resulting reward would be pushed as an “experience tuple” into the DDPG agent’s memory replay buffer which is implemented as a deque. This replay buffer (stored in myRLclasses/utils.py) holds up to 500,000 such tuples to provide a large body of data for training. At the end of each timestep, a single batch update to all of the agent’s networks would be carried out, usually with a batch_size of 1024 experience tuples. Additionally, every 50 episodes I would do 1000 network updates and then save the agent as a .pkl file.
Finally, I wrote a node to allow a human to control the robot using teleop controls and save the experience in the agent’s replay buffer. This was in the hope that giving the agent experience generated by a human would accelerate the learning process. This was implemented by a node called StoreHumanData.py.
The facial recognition aspect of the RL Racer project took different python techniques and converted and optimized it to work with ROS. There is no launch file for this program. To run this program, you must first have the TurtleBot 3 and have brought up the camera software and have your facial_ recognition as the current directory in terminal. The command to run the code is as follows: $rosrun facial_recognition find_face.py
To do this we had to fundamentally rethink the program structure and methods for it to work. The first thing we had to contend with was the file structure while running the program through ROS, which you can see in figure 4 and figure 5. This was just a little quirk while working with ROS as compared to Python. While running the program you have to be directly in the Facial_recognition folder, anywhere else would result in a “file not found” error while trying to access the images. The Alternative to having to be in the folder for this to work, was to have all the images in the same “scripts” folder, which made for messy “Scripts” and made it confusing while adding new photos.
The steps for adding a photo are as simple as adding to the “face_pcitures” directory as shown figure 6. The image should have a clear view of the face you want the algorithm to recognize. The image does not have to be a giant picture of just a face. After you add an image to the file path you have to package you must call “load_image_file”, which will load the image. The next step is to encode the loaded image and find the face in the image. To do this you must all the “face_encodings” method in the facial_recognition package and pass the image you have loaded as an argument. After the images are added and encoded you add the facial encoding to a list and add the names to a list of names of type String of the people in the list in order. Since Luis is the first face that was added to the prior list, then it will be the first name in the list of names. This is the implementation of the node version of facial recognition that constantly publishes the names of faces that it finds, but there is also a service implementation.
The major difference between the service implementation is the segmentation of the image callback and image processing as you can see in figure 7. We keep track of the frame in a global variable called frame that can be later accessed. We also need the name of the person to be passed and we only process the next 20 frames and if we don’t see the person requested, we will send no. This also is reinforced with a suggested control request implementation.
The color recognition and control node came from a desire to define hazards. There was also a need to still follow other rules while training the neural net and to keep other factors in mind. This uses the basics of OpenCV to create color masks that you can put a specific RGB value you want to pick up. To run the program, you need to run python files in two separate windows. The first command is $ rosrun facial_ recognition racecar_signal.py The second command is: $ rosrun faical_recognition red_light_green_light.py. The racecar_signal node does all the image processing while the red_light_green_light node is a state machine that determines what to send over cmd_vel.
To add color ranges that you want to pick up you have to add the RGB ranges as NumPy arrays as seen in figure 8. After you manually add the RGB range or individual value you want to detect, you must create a find colors object based on the ranges. In this case, the ROS video image comes from the HSV variable. That was set whole converting the ROS Image to an OpenCV format.
The two deep RL algorithms tried were the Deep Deterministic Policy Gradient (DDPG) and Soft Actor-Critic (SAC) agents. The major difference between these methods is that the DDPG is deterministic, that is it outputs a single action every timestep, whereas the SAC agent outputs the parameters of a probability distribution from which an action is drawn. In addition, the DDPG agent is trained simply to maximize reward, whereas the SAC agent also tries to maximize the “entropy” of its policy. Simply, it balances maximizing reward with a predefined amount of exploration. For the first few weeks of the project, I exclusively tried training the DDPG agent by playing around with different hyperparameters such as noise magnitude and batch size as well as tuning the collision detection. I found that the agent was able to make significant progress and at one point completed two full laps of the track. However, after leaving the agent to train overnight, I returned to find that its performance had almost completely deteriorated and was mostly moving backward, clearly a terrible strategy. After doing a little more reading on the DDPG I found that it is an inherently unstable algorithm in that it is not guaranteed to continually improve. This prompted me to look for an alternative deep RL algorithm that was not so brittle. This search led me to the SAC algorithm which was specifically said to be more robust and sample efficient. I again implemented this agent with help from a blog post and started tuning parameters and found that it took longer (almost 3500 episodes) to show any significant learning however it seems to be maintaining its learning better. I am unsure what the problem with my current training method is for the DDPG agent and suspect the problem may just be due to the brittleness of the algorithm. One possible change that could help both agents would be to average over the LIDAR readings (within one scan) to reduce the dimensionality of the input (currently 360 inputs) to the networks which should help reduce learning complexity at the cost of lower spatial resolution. Finally, an interesting behavior produced by both robots was that during straight parts of the course, they learned a strategy of alternating between full left and full right turn instead of no turn at all. It will be interesting to see if this strategy gets worked out over time or is an artifact of the simulation environment
The facial_recognition package comes with a pre-built model that has a 99.38% accuracy rate and built-in methods for facial encoding and facial comparison[8]. The algorithm takes the facial encodings from loaded images that can be manually added a given script and uses landmarks to encode the pictures face. Using OpenCV we take the frames from a given camera, the algorithm finds the faces in the frame, encodes them, then compares the captured data facial encodings. One of the main challenges that I faced while trying to optimize the algorithm further resulted in failure because I could not figure out how to increase the processing time of facial recognition. This was mostly to do with my computer, but there was also a concern of wifi image loss or just slow wifi. Since ROS compressed image is just a published topic published, which relies on wifi. I got around this by manually dropping frames. I tried ROS each way at first limiting the queue and adding sleep functions, but it causes some problems when trying to implement this with other nodes. These methods would just throughout the frames it would still wait within a queue and still have to be processed. To get around these limitations I hardcoded a counter to only take 1 every 6 frames that come in and process it. It is not ideal but it works. The service implementation does something similar as I only want to a total of 24 processed frames, but still following the 1 out of 6 frame method. In total even though I am being sent (6*24) =144, I am only processing 24 frames, but this only occurs when the desired face is not in the frame.
The sign detection of RL racer was supposed to feature real signs detection, but We ran into a problem finding models of American sign or even when we did we could not get it to run. This is why we went the color route and because we could not train a model in time. The control nodes and the color detection nodes all work, but we were never able to implement it into the RL racer because it took longer than expected to train racer. The theory of color detection is that we can mimic signs by using specific RGB values that we want the robot to pick up. So, Green would be Go, Red would be stopped, and Yellow would be a cushion. Obviously, this is to mimic traffic signals.
This project was very interesting and a lot of fun to work on, even though we had to pivot a few times in order to have a finished product. However, we still learned a lot and worked well together always talking, even though we had two distinct parts we wanted to get done in order to come together. Unfortunately, we could not bring everything together that we wanted we still accomplished a lot.
We were disappointed to learn just how unstable the DDPG agent was after initial success but are hopeful that the now operational SAC agent will be able to accomplish the task with more training.
The problem that my facial recognition aspect has is that you have to be within 3 feet for an algorithm to reliably tell who you are or if there is a face on screen. I tried a few things with resizing the image or even try to send uncompressed image topics, but it did not work. An interesting solution that we tried was if we can tell that there was a face there, but now who it was we could take the bounding box of the unknown face, cut it out because we knew where it was on the image, then zoom in. This approach did not work because the image was too low quality.
We both did a good job of accomplishing what we wanted to, even though we had to pivot a few times. We believe that the code we implemented could be used in further projects. The deep RL code could be used to learn to drive around pre-gazeboed maps with some adaptation and the general method could be applied anywhere continuous control is needed. The facial recognition algorithm can be easily added to the code base of Campus Rover for package delivery authentication and any other facial recognition applications.
:
:
[1]: Lillicrap et al., 2015. Continuous control with deep reinforcement learning https://arxiv.org/pdf/1509.02971.pdf
[2]: Chris Yoon. Deep Deterministic Policy Gradients Explained. https://towardsdatascience.com/deep-deterministic-policy-gradients-explained-2d94655a9b7b
[3]: Haarnoja et al., 2018. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. https://arxiv.org/abs/1801.01290
[4]: Vaishak V. Kumar. Soft Actor-Critic Demystified. https://towardsdatascience.com/soft-actor-critic-demystified-b8427df61665
[5]: Blog, Guest. “A Simple Introduction to Facial Recognition (with Python Codes).” Analytics Vidhya, May 7, 2019. https://www.analyticsvidhya.com/blog/2018/08/a-simple-introduction-to-facial-recognition-with-python-codes/.
[6]: Geitgey, Adam, Facial Recognition, GitHub Repository https://github.com/ageitgey/face_recognition
[7]: “Wiki.” ros.org. Accessed December 13, 2019. http://wiki.ros.org/cv_bridge/Tutorials/UsingCvBridgeToConvertBetweenROSImagesAndOpenCVImages.
[8]: PyPI. (2019). face_recognition. [online] Available at: https://pypi.org/project/face_recognition/ [Accessed 16 Dec. 2019].
The final approach I took was deep learning. I used a pre-trained SSD (Single Shot multibox Detector) model to recongnize hands. The model was trained on the Egohands Dataset, which contains 4800 hand-labeled JPEG files (720x1280px). Code can be found here
Raw images from the robot’s camera are sent to another local device where the SSD model can be applied to recognize hands within those images. A filtering method was also applied to only recognize hands that are close enough to the camera.
After processing raw images from the robot, a message (hands recognized or not) will be sent to the State Manager. The robot will take corresponding actions based on messages received.
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy,Scott E. Reed, Cheng-Yang Fu, and Alexander C. Berg. SSD: single shot multibox detector. CoRR, abs/1512.02325, 2015. Victor Dibia, Real-time Hand-Detection using Neural Networks (SSD) on Tensorflow, (2017), GitHub repository,
The current society considers robots as a crucial element. It is because they have substituted human beings concerning the daily functions, which could be dangerous or essential. Therefore, the designation of an effective technique of navigation for robots that can achieve mobility as well as making sure that they are secure is the crucial considerations related to autonomous robotics. The report, therefore, addresses the pathfinding in robots using A-Star Algorithm, Wavefront Algorithm, as well as using Reinforcement Learning. The primary aim of path planning in robotics is to establish safe paths for the robots that can achieve mobility. The preparation of routes in robotics should achieve optimality. These algorithms target the development of strategies that are intended to provide solutions to problems like the ability of a robot to detect the distance between objects that causes obstructions, techniques of evading the obstacles, as well as how to achieve mobility between two elements of blockage in the shortest possible path. Moreover, the project is meant to help in coming up with the shortest route, if possible, that the Robot can use to reach the destination.
When carrying out the project, there were a lot of resources, even though some were not directly addressing the issues, and I was able to get numerous information that helped in connecting the points and getting the right idea. Apart from the readily available internet sources, I as well-referred to several related papers, Professor Sutton's book, and Professor David Silver's lecture.
A two-dimensional environment where the robot training was to be undertaken was created. The atmosphere was made in such a way that for the Robot to finds its path from location A to B, there are several obstacles, destructions, and walls that would hinder it from getting to the destination. The result would be to identify how the Robot would meander through the barriers to reach the desired position. A robot sensor was used to help the robot to perceive the environment. To determine the best way of path determination, the following criteria were utilized, A star Algorithm and Wavefront Algorithm and Reinforcement Learning.
The technique is a crucial way of traversal of graphs and pathfinding. It has brains, unlike other traversal strategies and algorithms. The method can be efficiently adopted into ensuring that the shortest path is efficiently established. It is regarded as one of the most successful search algorithms, which are the best to be used to find the most concise way in the graphs and notes. The Algorithm uses heuristics to find the solution paths as well as the information concerning the path cost to come up with the best and shortest route. In this project, the use of the A-star Algorithm would be necessary for that it would help in the determination of the shortest path that can be used by the Robot to reach the destination. In working places or any other environment, we always look for the shortest routes which we can use to reach the target. The Robot was designed using this Algorithm, which helps in the productive interaction with the environment to find out the best paths that can be used to reach the destination. An example of an equation that shows this form algorithm is f(n) = g(n) + h(n) in which f(n) is the lowest cost in the node, g(n) is the exact cost of the path and h(n) the heuristic estimated cost from a node.
Path MAP
To make it more efficient and more tactical, the wavefront algorithm was utilized to help in determining the correct path that can be used by the Robot to reach the destination effectively. This type of Algorithm is regarded as a cell decomposition path method. When the workplace paths are divided into equal segments, getting the right paths can always be an issue; however, using this Algorithm will help to come up with the correct way that can easily use by the Robot in reaching the destination. The method uses the breadth-first search based on the position in which the target is. The nodes in this method are increasingly assigned values from the target note. At sometimes, the modified wavefront algorithm would be suggested in future research to come up with the best estimate of the path that is needed to be followed. The improved version of the system as well uses the notes; nevertheless, it provides for the most accurate results. In this project, for the remote censored Robot to find the correct path to reach the target faster, the wavefront algorithm was utilized.
In the allocation of the nodes, the following equation holds
Map (i,j) = {min (neighborhood (i j)) + 4 [empty diagonal cell]/ min (neighborhood (i j)) + 3 other empty cell obstacle cell]
The equation in shows the allocation of the nodes with reference to the coordinates (i,j). The algorithm thus provides a solution if it exists incompleteness and provides the best solution.
Path MAP
To ensure that the Robot is adequately trained on the environment to determine the best path that can quickly and faster lead to the target, a deep reinforcement algorithm will be necessary. The reinforcement algorithm will, therefore, be the component that will majorly control the Robot in the environment. For instance, the Algorithm will be planted on the Robot to help in avoiding the obstructions such that when the Robot is about to hit an obstacle, it will quickly sense the obstacle and change the direction but leading to the target. Moreover, deep learning with help the Robot to get used to the environment of operation. It is said that the Robot is as well able to master the path through the deep learning inclusions. Still and moving obstacles can only be determined and evaded by the Robot through the use of deep learning, which can help the Robot to recognize the objects. In general, one way to make the Robot to find the path of operating effectively and to work in the environment effectively is to involve deep learning in this operation. To improve the artificial intelligence of the system, a deep learning algorithm will be of importance.
𝑄ˆ(𝑠, 𝑎) = (1 − 𝛼𝑡). 𝑄ˆ(𝑠, 𝑎) + 𝛼𝑡(𝑟 + 𝛾 max 𝑎 ′ 𝑄ˆ(𝑠 ′ , 𝑎′ ))
Figure portrays the single target fortification learning system. Where the specialist, spoke to by an oval, is in the state (s) at time step (t). The operator plays out the activity-dependent on the Q-esteem. The earth gets this activity, and accordingly, it restores the following states' to the operator and a comparing reward (r) for making a move (a).
Path MAP
Training Result Difference between Learning Rate
Learning Rate = 0.0001, Batch Size = 200
Best Model
Learning Rate = 0.0002, Batch Size = 200
Learning Rate = 0.0003, Batch Size = 200
Learning Rate = 0.0004, Batch Size = 200
In most cases, in a system which is a bit complex, the deep reinforcement learning may not be the best option but, one can decide to go by the deep double q learning which is embedded by Q-matrix which is being advanced to help in finding the paths in very complicated places. Moreover, when the Robot is to be operated in a large environment, it may take time for the deep reinforcement learning to help in getting the correct codes; thus, the use of double Q learning should be an option. It is in this manner recommended that in the next projects, there can be the use of this system to get more harmonized results.
𝑉 𝜋 (𝑠) = 𝐸{ ∑︁∞ 𝑘=0 𝛾 𝑘 𝑟𝑡+𝑘+1|𝑠𝑡 = 𝑠}
As opposed to Q learning, the Double Q learning equation is vectorial functions.
The figure portrays the multi-objective reinforcements support learning structure. Like the single goal RL system, in MORL structure, the operator is spoken to by an oval and is in the state (s) at time step (t). The specialist makes a move dependent on the accessible Q-values. The earth gets this activity, and accordingly, it restores the following state s' to the specialist.
In the early days, there were many concerns about how to proceed with this project. I wanted to study how to find something new rather than simply applying an existing path algorithm to the robot. I also considered a model called GAN, but decided to implement reinforcement learning, realizing that it was impossible to generate as many path images as to train GAN. The biggest problem with implementing reinforcement learning was computing power. Reinforcement learning caused the computer's memory to soar to 100 percent and crash. I tried and ran several options, but to no avail, I decided to reinstall Ubuntu. After the reinstallation, I don't know why, but it's no longer to a computer crash due to a sharp rise in memory. Currently, even with a lot of repetitive learning, it does not exceed 10% of memory.
Another problem with reinforcement learning was the difficulty in adjusting hyperparameters. Since reinforcement learning is a model that is highly influenced by hyperparameters, it was necessary to make fine adjustments to maximize performance. Initially, the code did not include grid search, but added a grid search function to compare hyperparameters. It took about six hours to get around 500 epochs, so I didn't experiment with a huge variety of hyperparameters. However, after three consecutive weeks of training, I found the best performing hyperparameters.
The third problem with reinforcement learning was that the results of learning were not very satisfactory. According to various papers, existing Deep Q Learning can be overestimate because same Q is used. Therefore, although it has not been fully applied to the code yet, I will apply Double Q Learning and Dueling Network in the near future.
In conclusion, it gets imperative to note the issue of path findings in the intelligence machine has been long in existence. Nevertheless, through these methods, the correct paths can be gotten, which is short but can help the Robot in reaching the target.
Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529.
Mnih, Volodymyr, et al. "Playing atari with deep reinforcement learning." arXiv preprint arXiv:1312.5602 (2013). https://arxiv.org/abs/1312.5602
Nuin, Yue Leire Erro, et al. "ROS2Learn: a reinforcement learning framework for ROS 2." arXiv preprint arXiv:1903.06282 (2019). https://arxiv.org/abs/1903.06282
Van Hasselt, Hado, Arthur Guez, and David Silver. "Deep reinforcement learning with double q-learning." Thirtieth AAAI conference on artificial intelligence. 2016. https://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/viewPaper/12389





















In Kinect.md, the previous generations dicussed the prospects and limitations of using a Kinect camera. We attempted to use the new Kinect camera v2, which was released in 2014.
Thus, we used the libfreenect2 package to download all the appropiate files to get the raw image output on our Windows. The following link includes instructions on how to install it all properly onto a Linux OS.
https://github.com/OpenKinect/libfreenect2
We ran into a lot of issues whilst trying to install the drivers, and it took about two weeks to even get the libfreenect2 drivers to work. The driver is able to support RGB image transfer, IR and depth image transfer, and registration of RGB and depth images. Here were some essential steps in debugging, and recommendations if you have the ideal hardware set up:
Even though it says optional, I say download OpenCL, under the "Other" option to correspond to Ubuntu 18.04+
If your PC has a Nvidia GPU, even better, I think that's the main reason I got libfreenect to work on my laptop as I had a GPU that was powerful enough to support depth processing (which was one of the main issues)
Be sure to install CUDA for your Nvidia GPU
Please look through this for common errors:
https://github.com/OpenKinect/libfreenect2/wiki/Troubleshooting
Although we got libfreenect2 to work and got the classifier model to locally work, we were unable to connect the two together. What this meant is that although we could use already saved PNGs that we found via a Kaggle database (that our pre-trained model used) and have the ML model process those gestures, we could not get the live, raw input of depth images from the kinect camera. We kept running into errors, especially an import error that could not read the freenect module. I think it is a solvable bug if there was time to explore it, so I also believe it should continued to be looked at.
However, also fair warning that it is difficult to mount on the campus rover, so I would just be aware of all the drawbacks with the kinect before choosing that as the primary hardware.
https://www.kaggle.com/gti-upm/leapgestrecog/data
https://github.com/filipefborba/HandRecognition/blob/master/project3/project3.ipynb
What this model predicts: Predicted Thumb Down Predicted Palm (H), Predicted L, Predicted Fist (H), Predicted Fist (V), Predicted Thumbs up, Predicted Index, Predicted OK, Predicted Palm (V), Predicted C
https://github.com/campusrover/gesture_recognition
Install OpenNI2 if possible
Make sure you build in the right location

Cosi 119a - Autonomous Robotics
Team: Stalkerbot
Team members: Danbing Chen, Maxwell Hunsinger
Github Repository: https://github.com/campusrover/stalkerbot
Final Report
In the recent years, the pace of development of autonomous robotics has quickened, due to the increase in demand for robots which perform actions in the absence of human control and minimal human surveillance. The robots are through the years more capable of performing an ever-various range of tasks, and one such task, which has become more prevalence in the capabilities of modern robots, is the ability to follow a person. Robots which are capable of following people are widely deployed and used for caretaking and assistance purposes.
Although the premise of a person-follow algorithm is simple, in practice the algorithm must consider several complexities and challenges, some of which depend on the general purpose of such said robots, and some of which are due to the inherent complication of the practice of robotics.
Stalkerbot is an algorithm which detects and follows the targeted individual until the robot has reached a certain distance within the target, which then it will stop. Although the algorithm has the capability to detect and avoid obstacles, it does not operate well in a spatially crowded environment where the room for robotic maneuver is limited. The algorithm works well only in an environment with enough light exposure; hence it will not function properly or at all in the darkness.
One of the most basic and perhaps fundamental challenge of such algorithm is the recognition of the targeted person. The ability of the algorithm to quickly and accurately identify and focus on the target is crucial, as it is closely linked to most of the other parts of the algorithm, which may include path finding, obstacle avoidance, motion detect, etc.
Although there are sophisticated methods of recognizing the potential target, including 3D Point Clouds and convoluted computer vision algorithms, our project will only be using a rather simple library in rospy called the Aruco Detect, which is a fiducial marker detection library which can detect and identify specific markers using a camera and return the pose and transformation of the fiducial. We chose to use the library because it is simple to implement and does not involve sophisticated and heavy computation such as machine learning, with, of course, the downside of the algorithm’s having dependency on fiducial marker as well as the library.
We will be using SLAM for local mapping of the robot, which takes in lidar data and generate the map of its immediate surroundings. We will also be using ros_navigation package, or more specifically, the move_base module in the package to facilitate the path finding algorithm of Stalkerbot. It is important to note that these two packages make up most of the computational consumption of the algorithm, as the rest of the generic scripts written in Python are standard, light-weight ROS nodes.
Sensors are the foundation of every robotics application, they are to bridge the gap between the digital world and the real world, they give perception to robots and allow them to respond to the changes in the real world, therefore it is not surprising that the other defining characteristics of a path finding algorithm is its sensors.
The sensors which we use for our algorithm are the lidar and the raspberry-pi camera. Camera will be used to detect the target via the aforementioned Aruco Detect library. We will support the detection algorithm with sensor data from the lidar which is equipped on the Turtlebot. These data will be used to map the surroundings of the robot in real time and play an important part in the path planning algorithm, which will enable the robot to detect and avoid obstacles on the path to the target.
On the Turtlebot3, the camera will be installed in the front at an inclination of about 35 degrees upwards and the lidar is installed at around 10cm above the ground level. These premises are important factors in the consideration of the design of the algorithm, and they often ease or pose limitations on the design space of the algorithm. In addition, the Turtlebot runs on Raspberry-pi 3 board. The board is adequate for running simple programming scripts; however, they are not fit to run computationally heavy script such as Aruco Detect or SLAM, therefore, these programs have to be run remotely and the data will have to be communicated to the robots wirelessly.
The very first design choice which we must consider is this: Where does the robot go? The question might sound simple, or even silly, because the goal of the algorithm is to follow a person, so the target of the robot must be the person which it follows. However, it is important to remember that the robot does not reach the target, instead it follows the target up to a certain distance behind the target, therefore a second likely choice for which where the robot should aim to move to is the point which is at said distance behind the target.
The two different approaches translate to two very different behaviors of the robots, for example, a direct following approach reacts minimally to the target’s sudden change in rotation, whereas the indirect following approach reacts more drastically to it. It should be said that under different situations one might be better than the other. If the target simply rotates but does not turn, for example, then by using the direct approach the robot would stand still, however, if the target intends to rotate, then the indirect approach helps more adequately to better prepare for the change of course preemptively than the direct approach.
We have chosen the direct approach in the development of Stalkerbot, because even though the indirect approach is often the more advantageous approach in many situations, it has a severe drawback that is associated with how the camera is mounted on the robot. For example, when the target turns, the robot must move side-ways, and since its wheels are not omnidirectional, but bidirectional, the robot must turn to move to the appropriate spot, and in term lose sight of the target in the process, because the robot can only detect what is in front of it, since the camera is mounted directly ahead of the robot, and no additional camera is mounted on the robot. The continuous update of the state of the target is crucial in the algorithm, and the lack of the information on the target is unjustifiable, hence the indirect approach is not considered.
Fiducial markers can be identified by their unique barcode-like patterns, and each is assigned an identification number. We only want to identify specific fiducial markers. The reason which we want to do this is this: there are other projects, including the campus_rover_3, who are using the same library as we do, and we do not wish to confuse the robots with the fiducials from other projects. All the accepted fiducials are stored as their identification number in an array in the configuration file. The node fiducial_filter filters out unwanted fiducial markers and republishes those that match against the fiducial markers whose identification number is in the configuration file.
It is important to ensure that the robot follows the target in a smooth manner. However, the detection capability with the camera which is mounted on the robot is not perfect. Although Aruco Detect can detect the fiducial markers, it is awfully inconsistent, and the detection rate drops significantly with distance, with the marker becoming almost impossible to detect at any distance farther than 2.5 meters. At normal range, it is expected that the algorithm will miss certain frames. To ensure the smoothness of the robot’s motor movement, a buffer time is introduced to the follow algorithm to take the momentary loss of information on the state of the target into account. If the robot is unable to detect any fiducial marker within this buffer duration, it will keep moving as if the target is still at the place when it is last detected, however when the robot is still unable to detect any markers after that grace period, the robot will stop. We have found that 200 milliseconds to be an appropriate time, with which the robot will run smoothly even if the detection algorithm does not.
These algorithms are contained in the advanced_follow node, which is also where all of the motion algorithms lie. This node is responsible for how the robot reacts to the change in the sensor data, therefore, this node can be seen as the core of the person-following algorithm. The details of this node will be explained further later in this section.
In order to compare the time elapsed since the robot has last recognized a fiducial marker and the current time, we have created a ROS node called fiducial_interval, which measures the time since the last fiducial marker is detected. Note that when the algorithm first starts, and no fiducial is detected, the node will publish nothing. Only when the first fiducial marker is detected, then the node will be activated and start to publish the duration.
Aruco Detect publishes the information on the fiducial markers which the robot detects, however, to extract and filter the important data (pose, mainly), and to filter the unwanted data (timestamp, id, fiducial size, error rate, etc), we have created a custom node called location_pub, which subscribes to fiducial_filter and publishes only the important information which will be useful for the Stalkerbot algorithm.
One of the biggest components of Stalkerbot is its communication with the ros_tf package. The package is a powerful library that aligns the locations and orientations of different objects that have coordinates on different coordinate frames. In Stalkerbot, we feed information of the relationship between two frames into ros_tf and we also extract those data from it. We require this because it is otherwise difficult to understand and calculate the pose of an object from, for example, the robot, when the data is gathered by the camera, which uses a different coordinate system, or frame, as the robot.
The node location_pub_tf publishes to ros_tf the pose of an object as perceived by another object. In the node, two different relationships are transmitted to ros_tf. Firstly, the node broadcasts a static pose of the camera from the robot. The pose is static because the camera is mounted on the robot and the pose between them will not change during the execution and runtime of Stalkerbot. Because it is a static broadcast, the pose is sent to ros_tf once, at the beginning of the algorithm, via a special broadcast object that specifies this broadcast is static. Furthermore, the node will, at a certain frequency, listen to the topic /stalkerbot/fiducial/transform and broadcast the pose of the target with respective to the frame of the camera to ros_tf. Note that, just like the node fiducial_interval, nothing will be broadcasted before the detection of the first fiducial marker.
Like mentioned before, not only do we broadcast the coordinates to ros_tf, we also request them from it as well. In fact, the only place where we request for any coordinates between two objects is in the advanced_follow node. The advanced follow node uses, additionally, the move_base module from ros_nav, however, to send a goal to the module requires the algorithm to have the coordinate frame between the frame map and target. Therefore, at a certain frequency, the node requests the pose between map and target from ros_tf. When the robot reaches the destination and the target is not in motion for a certain number of seconds, the follow algorithm will shut itself down. The detection of motion is contained in the motion_detect node. This is an algorithm just as complicated as the follow algorithm. It listens to the ros_tf transform between the robot and the target and calculate the distance from the pose of the current frame to the last known frame. However, most of the logic issued in this node is to enable the algorithm to recognize motion and the lack of motion in the presence of sensory noise. It uses average mean and a fluctuating distance threshold level to determine whether the object is moving at any given moment.
The node also implements a lingering algorithm which has a counter which counts down when the rest of the algorithm returns false and reverts the response to positive. When the counter reaches zero, it is no longer able to revert any negative response. The counter is reset when a fiducial marker is detected. This is again a method to combat the inconsistency of Aruco Detect, you can think of the counter as the minimal number of times the algorithm will return true. However, during the development stage, this method is not used anymore. The counter is specified to 0 according to the configuration file. Similar to fiducial_filter, it also has its corresponding interval node, motion_interval, which returns the time since the last time when the target is in motion.
Lastly, Stalkerbot also implements a special node called sigint_catcher, in which the node only activates when the program is terminated via KeyboardInterrupt. The only purpose of this node is to send an empty cmd_vel to roscore, thereby stopping the robot.
The inspiration for this project is a crowdfunding project that was initiated by a company called "Cowarobot", which aims to create the world's first auto-following suitcase/luggage. This project is a scaled-down version of this project. Initially, we had great ambitions for the project; we had plans to use facial recognition and machine learning to recognize the target which the robot follows, however, it is soon clear to us that given our expertise, the time which we have, and the scale of the problem, we have to scale down the ambition of the project as well. At the end of the project proposal period, we have made a very conservative model for our project – A robot follows a person wearing the fiducial marker in an open, obstacle-free environment, and we are glad to say that we have achieved this very basic goal and some more.
Over the course of the few weeks which we spent working on Stalkerbot, there arose numerous challenges, most of them were the result of our lack of deep understanding of ROS and robotic hardware. The two biggest challenge were the following: The inconsistency of the camera and Aruco Detect was our first big obstacle. We followed the lab instruction on how to enable the camera on the robot, however, for our project, a custom exposure mode is needed to improve the performance of the camera, and it took us some time to figure out how the camera should exactly be correctly configurated. However, over the course of the entire development of Stalkerbot, Aruco Detect sometimes cannot pick up on the fiducial markers. Sometimes, it is unable to detect any markers altogether at certain specific camera settings.
The second challenge is the ros_tf library, and in general how orientation and pose function in the 3D world. At the beginning of the algorithm development, we did not have to deal with poses and orientations, but when we had to deal with them, we realized the poses and orientations we thought were aligned were all over the place. It turned out, that the axes used by Aruco Detect and ros_tf were different. The x axis in ros_tf is the y axis in Aruco Detect, for example. In addition, communicating with ros_tf requires a good understanding of the package as well as spatial orientation. There are many pitfalls, such as mixing the target frame and the child frame, mixing up the map frame and the odom frame.
Over the course of the development, Danbing worked on the basic follow algorithm, fiducial_filter, fiducial_interval, motion_detect, detect_interval, and sigint_catcher. Max worked on location_pub, move_base_follow and the integration of move_base_follow to make advanced_follow.